Hubungi kami 0815 9696 995 atau 0877 8467 3150 dan Email [email protected] untuk jasa pengolahan data statistik - olah data SPSS, Eviews, AMOS, Lisrel dan Smart PLS untuk skripsi, tesis dan disertasi atau untuk penelitian terapan di perusahaan dan kementerian. Analisis data statistik dan konsultasi oleh Dosen Senior Statistik di Program Doktor Ilmu Ekonomi. Simak komentar lebih dari 1237 orang klien di: bit.ly/testim0ny

Prosedur lengkap Analisis Regresi Linier Berganda menggunakan SPSS tertera pada link di bawah ini. Prosedur analisis lainnya tertera pada beberapa video pada bagian bawah.
Berikut ini dibahas dengan tuntas analisis Regresi Linier Berganda dan olah data kuesioner menggunakan SPSS
Yang akan dibahas dalam tulisan ini adalah contoh model penelitian menggunakan dua variabel independen dan sebuah variabel dependen. Variabel independen atau variabel bebas (X) yang menyebabkan perubahan pada variabel dependen dalam penelitian ini yaitu :
- Kualitas Produk (X1) : Adalah segala sesuatu yang dapat ditawarkan ke pasar untuk mendapatkan perhatian, dibeli, dipergunakan, atau dikonsumsi dan dapat yang dapat memuaskan keinginan atau kebutuhan
- Layanan (X2) : tingkat layanan yang berhubungan dengan terpenuhinya harapan dan kebutuhan pelanggan atau penggunanya
- Variabel dependen atau variabel terikat (Y) yang dipengaruhi oleh variabel independen dalam penelitian ini yaitu : Kepuasan Konsumen (Y) tingkat perasaan konsumen setelah membandingkan antara apa yang dia terima dan harapannya
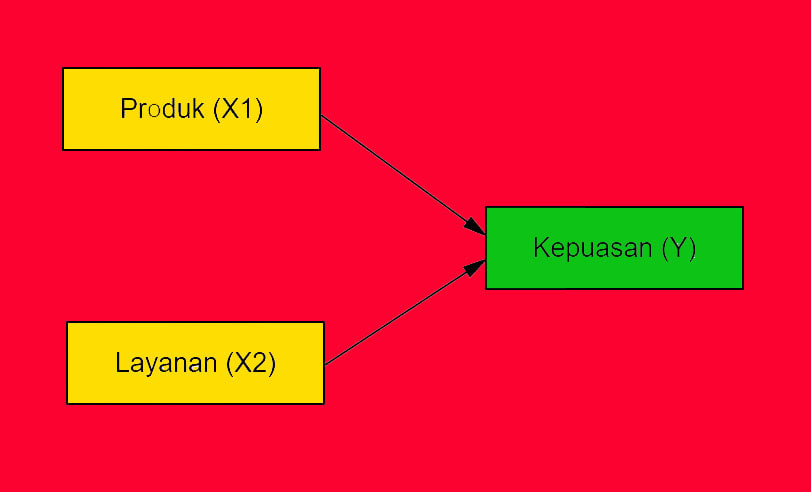
Dalam upaya menjawab permasalahan dalam penelitian ini maka digunakan analisis regresi linear berganda (Multiple Regression). Analisis regresi linear berganda digunakan untuk menganalisis pengaruh antara variabel independen yaitu kesadaran merek dan loyalitas merek terhadap keputusan pembelian. Rumus matematis dari regresi linear berganda yang diganakan dalam penelitian ini adalah :
Y = a + b1X1 + b2X2 + e
Keterangan :
Y = Kepuasan ( variabel dependen )
X1 = Produk ( variabel independen )
X2 = Layanan ( variabel independen )
a = Konstanta
b1 = Koefisien regresi variabel Produk
b2 = Koefisien regresi variabel Layanan
Skala likert digunakan untuk mengukur jawaban pada pertanyaan utama mengenai pengaruh Produk dan Layanan terhadap Kepuasan. Skala likert merupakan skala yang dipakai untuk mengukur sikap, pendapat, dan persepsi seseorang/sekelompok orang tentang fenomena sosial (Sugiyono, 2001). Skala ini banyak digunakan karena mudah dibuat, bebas memasukkan pernyataan yang relevan, realibilitas yang tinggi dan aplikatif pada berbagai aplikasi. Penelitian ini mengunakan sejumlah statement dengan 5 skala yang menunjukkan setuju atau tidak setuju terhadap statement tersebut.
1 = sangat tidak setuju
2 = tidak setuju
3 = netral (ragu-ragu)
4 = setuju
5 = sangat setuju
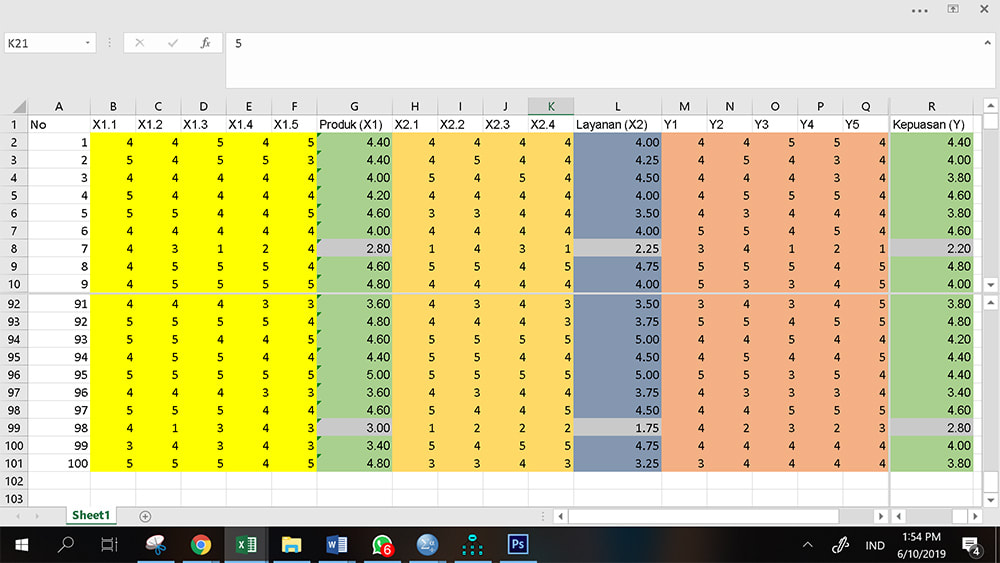
X1 diukur menggunakan kuesioner dengan 5 indikator, X2 menggunanakan 4 indikator dan Y menggunakan 5 indikator. Responden dalam contoh ini adalah 100 orang. Data hasil kompilasi dalam bentuk file excel setelah penyebaran kuesioner seperti tertera pada gambar di bawah ini, dan data bisa diunduh di sini, data dalam excel dan SPSS.
Y = a + b1X1 + b2X2 + e
Keterangan :
Y = Kepuasan ( variabel dependen )
X1 = Produk ( variabel independen )
X2 = Layanan ( variabel independen )
a = Konstanta
b1 = Koefisien regresi variabel Produk
b2 = Koefisien regresi variabel Layanan
Skala likert digunakan untuk mengukur jawaban pada pertanyaan utama mengenai pengaruh Produk dan Layanan terhadap Kepuasan. Skala likert merupakan skala yang dipakai untuk mengukur sikap, pendapat, dan persepsi seseorang/sekelompok orang tentang fenomena sosial (Sugiyono, 2001). Skala ini banyak digunakan karena mudah dibuat, bebas memasukkan pernyataan yang relevan, realibilitas yang tinggi dan aplikatif pada berbagai aplikasi. Penelitian ini mengunakan sejumlah statement dengan 5 skala yang menunjukkan setuju atau tidak setuju terhadap statement tersebut.
1 = sangat tidak setuju
2 = tidak setuju
3 = netral (ragu-ragu)
4 = setuju
5 = sangat setuju
X1 diukur menggunakan kuesioner dengan 5 indikator, X2 menggunanakan 4 indikator dan Y menggunakan 5 indikator. Responden dalam contoh ini adalah 100 orang. Data hasil kompilasi dalam bentuk file excel setelah penyebaran kuesioner seperti tertera pada gambar di bawah ini, dan data bisa diunduh di sini, data dalam excel dan SPSS.
|
| ||||
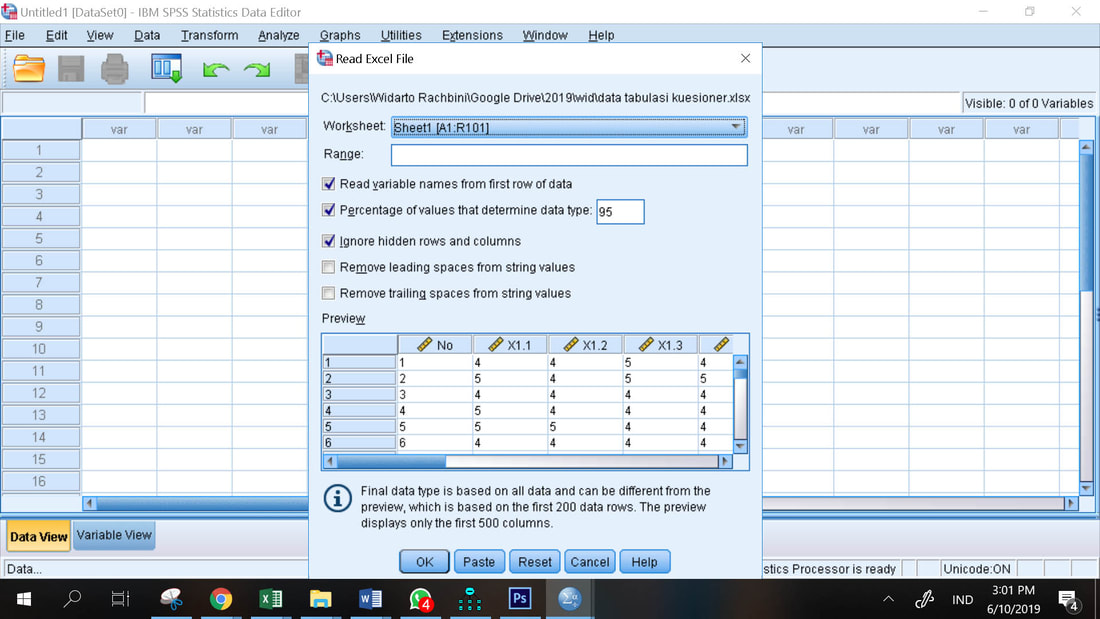
Hal pertama yang harus dilakukan adalah mengimpor data dalam bentuk excel menjadi data dalam bentuk SPSS. Pastikan bahwa baris pertama dari data excel adalah nama indikator dan atau nama variabel. Hapus semua infomasi yang ada di atas nama indikator dan nama variabel. Pastikan juga bahwa data pertama dimulai dari baris kedua dan setelah data terakhir tidak ada infomasi apapun. Untuk bisa diimpor ke dalam SPSS, file excel harus dalam kondisi tertutup.
Prosedur mengimpor data ke dalam SPSS:
1. File - open data, lalu masuk ke folder dimana file excel disimpan
2. Ubah File of type dari *.sav menjadi Excel agar data bisa ditampilkan
3. Pilih data excel yang akan diimpor
4. Open, pastikan Pilihan Read variable names from first row of data, dicentang
5. OK
Data untuk olah data SPSS dan dalam bentuk file SPSS (SAV), bisa didownload di bawah ini
Prosedur mengimpor data ke dalam SPSS:
1. File - open data, lalu masuk ke folder dimana file excel disimpan
2. Ubah File of type dari *.sav menjadi Excel agar data bisa ditampilkan
3. Pilih data excel yang akan diimpor
4. Open, pastikan Pilihan Read variable names from first row of data, dicentang
5. OK
Data untuk olah data SPSS dan dalam bentuk file SPSS (SAV), bisa didownload di bawah ini
| data_regresi_linier_berganda.sav |
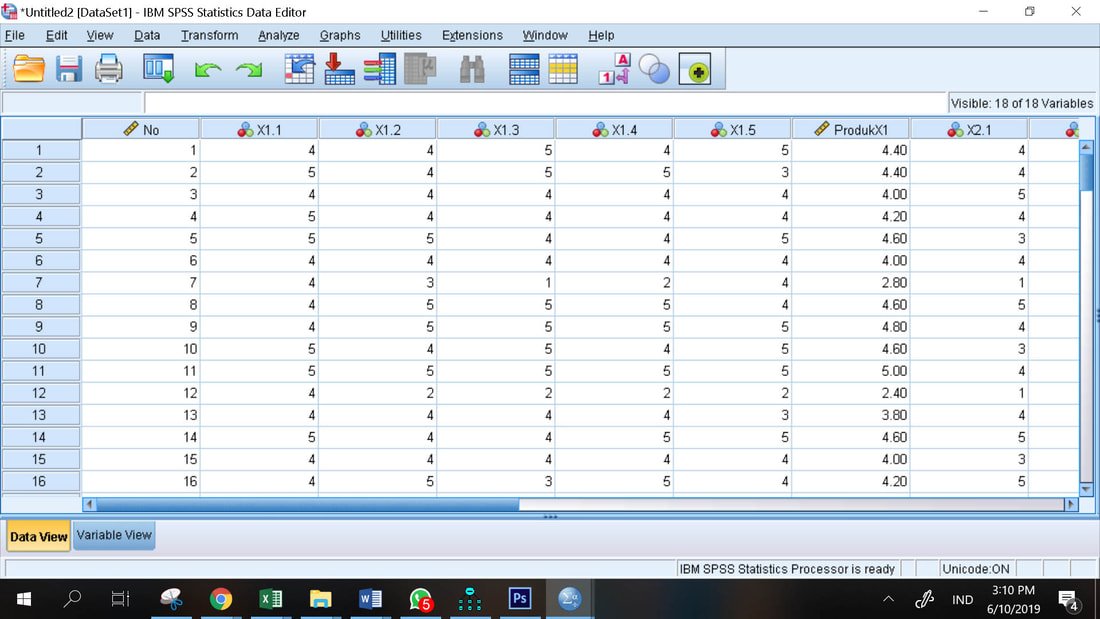
Tampilan data dalam bentuk kuesioner SPSS seperti tertera pada gambar di bawah ini
Video berikut ini penjelasan cara mengimpor data dari excel ke SPSS
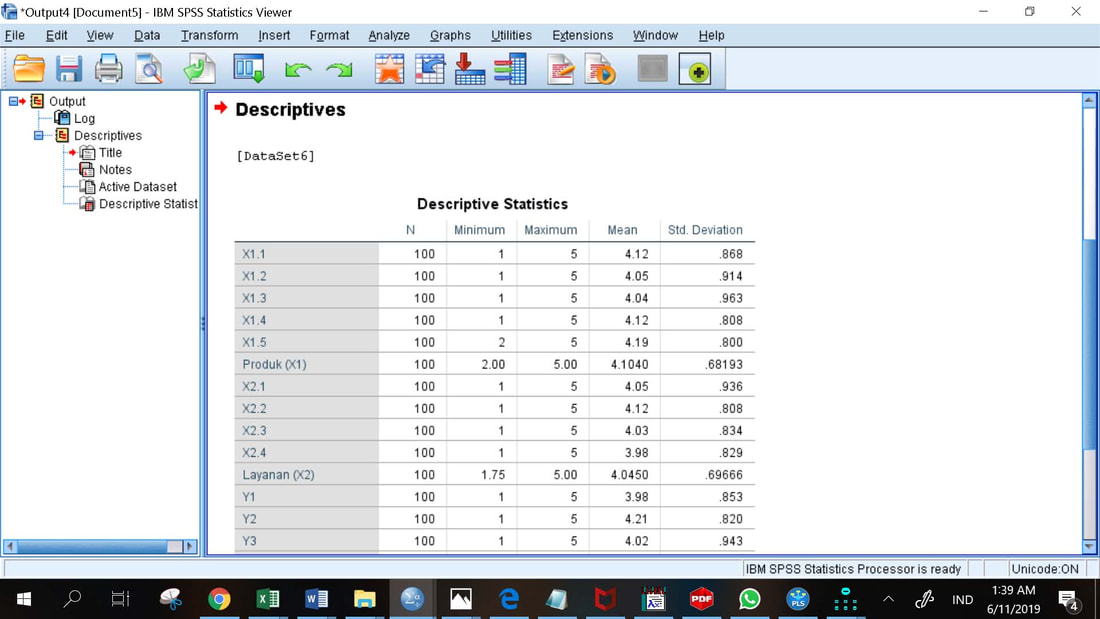
Statistik Deskriptif memberikan gambaran atau deskripsi data hasil sebaran kuesioner terhadap 100 responden yang dilihat dari nilai rata-rata (mean), standar deviasi, maksimum, minimum.
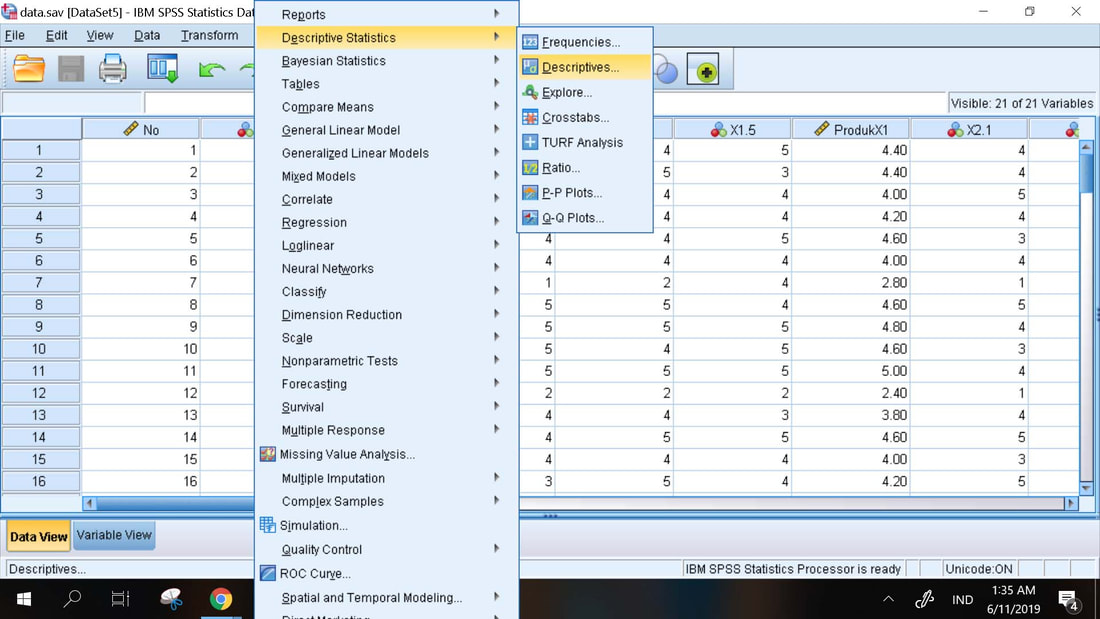
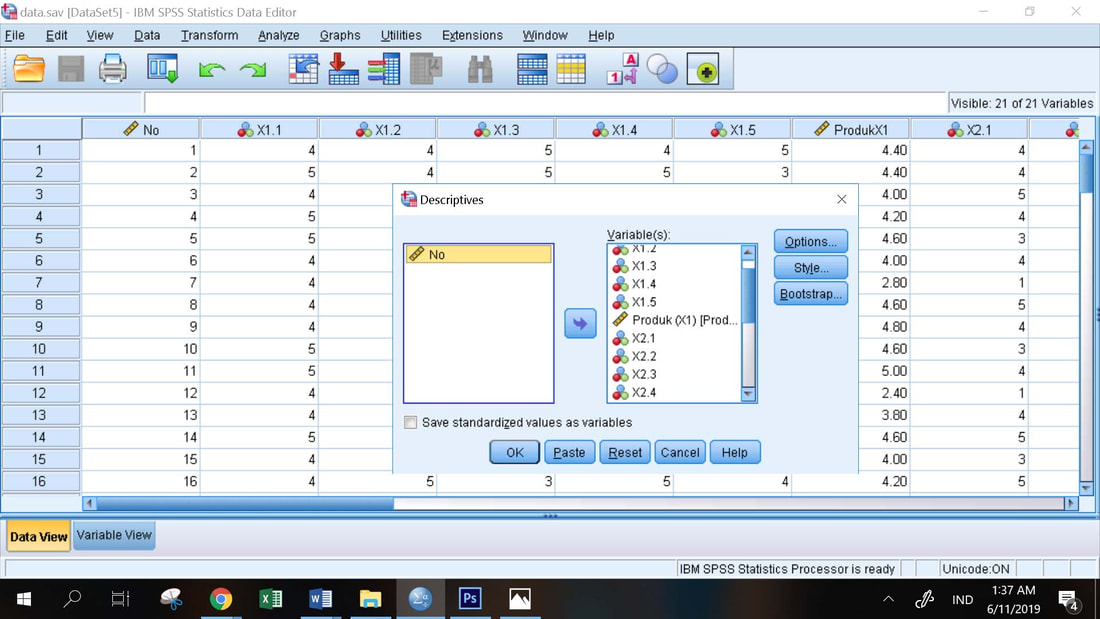
Prosedur Statistik Deskriptif :
1. Analyze, Descriptives
2. Masukkan semua indikator dan variabel ke dalam kotak Variables
3. OK
Prosedur Statistik Deskriptif :
1. Analyze, Descriptives
2. Masukkan semua indikator dan variabel ke dalam kotak Variables
3. OK
Uji validitas
Uji validitas konstruk dilakukan untuk mengukur sah atau valid tidaknya suatu kuesioner. Suatu kuesioner dikatakan valid jika pertanyaan kuesioner mampu untuk mengungkapkan sesuatu yang akan diukur oleh kuesioner tersebut. Uji signikansi dilakukan dengan membandingkan r hitung dengan r tabel atau membandingkan nilai p atau sig dengan level of significance (biasanya = 0.05). Jika r hitung lebih besar dari r tabel atau nilai p atau sig < 0.05, maka pernyataan tersebut valid.
Uji Reliabilitas
Reliabilitas adalah indeks yang menunjukkan sejauh mana suatu alat pengukur dapat dipercaya atau dapat diandalkan atau menunjukkan konsistensi suatu alat pengukur di dalam mengukur gejala yang sama.
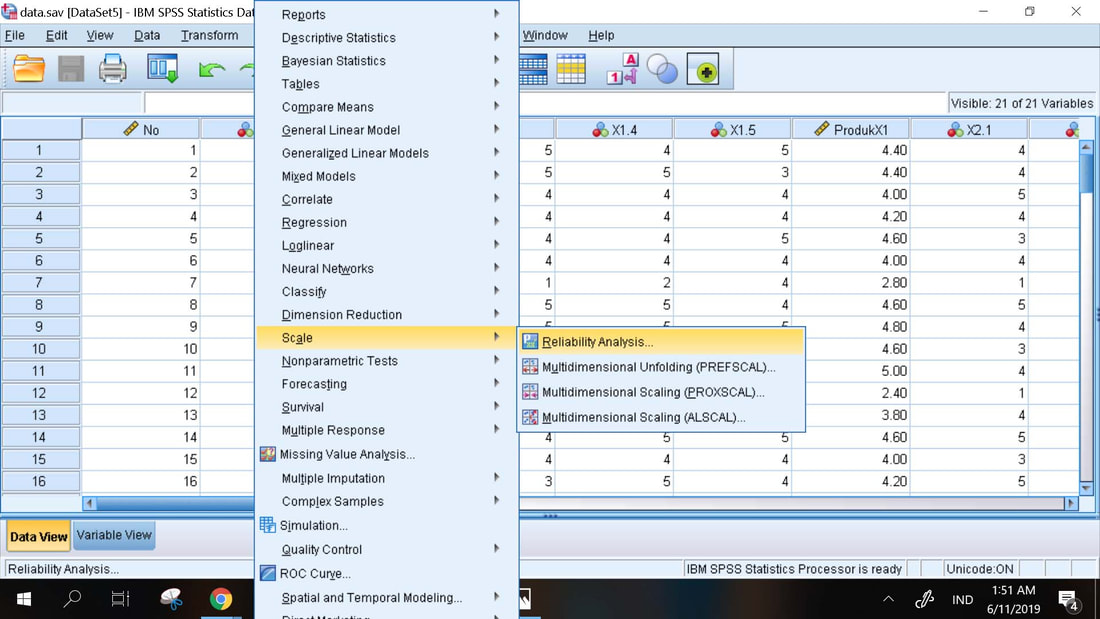
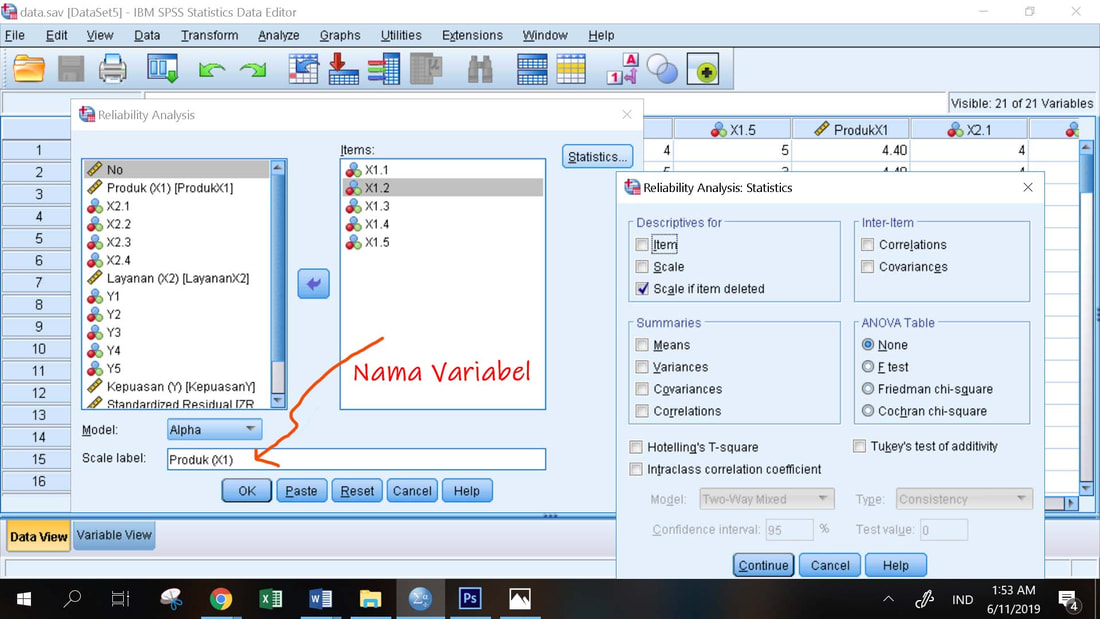
Prosedur Uji Validitas dan Reliabilitas :
1. Analyze, Scale, Reliability Analysis
2. Masukkan semua indikator dari variabel yang akan diuji ke dalam kotak
3. Statistics, dan centang Scale if Item Deleted
4. Continue, Isi kotak untuk nama variabel (tidak wajib), OK
Untuk menguji apakah sebuah indikator valid untuk mengukur konstruk atau variabelnya, maka bandingkan nilai r hitung dengan r tabel.
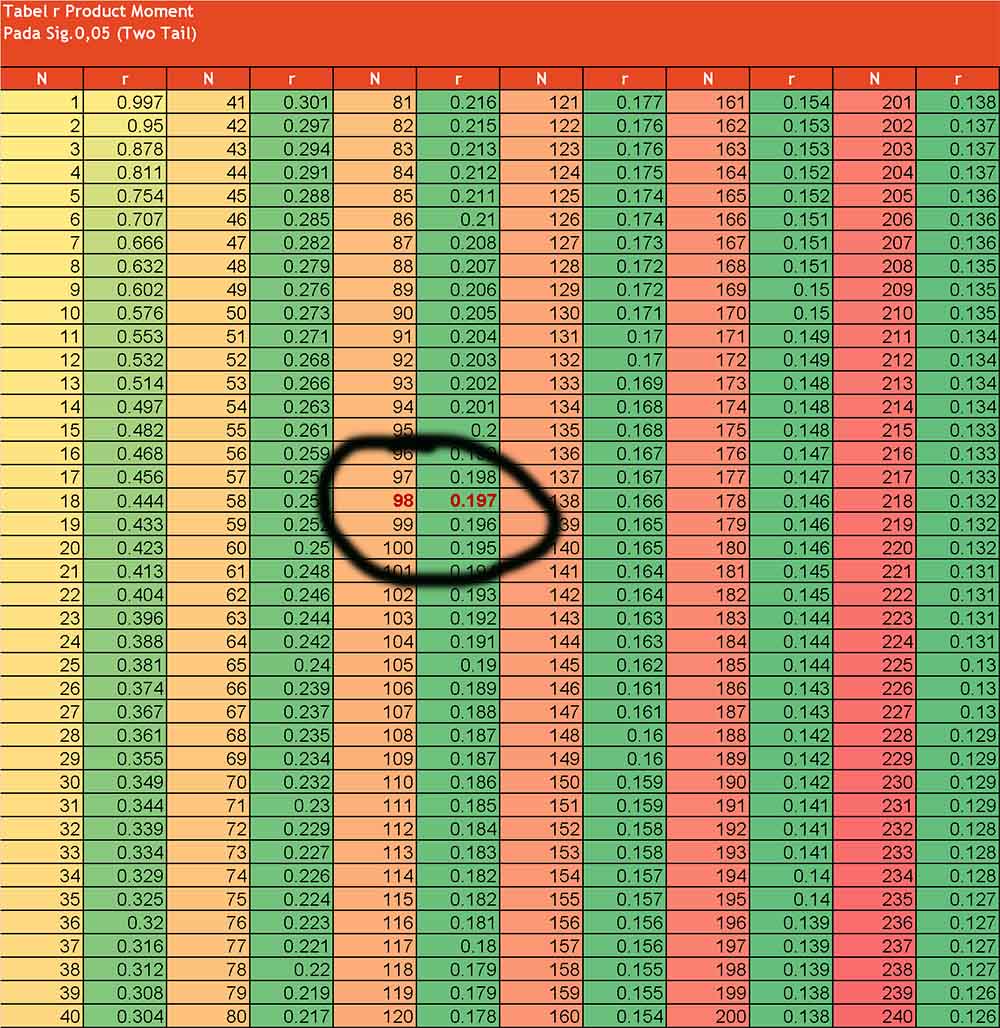
Cara menggunakan Tabel R
Untuk tahu bagaimana cara menggunakan tabel r kita pakai contoh berikut:
Kita meneliti dengan menggunakan sampel untuk uji kuesioner sebanyak n=100 orang responden dengan signifikansi 5%, dari sini didapatkan nilai df=n-2, df=100-2=98. Cara membaca tabel r nya, kita lihat tabel r product moment pada signifikansi 5%, didapatkan angka r tabel= 0.197. Selanjutnya kita hitung dan bandingkan nilai r yang di dapat dari tabel r dengan r hasil perhitungan. Jika r di tabel r < r hasil hitung, maka pernyataan itu valid.
Tabel r di atas menunjukkan nilai r untuk jumlah data (n) tertentu. Pada penelitian ini data yang digunakan berjumlah n=100, sehingga nilai r table adalah 0.197
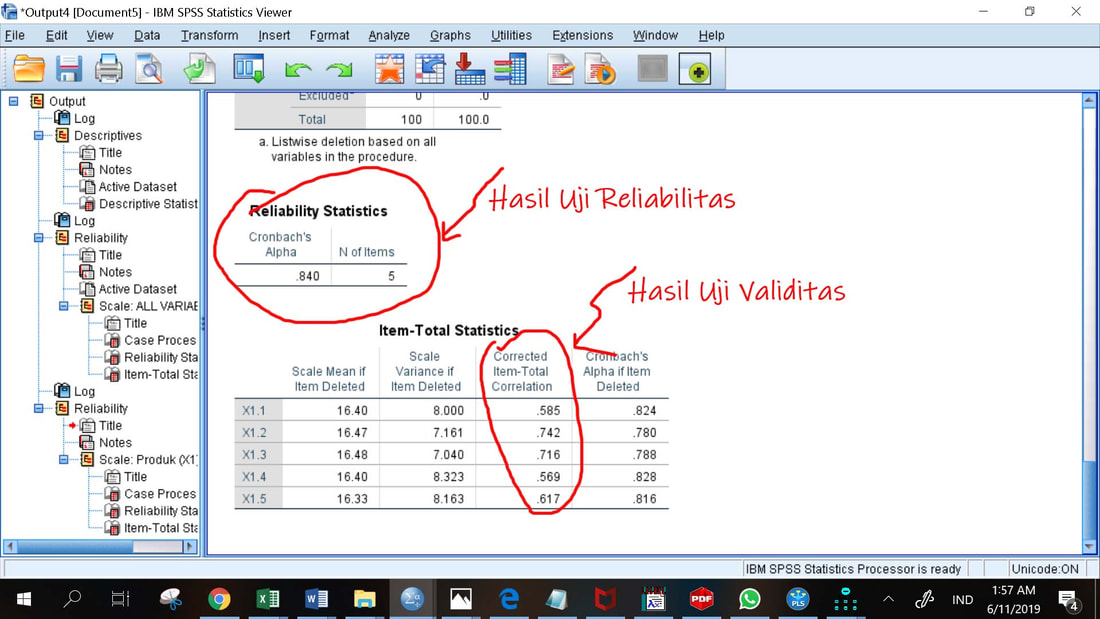
Pada tabel hasil uji validitas di atas , nilai r hitung (Corrected Item Total Correlation) indikator X1.1 = 0.585 > r table (0.197) , maka disimpulkan bahwa indikator X1.1 dinyatakan valid untuk digunakan sebagai alat ukur variabel. Nilai r hitung (Corrected Item Total Correlation) indikator X1.2 = 0.742> r table (0.197) , maka disimpulkan bahwa indikator X1.2 dinyatakan valid untuk digunakan sebagai alat ukur variabel, demikian juga nilai r hitung (Corrected Item Total Correlation) indikator-indikator lainnya semuanya > 0.197, berarti valid. Bila ada indikator yang tidak valid, maka indikator tersebut harus dihapus.
Hasil perhitungan uji reliabilitas di atas menunjukkan bahwa instrumen untuk X1 memiliki angka reliabilitas yang sangat tinggi (Cronbach’s Alpha = 0.850), karena menurut Nunnaly (1967) dan Hinkle (2004) ataupun indeks yang biasa digunakan dalam penelitian sosial, apabila angka Cronbach’s Alpha (α) diatas 0.60 menunjukkan bahwa konstruk atau variabel adalah reliabel.
Uji reliabilitas dan validitas variabel X2 dan Y dilakukan dengan cara yang sama dengan cara di atas, dan tidak dijelaskan lagi di sini. Hasilnya uji instrumen untuk X2 dan Y reliabel dan semua indikator untuk X2 dan Y, valid.
Video berikut ini menjelaskan uji reliabilitas
Untuk tahu bagaimana cara menggunakan tabel r kita pakai contoh berikut:
Kita meneliti dengan menggunakan sampel untuk uji kuesioner sebanyak n=100 orang responden dengan signifikansi 5%, dari sini didapatkan nilai df=n-2, df=100-2=98. Cara membaca tabel r nya, kita lihat tabel r product moment pada signifikansi 5%, didapatkan angka r tabel= 0.197. Selanjutnya kita hitung dan bandingkan nilai r yang di dapat dari tabel r dengan r hasil perhitungan. Jika r di tabel r < r hasil hitung, maka pernyataan itu valid.
Tabel r di atas menunjukkan nilai r untuk jumlah data (n) tertentu. Pada penelitian ini data yang digunakan berjumlah n=100, sehingga nilai r table adalah 0.197
Pada tabel hasil uji validitas di atas , nilai r hitung (Corrected Item Total Correlation) indikator X1.1 = 0.585 > r table (0.197) , maka disimpulkan bahwa indikator X1.1 dinyatakan valid untuk digunakan sebagai alat ukur variabel. Nilai r hitung (Corrected Item Total Correlation) indikator X1.2 = 0.742> r table (0.197) , maka disimpulkan bahwa indikator X1.2 dinyatakan valid untuk digunakan sebagai alat ukur variabel, demikian juga nilai r hitung (Corrected Item Total Correlation) indikator-indikator lainnya semuanya > 0.197, berarti valid. Bila ada indikator yang tidak valid, maka indikator tersebut harus dihapus.
Hasil perhitungan uji reliabilitas di atas menunjukkan bahwa instrumen untuk X1 memiliki angka reliabilitas yang sangat tinggi (Cronbach’s Alpha = 0.850), karena menurut Nunnaly (1967) dan Hinkle (2004) ataupun indeks yang biasa digunakan dalam penelitian sosial, apabila angka Cronbach’s Alpha (α) diatas 0.60 menunjukkan bahwa konstruk atau variabel adalah reliabel.
Uji reliabilitas dan validitas variabel X2 dan Y dilakukan dengan cara yang sama dengan cara di atas, dan tidak dijelaskan lagi di sini. Hasilnya uji instrumen untuk X2 dan Y reliabel dan semua indikator untuk X2 dan Y, valid.
Video berikut ini menjelaskan uji reliabilitas
Analisis Korelasi
Kuat lemahnya hubungan dua variabel ditunjukkan oleh nilai Pearson Correlation (R) dimana nilai secara umum dibagi menjadi sbb:
0.00 – 0.25 : korelasi sangat lemah
0.25 – 0.50 : korelasi moderat
0.50 – 0.75 : korelasi kuat
0.75 – 1.00 : korelasi sangat kuat
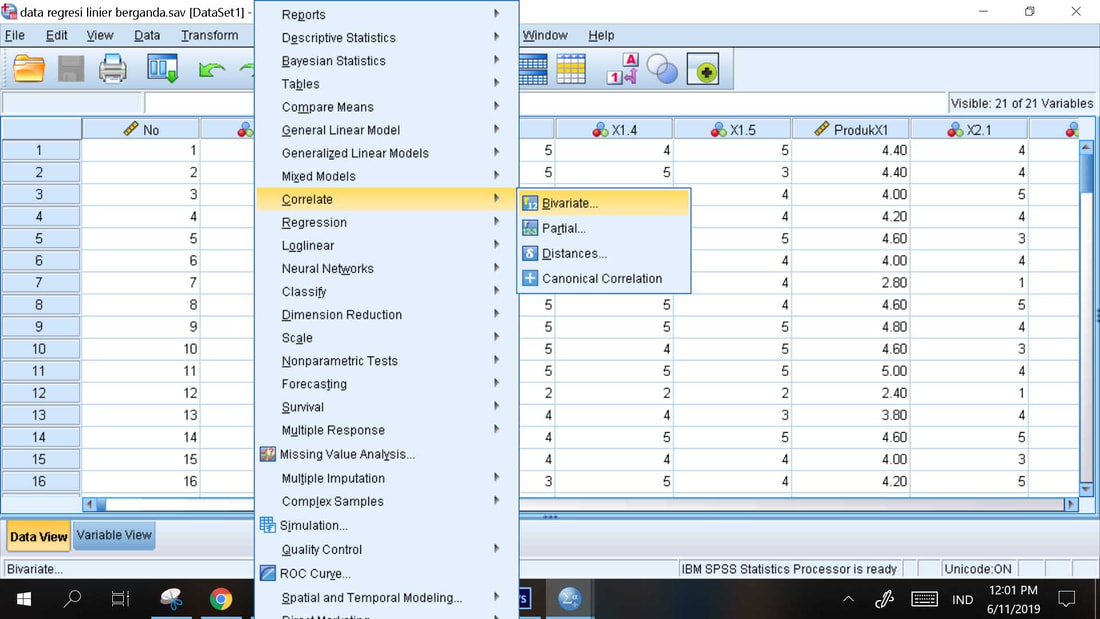
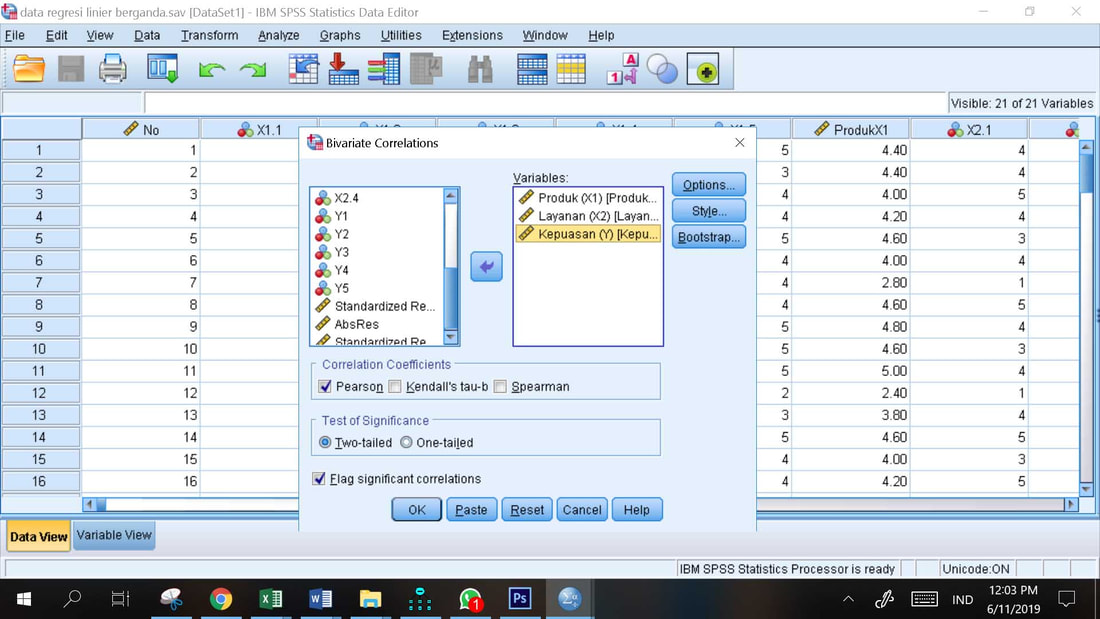
Prosedur Analisi Korelasi:
1. Analyze, Correlate, Bivariate
2. Masukkan variabel X1, X2 dan Y yang akan dikorelasikan ke dalam kotak tersedia
3. OK
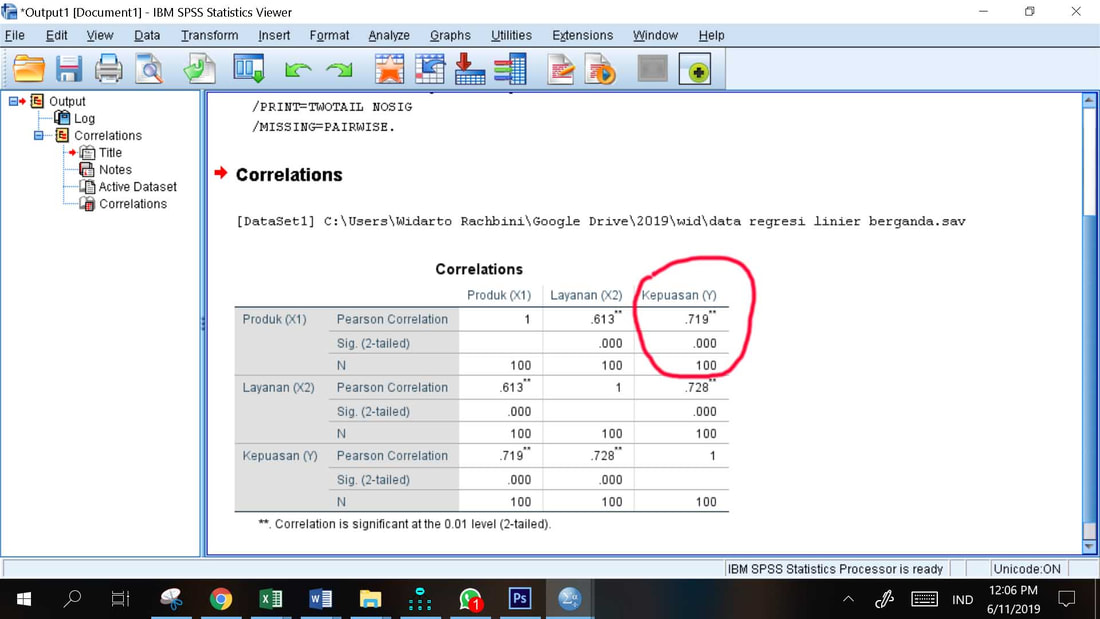
Hasil analisis korelasi tercantum pada gambar berikut ini
Hipotesis:
H0: Tidak ada korelasi yang nyata antara X1 dan Y
H1: Ada korelasi yang nyata antara X1 dan Y
Dasar Pengambilan Keputusan
Jika probalitasnya (nilai sig) > 0.05 maka H0 tidak ditolak
Jika probalitasnya (nilai sig) < 0.05 maka H0 ditolak
Keputusan:
Pada tabel di atas, nilai sig = 0. < 0.05 à H0 ditolak, yang berarti ada korelasi positif yang nyata antara X1 dan Y. Koefisen korelasi R = 0. menunjukkan tingkat hubungan kedua variabel pada tingkat sangat kuat moderat untuk skala 0 – 1. Tanda **) pada nilai R menunjukkan bahwa korelasi tersebut nyata pada taraf nyata (level of significance) 0.01.
Analisis korelasi variable lainnya menggunakan cara yang sama di atas. Video berikut ini menjelaskan teori analisis korelasi
H0: Tidak ada korelasi yang nyata antara X1 dan Y
H1: Ada korelasi yang nyata antara X1 dan Y
Dasar Pengambilan Keputusan
Jika probalitasnya (nilai sig) > 0.05 maka H0 tidak ditolak
Jika probalitasnya (nilai sig) < 0.05 maka H0 ditolak
Keputusan:
Pada tabel di atas, nilai sig = 0. < 0.05 à H0 ditolak, yang berarti ada korelasi positif yang nyata antara X1 dan Y. Koefisen korelasi R = 0. menunjukkan tingkat hubungan kedua variabel pada tingkat sangat kuat moderat untuk skala 0 – 1. Tanda **) pada nilai R menunjukkan bahwa korelasi tersebut nyata pada taraf nyata (level of significance) 0.01.
Analisis korelasi variable lainnya menggunakan cara yang sama di atas. Video berikut ini menjelaskan teori analisis korelasi
Regresi linier berganda adalah bentuk paling umum dari analisis regresi linier. Sebagai sebuah alat analisis untuk memprediksi, regresi linier berganda digunakan untuk menjelaskan hubungan antara satu variabel dependen kontinu dan dua atau lebih variabel independen. Variabel independen dapat kontinu atau kategorikal (dummy diberi kode yang sesuai).
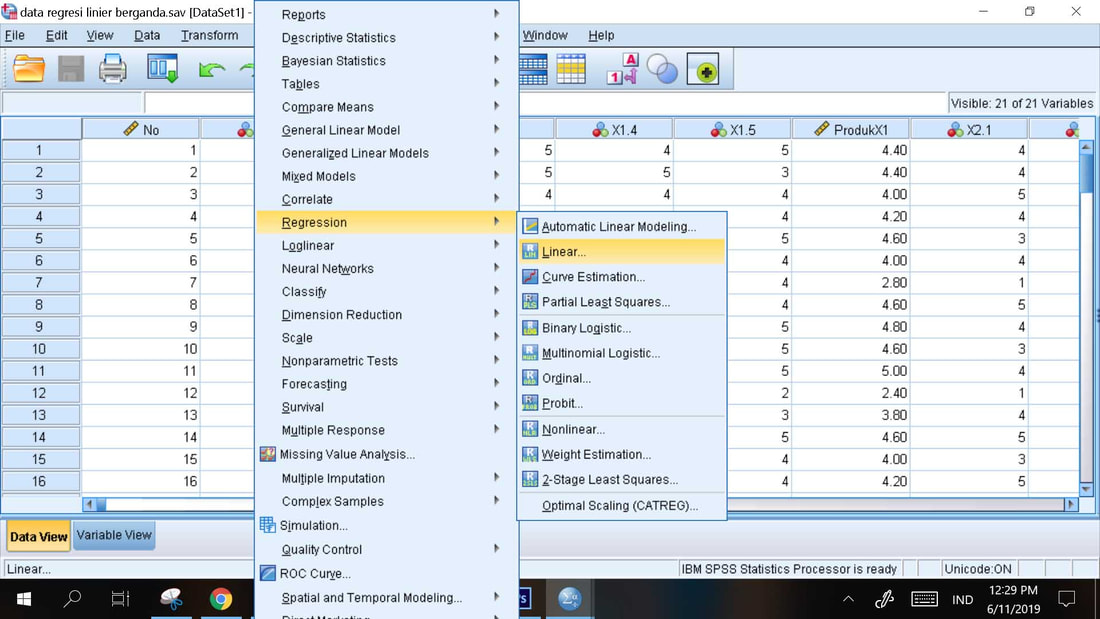
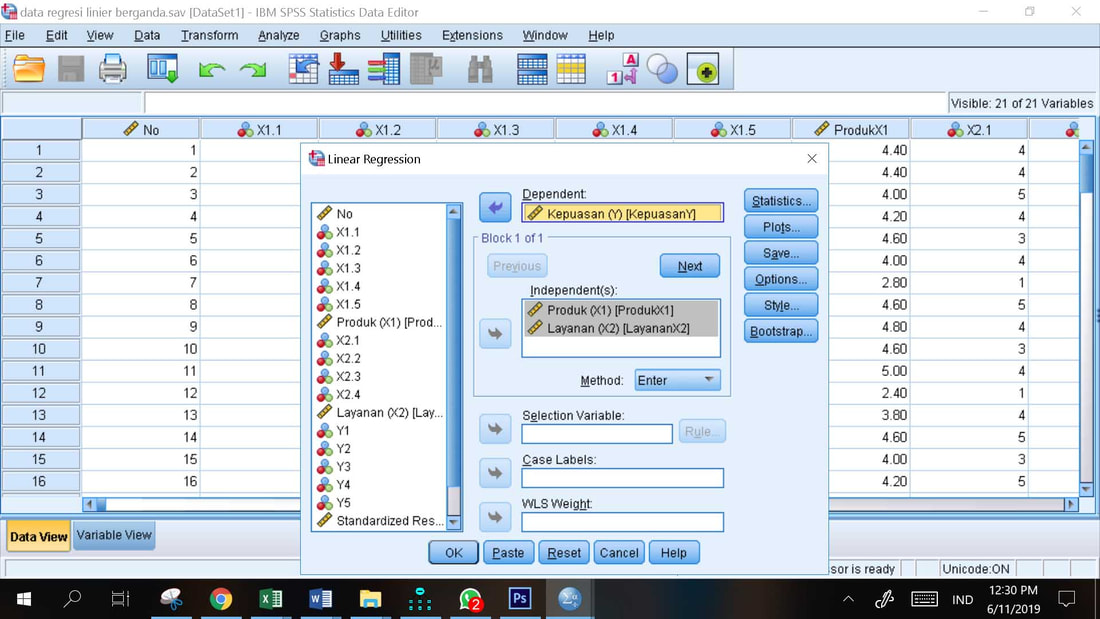
Prosedur Analisis Regresi Berganda
1. Analyze, Regression, Linear
2. Masukkan X1 dan X2 ke kolom Independent(s) dan Y ke kolom Dependent
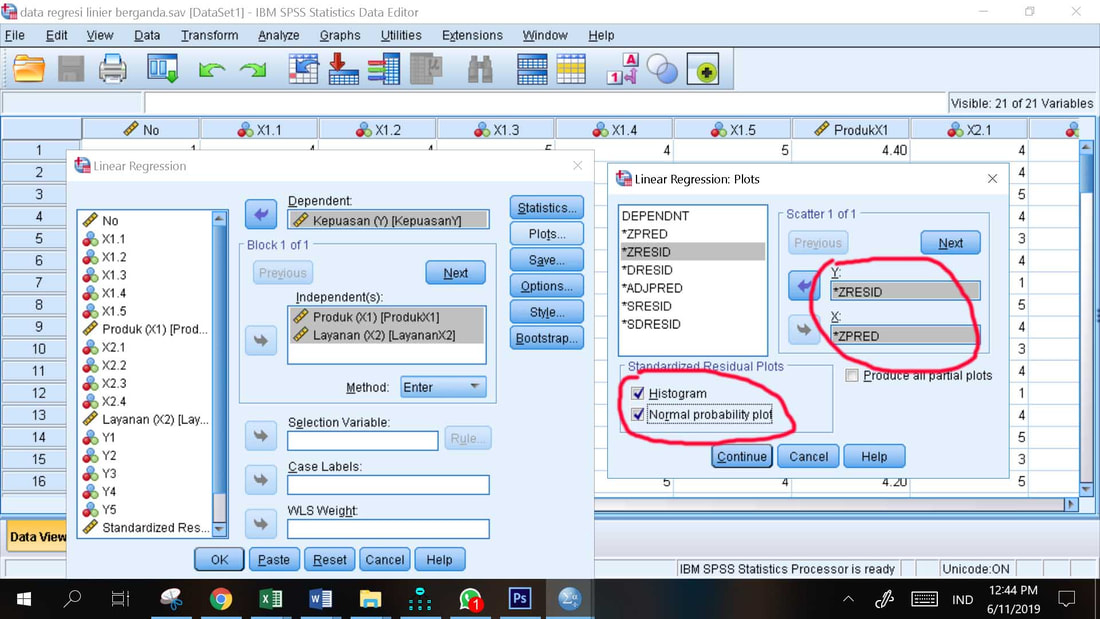
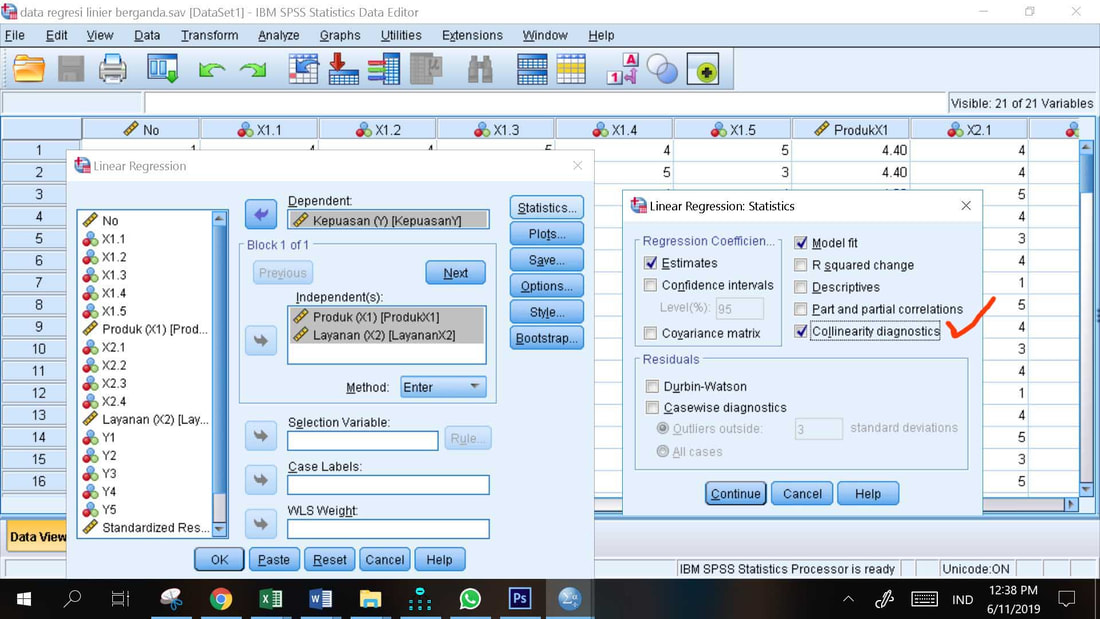
3. Statistics, dan centang Collinierity Diagnostics (ini untuk uji multikolinieritas), Continue
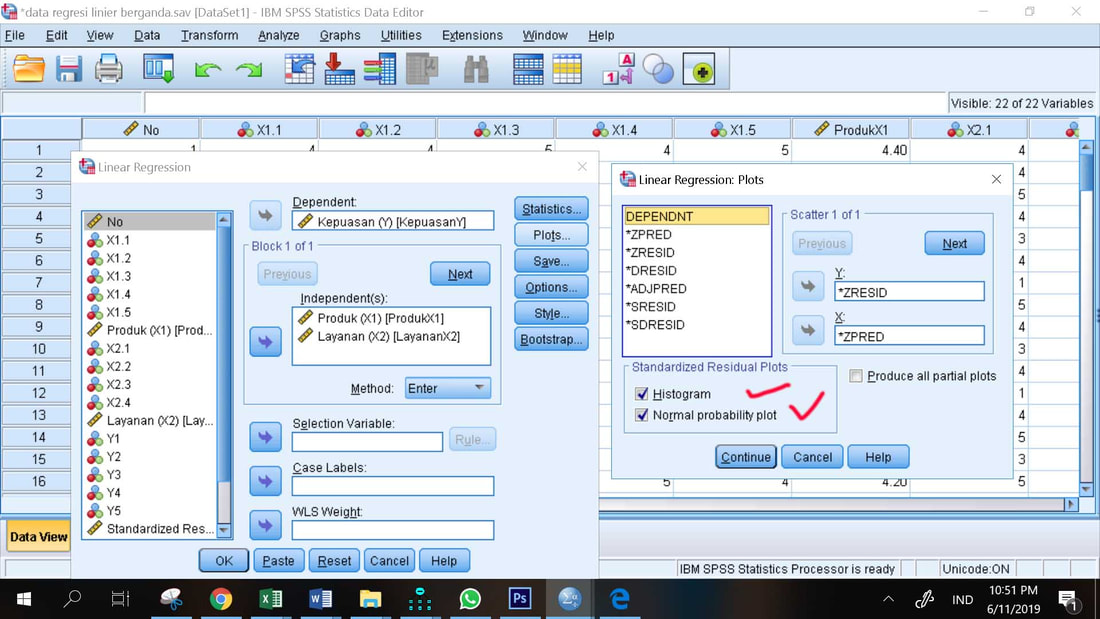
4. Klik Plot, masukkkan ZRESID ke kolom Y dan ZPRED ke kolom X (ini untuk uji heteroskedastisitas visual)
5. Centang Histogram dan Normal probability plot (ini untuk uji normalitas visual), Continue
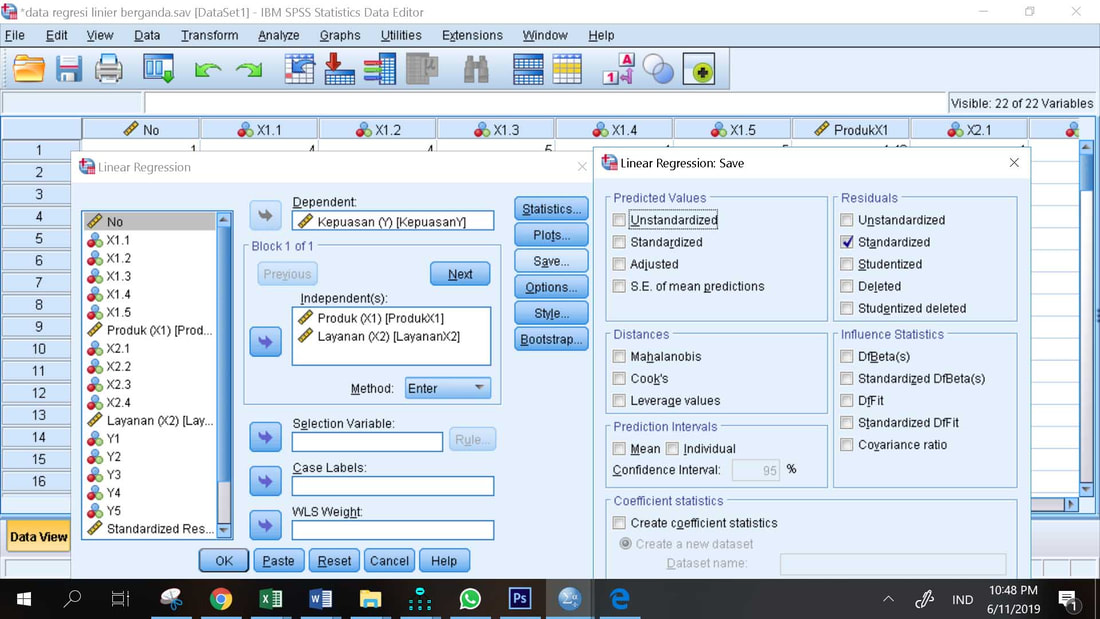
6. Pilih Save, centang Standardized pada kotak Residual, ini untuk menyimpan nilai residual atau error dimana nantinya data ini digunakan untuk melakukan uji normalitas dan hetersoskedastisitas secara statistics, lalu tekan tanda x (silang)
7. OK
Prosedur Analisis Regresi Berganda
1. Analyze, Regression, Linear
2. Masukkan X1 dan X2 ke kolom Independent(s) dan Y ke kolom Dependent
3. Statistics, dan centang Collinierity Diagnostics (ini untuk uji multikolinieritas), Continue
4. Klik Plot, masukkkan ZRESID ke kolom Y dan ZPRED ke kolom X (ini untuk uji heteroskedastisitas visual)
5. Centang Histogram dan Normal probability plot (ini untuk uji normalitas visual), Continue
6. Pilih Save, centang Standardized pada kotak Residual, ini untuk menyimpan nilai residual atau error dimana nantinya data ini digunakan untuk melakukan uji normalitas dan hetersoskedastisitas secara statistics, lalu tekan tanda x (silang)
7. OK
Hasil analisis regresi linier berganda dari program SPSS tertera pada gambar di bawah ini.
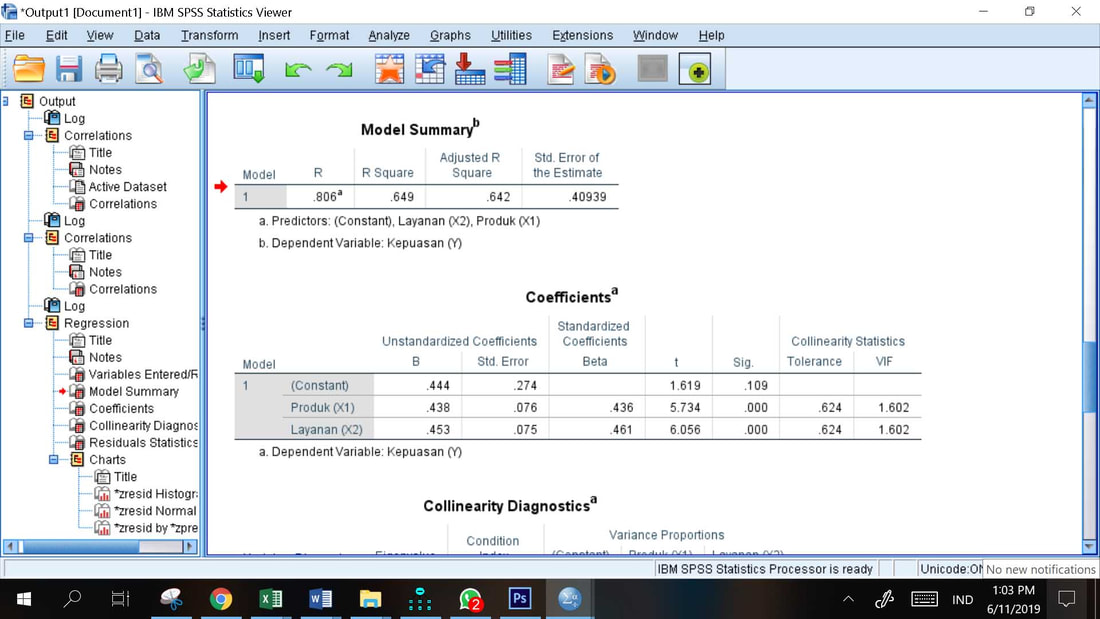
Interpretasi hasil regresi linier berganda
Koefisien Determinasi
Nilai R square = 0.649 dari tabel di atas menunjukkan bahwa 64.9% dari varians Y dapat dijelaskan oleh perubahan dalam variabel X1 dan X2. Sedangkan 45.1% sisanya dijelaskan oleh faktor lain di luar model.
Uji t (Uji Hipotesis), Uji t dimaksudkan untuk menguji apakah variabel independen secara parsial berpengaruh signifikan terhadap variabel dependen.
Hipotesis:
H0: variabel independen secara parsial tidak berpengaruh signifikan terhadap variabel dependen
H1: variabel independen secara parsial berpengaruh signifikan terhadap variabel dependen
Dasar Pengambilan Keputusan
Jika probabilitasnya (nilai sig) > 0.05 atau - t tabel< t hitung< t tabel maka H0 tidakditolak
Jika probabilitasnya (nilai sig) < 0.05 atau t hitung< - t tabel atau t hitung> t tabel maka H0 ditolak, diterima H1.
Keputusan:
Dengan demikian persamaan estimasinya adalah :
Y = 0.444 + 0.438*X1 + 0.453*X2 + e
Jika X1 naik satu satuan, dan X2 tetap maka Y akan naik sebesar 0.438 satuan. Jika X2 naik satu satuan, dan X1 tetap maka Y akan naik sebesar 0.453 satuan, maka disimpulkan X2 lebih berpengaruh terhadap Y dari pada X1, karena koefisien regresi X2 lebih tinggi dari pada koeisien regresi X1. Jika X1 dan X2 bernilai nol, maka nilai Y sebesar konstanta a, yaitu 0.444.
Video berikut ini menjelaskan teori dan aplikasi analisis regresi linier
Koefisien Determinasi
Nilai R square = 0.649 dari tabel di atas menunjukkan bahwa 64.9% dari varians Y dapat dijelaskan oleh perubahan dalam variabel X1 dan X2. Sedangkan 45.1% sisanya dijelaskan oleh faktor lain di luar model.
Uji t (Uji Hipotesis), Uji t dimaksudkan untuk menguji apakah variabel independen secara parsial berpengaruh signifikan terhadap variabel dependen.
Hipotesis:
H0: variabel independen secara parsial tidak berpengaruh signifikan terhadap variabel dependen
H1: variabel independen secara parsial berpengaruh signifikan terhadap variabel dependen
Dasar Pengambilan Keputusan
Jika probabilitasnya (nilai sig) > 0.05 atau - t tabel< t hitung< t tabel maka H0 tidakditolak
Jika probabilitasnya (nilai sig) < 0.05 atau t hitung< - t tabel atau t hitung> t tabel maka H0 ditolak, diterima H1.
Keputusan:
- Pada tabel di atas nilai sig variabel X1 = 0.000 < 0.05 sehingga H0 ditolak, yang berarti variabel independen ini secara parsial berpengaruh positif dan signifikan terhadap variabel Y. Makin tinggi X1, makin tinggi Y. Demikian juga sebaliknya.
- Pada tabel di atas nilai sig variabel X2 = 0.000 < 0.05 sehingga H0 ditolak, yang berarti variabel independen ini secara parsial berpengaruh positif dan signifikan terhadap variabel Y. Makin tinggi X2, makin tinggi Y. Demikian juga sebaliknya.
Dengan demikian persamaan estimasinya adalah :
Y = 0.444 + 0.438*X1 + 0.453*X2 + e
Jika X1 naik satu satuan, dan X2 tetap maka Y akan naik sebesar 0.438 satuan. Jika X2 naik satu satuan, dan X1 tetap maka Y akan naik sebesar 0.453 satuan, maka disimpulkan X2 lebih berpengaruh terhadap Y dari pada X1, karena koefisien regresi X2 lebih tinggi dari pada koeisien regresi X1. Jika X1 dan X2 bernilai nol, maka nilai Y sebesar konstanta a, yaitu 0.444.
Video berikut ini menjelaskan teori dan aplikasi analisis regresi linier
Pengujian Asumsi Klasik
Model regresi linier dapat dianggap sebagai model yang baik jika model tersebut memenuhi asumsi yang disebut asumsi klasik. Jika nilai hasil uji asumsi klasik dipenuhi, maka metode estimasi akan menghasilkkan sebuah estimator yang linear yang tidak ditata dan memiliki varian minimum yang sering disebut BLUE (Best Linear Unbiased Estimator).
Asumsi Klasik dalam Regresi Linier Berganda
Regresi linier adalah analisis yang menilai apakah satu atau lebih variabel prediktor menjelaskan variabel dependen. Regresi Linier Berganda memiliki empat asumsi utama:
Dalam perangkat lunak di bawah ini, sangat mudah untuk melakukan regresi dan sebagian besar asumsi dimuat dan ditafsirkan untuk Anda.
Pertama, regresi linier membutuhkan hubungan antara variabel independen dan dependen menjadi linier. Penting juga untuk memeriksa outlier karena regresi linier sensitif terhadap efek outlier. Asumsi linearitas paling baik dapat diuji dengan plot pencar, dua contoh berikut menggambarkan dua kasus, di mana tidak ada dan sedikit linearitas hadir.
Kedua, analisis regresi linier mengharuskan residual hasil regresi berdistribusi normal. Asumsi ini dapat diperiksa dengan histogram atau Q-Q-Plot. Normalitas dapat diperiksa dengan uji goodness of fit, misalnya dengan Uji Kolmogorov-Smirnov. Saat data tidak terdistribusi secara normal, transformasi non-linear (mis., Transformasi log) atau menghapus data outlier dapat memperbaiki masalah ini.
Ketiga, regresi linier mengasumsikan bahwa ada sedikit atau tidak ada multikolinieritas dalam data. Multikolinieritas terjadi ketika variabel independen terlalu berkorelasi satu sama lain.
Multikolinearitas dapat diuji dengan tiga kriteria utama:
1) Matriks Korelasi - ketika menghitung matriks Korelasi Bivariat Pearson di antara semua variabel independen, koefisien korelasi harus lebih kecil dari 1.
2) Tolerance - toleransi mengukur pengaruh satu variabel independen terhadap semua variabel independen lainnya; toleransi dihitung dengan analisis regresi linier awal. Toleransi didefinisikan sebagai T = 1 - R² untuk analisis regresi langkah pertama ini. Dengan T < 0.1 mungkin ada multikolinieritas dalam data dan dengan T < 0.01 pasti saja ada.
3) Variance Inflation Factor (VIF) - faktor inflasi varians dari regresi linier didefinisikan sebagai VIF = 1 / T. Dengan VIF> 10 ada indikasi bahwa multikolinearitas mungkin ada; dengan VIF > 100 pasti ada multikolinieritas antar variabel.
Jika multikolinieritas ditemukan dalam data, memusatkan data (yang mengurangi rata-rata variabel dari setiap skor) dapat membantu menyelesaikan masalah. Namun, cara paling sederhana untuk mengatasi masalah ini adalah dengan menghapus variabel independen dengan nilai VIF tinggi.
Keempat, analisis regresi linier mensyaratkan bahwa ada sedikit atau tidak ada autokorelasi dalam data. Autokorelasi terjadi ketika residu tidak independen satu sama lain. Misalnya, ini biasanya terjadi pada harga saham, di mana harga tidak terlepas dari harga sebelumnya.
Condition Index - indeks kondisi dihitung menggunakan analisis faktor pada variabel independen. Nilai 10-30 menunjukkan multikolinieritas biasa-biasa saja dalam variabel regresi linier, nilai> 30 menunjukkan multikolinieritas yang kuat.
Jika multikolinieritas ditemukan dalam data yang memusatkan data, itu berarti mengurangi nilai rata-rata yang dapat membantu menyelesaikan masalah. Alternatif lain untuk mengatasi masalah adalah melakukan analisis faktor dan memutar faktor untuk memastikan independensi faktor dalam analisis regresi linier.
Keempat, analisis regresi linier mensyaratkan bahwa ada sedikit atau tidak ada autokorelasi dalam data. Autokorelasi terjadi ketika residu tidak independen satu sama lain. Dengan kata lain ketika nilai y (x + 1) tidak independen dari nilai y (x).
Meskipun sebaran scatter memungkinkan Anda memeriksa autokorelasi, Anda dapat menguji model regresi linier untuk autokorelasi dengan tes Durbin-Watson. Durbin-Watson's menguji hipotesis nol bahwa residu tidak secara otomatis berkorelasi. Sementara d dapat mengasumsikan nilai antara 0 dan 4, nilai sekitar 2 menunjukkan tidak ada autokorelasi. Sebagai aturan praktis nilai 1,5 <d <2,5 menunjukkan bahwa tidak ada korelasi otomatis dalam data. Namun, tes Durbin-Watson hanya menganalisis autokorelasi linier dan hanya antara tetangga langsung, yang merupakan efek urutan pertama.
Asumsi terakhir dari analisis regresi linier adalah homoskedastisitas. Plot sebar adalah cara yang baik untuk memeriksa apakah datanya homoskedastik (artinya residu sama di seluruh garis regresi). Plot sebar berikut menunjukkan contoh-contoh data yang bukan homoskedastik (mis., Heteroskedastik)
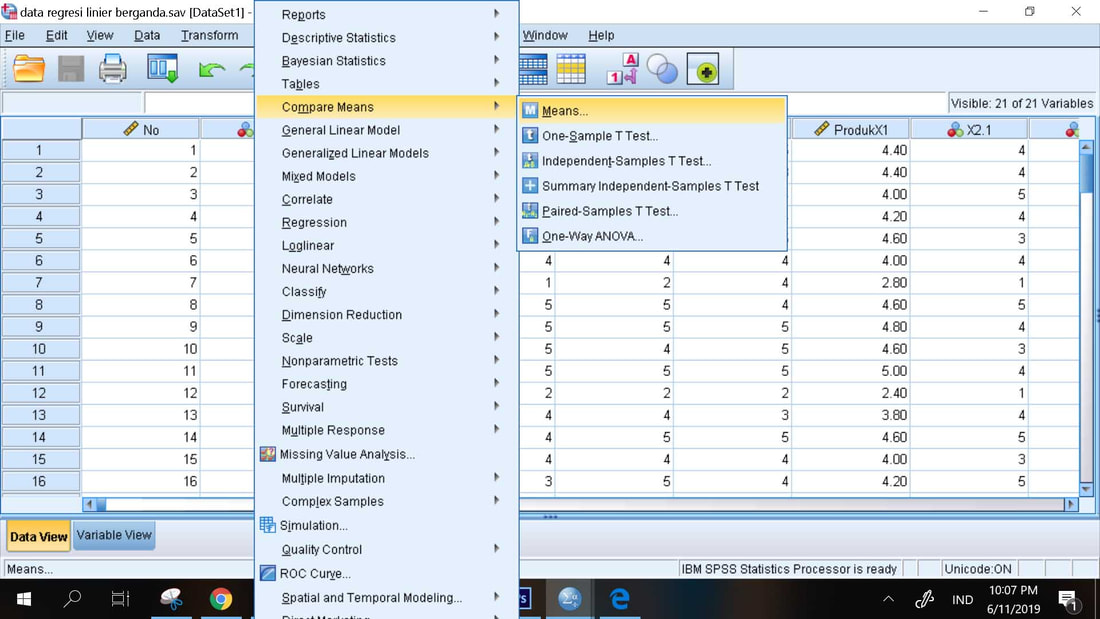
A. Prosedur Uji Linieritas
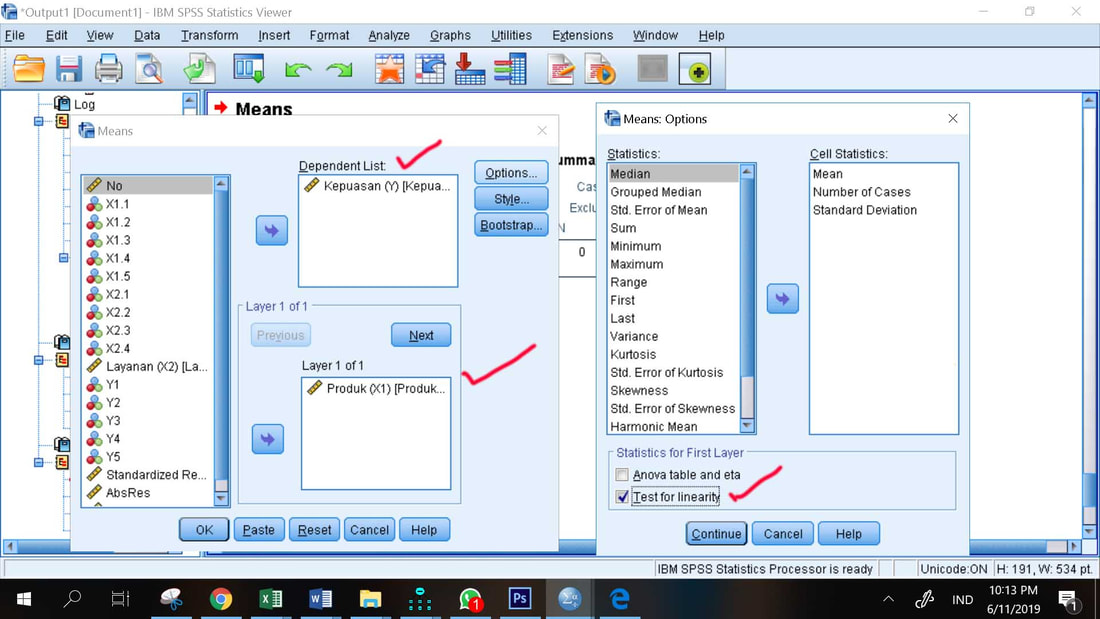
1. Analyze, Compare Means, Means
2. Masukkan X1 ke Independen List dan Y ke Dependent List
3. Option, centang Test for Linearity
4. Continue, OK
Model regresi linier dapat dianggap sebagai model yang baik jika model tersebut memenuhi asumsi yang disebut asumsi klasik. Jika nilai hasil uji asumsi klasik dipenuhi, maka metode estimasi akan menghasilkkan sebuah estimator yang linear yang tidak ditata dan memiliki varian minimum yang sering disebut BLUE (Best Linear Unbiased Estimator).
Asumsi Klasik dalam Regresi Linier Berganda
Regresi linier adalah analisis yang menilai apakah satu atau lebih variabel prediktor menjelaskan variabel dependen. Regresi Linier Berganda memiliki empat asumsi utama:
- Linieritas
- Normalitas
- Tidak ada atau sedikit multikolinearitas
- Tidak ada autokorelasi
- Tidak ada heteroskedastisitas (Homoskedastisitas)
Dalam perangkat lunak di bawah ini, sangat mudah untuk melakukan regresi dan sebagian besar asumsi dimuat dan ditafsirkan untuk Anda.
Pertama, regresi linier membutuhkan hubungan antara variabel independen dan dependen menjadi linier. Penting juga untuk memeriksa outlier karena regresi linier sensitif terhadap efek outlier. Asumsi linearitas paling baik dapat diuji dengan plot pencar, dua contoh berikut menggambarkan dua kasus, di mana tidak ada dan sedikit linearitas hadir.
Kedua, analisis regresi linier mengharuskan residual hasil regresi berdistribusi normal. Asumsi ini dapat diperiksa dengan histogram atau Q-Q-Plot. Normalitas dapat diperiksa dengan uji goodness of fit, misalnya dengan Uji Kolmogorov-Smirnov. Saat data tidak terdistribusi secara normal, transformasi non-linear (mis., Transformasi log) atau menghapus data outlier dapat memperbaiki masalah ini.
Ketiga, regresi linier mengasumsikan bahwa ada sedikit atau tidak ada multikolinieritas dalam data. Multikolinieritas terjadi ketika variabel independen terlalu berkorelasi satu sama lain.
Multikolinearitas dapat diuji dengan tiga kriteria utama:
1) Matriks Korelasi - ketika menghitung matriks Korelasi Bivariat Pearson di antara semua variabel independen, koefisien korelasi harus lebih kecil dari 1.
2) Tolerance - toleransi mengukur pengaruh satu variabel independen terhadap semua variabel independen lainnya; toleransi dihitung dengan analisis regresi linier awal. Toleransi didefinisikan sebagai T = 1 - R² untuk analisis regresi langkah pertama ini. Dengan T < 0.1 mungkin ada multikolinieritas dalam data dan dengan T < 0.01 pasti saja ada.
3) Variance Inflation Factor (VIF) - faktor inflasi varians dari regresi linier didefinisikan sebagai VIF = 1 / T. Dengan VIF> 10 ada indikasi bahwa multikolinearitas mungkin ada; dengan VIF > 100 pasti ada multikolinieritas antar variabel.
Jika multikolinieritas ditemukan dalam data, memusatkan data (yang mengurangi rata-rata variabel dari setiap skor) dapat membantu menyelesaikan masalah. Namun, cara paling sederhana untuk mengatasi masalah ini adalah dengan menghapus variabel independen dengan nilai VIF tinggi.
Keempat, analisis regresi linier mensyaratkan bahwa ada sedikit atau tidak ada autokorelasi dalam data. Autokorelasi terjadi ketika residu tidak independen satu sama lain. Misalnya, ini biasanya terjadi pada harga saham, di mana harga tidak terlepas dari harga sebelumnya.
Condition Index - indeks kondisi dihitung menggunakan analisis faktor pada variabel independen. Nilai 10-30 menunjukkan multikolinieritas biasa-biasa saja dalam variabel regresi linier, nilai> 30 menunjukkan multikolinieritas yang kuat.
Jika multikolinieritas ditemukan dalam data yang memusatkan data, itu berarti mengurangi nilai rata-rata yang dapat membantu menyelesaikan masalah. Alternatif lain untuk mengatasi masalah adalah melakukan analisis faktor dan memutar faktor untuk memastikan independensi faktor dalam analisis regresi linier.
Keempat, analisis regresi linier mensyaratkan bahwa ada sedikit atau tidak ada autokorelasi dalam data. Autokorelasi terjadi ketika residu tidak independen satu sama lain. Dengan kata lain ketika nilai y (x + 1) tidak independen dari nilai y (x).
Meskipun sebaran scatter memungkinkan Anda memeriksa autokorelasi, Anda dapat menguji model regresi linier untuk autokorelasi dengan tes Durbin-Watson. Durbin-Watson's menguji hipotesis nol bahwa residu tidak secara otomatis berkorelasi. Sementara d dapat mengasumsikan nilai antara 0 dan 4, nilai sekitar 2 menunjukkan tidak ada autokorelasi. Sebagai aturan praktis nilai 1,5 <d <2,5 menunjukkan bahwa tidak ada korelasi otomatis dalam data. Namun, tes Durbin-Watson hanya menganalisis autokorelasi linier dan hanya antara tetangga langsung, yang merupakan efek urutan pertama.
Asumsi terakhir dari analisis regresi linier adalah homoskedastisitas. Plot sebar adalah cara yang baik untuk memeriksa apakah datanya homoskedastik (artinya residu sama di seluruh garis regresi). Plot sebar berikut menunjukkan contoh-contoh data yang bukan homoskedastik (mis., Heteroskedastik)
A. Prosedur Uji Linieritas
1. Analyze, Compare Means, Means
2. Masukkan X1 ke Independen List dan Y ke Dependent List
3. Option, centang Test for Linearity
4. Continue, OK
Hasil uji linieritas tertera pada gambar di bawah ini
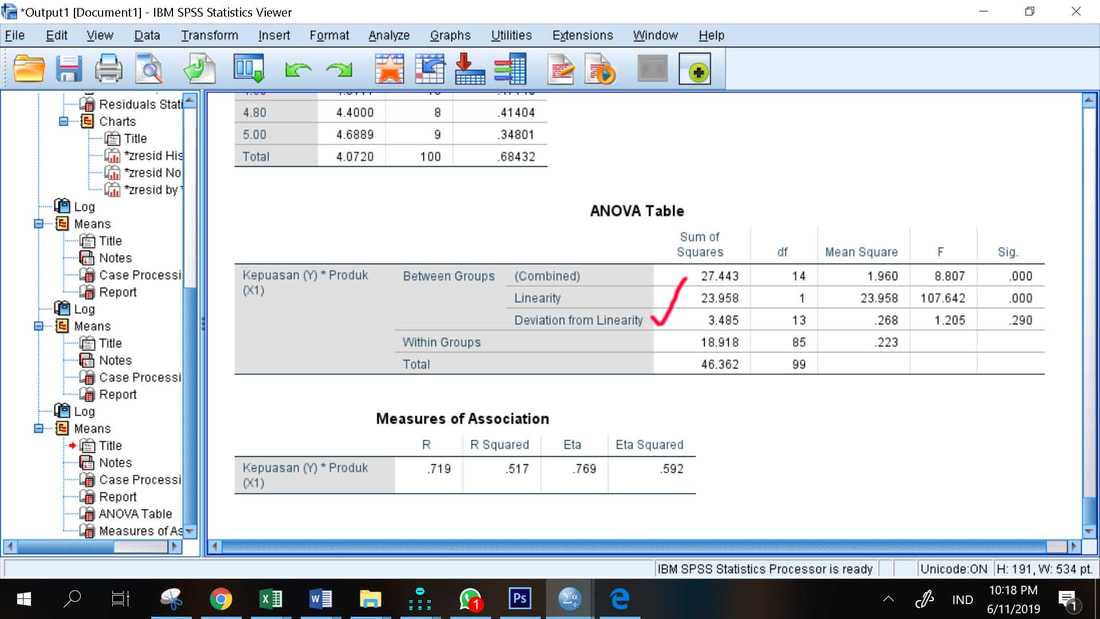
Dasar Pengambilan Keputusan Uji Linieritas:
Jika nilai sig Deviation from Linearity > 0.05, maka hubungan variabel independen dan variabel dependen adalah hubungan linier
Jika nilai sig Deviation from Linearity < 0.05, maka hubungan variabel independen dan variabel dependen adalah hubungan tidak linier
Keputusan
Pada tabel di atas nilai sig Deviation from Linearity = 0.290 > 0.05, maka disimpulkan hubungan variabel independen X1 dan variabel dependen Y adalah hubungan linier. Asumsi Klasik yang pertama dipenuhi
B. Prosedur Uji Normalitas secara visual
Prosedur uji normalitas secara visual, telah dilakukan pada saat melakukan analisis regresi di bagian atas, dituliskan kembali di sini:
Prosedur Analisis Regresi Berganda
1. Analyze, Regression, Linear
2. Masukkan X1 dan X2 ke kolom Independent(s) dan Y ke kolom Dependent
3. Statistics, dan centang Collinierity Diagnostics (ini untuk uji multikolinieritas), Continue
4. Klik Plot, masukkkan ZRESID ke kolom Y dan ZPRED ke kolom X (ini untuk uji heteroskedastisitas visual)
5. Centang Histogram dan Normal probability plot (ini untuk uji normalitas visual), Continue
6. Pilih Save, centang Standardized pada kotak Residual, ini untuk menyimpan nilai residual atau error dimana nantinya data ini digunakan untuk melakukan uji normalitas dan hetersoskedastisitas secara statistics, lalu tekan tanda x (silang)
7. OK
Butir nomor lima di atas adalah prosedur uji normalitas secara visual. Hasil uji normalitas visual tertera pada gambar berikut ini
Jika nilai sig Deviation from Linearity > 0.05, maka hubungan variabel independen dan variabel dependen adalah hubungan linier
Jika nilai sig Deviation from Linearity < 0.05, maka hubungan variabel independen dan variabel dependen adalah hubungan tidak linier
Keputusan
Pada tabel di atas nilai sig Deviation from Linearity = 0.290 > 0.05, maka disimpulkan hubungan variabel independen X1 dan variabel dependen Y adalah hubungan linier. Asumsi Klasik yang pertama dipenuhi
B. Prosedur Uji Normalitas secara visual
Prosedur uji normalitas secara visual, telah dilakukan pada saat melakukan analisis regresi di bagian atas, dituliskan kembali di sini:
Prosedur Analisis Regresi Berganda
1. Analyze, Regression, Linear
2. Masukkan X1 dan X2 ke kolom Independent(s) dan Y ke kolom Dependent
3. Statistics, dan centang Collinierity Diagnostics (ini untuk uji multikolinieritas), Continue
4. Klik Plot, masukkkan ZRESID ke kolom Y dan ZPRED ke kolom X (ini untuk uji heteroskedastisitas visual)
5. Centang Histogram dan Normal probability plot (ini untuk uji normalitas visual), Continue
6. Pilih Save, centang Standardized pada kotak Residual, ini untuk menyimpan nilai residual atau error dimana nantinya data ini digunakan untuk melakukan uji normalitas dan hetersoskedastisitas secara statistics, lalu tekan tanda x (silang)
7. OK
Butir nomor lima di atas adalah prosedur uji normalitas secara visual. Hasil uji normalitas visual tertera pada gambar berikut ini
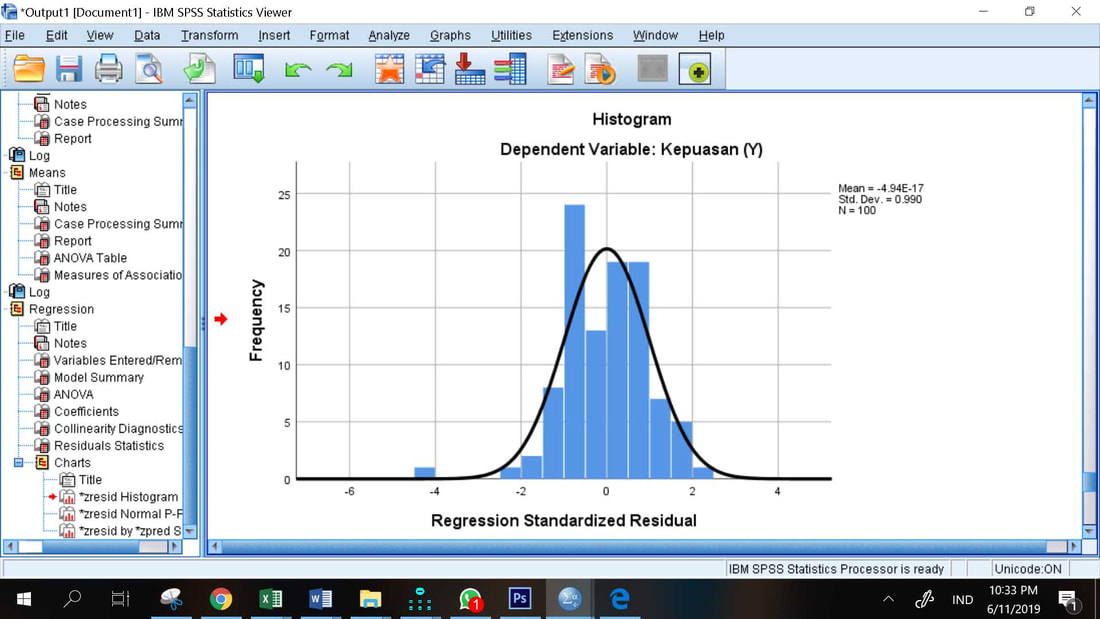
Karena disribusi residual mendekati distribusi normal teoritis (bentuk lonceng), disimpulkan bahwa secara penampakan visual residual berdistribusi normal. Uji normalitas untuk kebutuhan pemenuhan asumsi klasik regresi linier berganda dilakukan pada hasil residual, bukan dilakukan pada data masing-masing variabel.
B. Prosedur uji normalitas dengan Uji Kolmogorov Smirnov
Prosedur nomor 6 pada prosedur analisis regresi berganda ada perintah kepada program SPSS untuk menyimpan nilai residual terstandar pada bagian akhir data SPSS dimana hasil proses tersebut tertera pada gambar berikut ini.
B. Prosedur uji normalitas dengan Uji Kolmogorov Smirnov
Prosedur nomor 6 pada prosedur analisis regresi berganda ada perintah kepada program SPSS untuk menyimpan nilai residual terstandar pada bagian akhir data SPSS dimana hasil proses tersebut tertera pada gambar berikut ini.
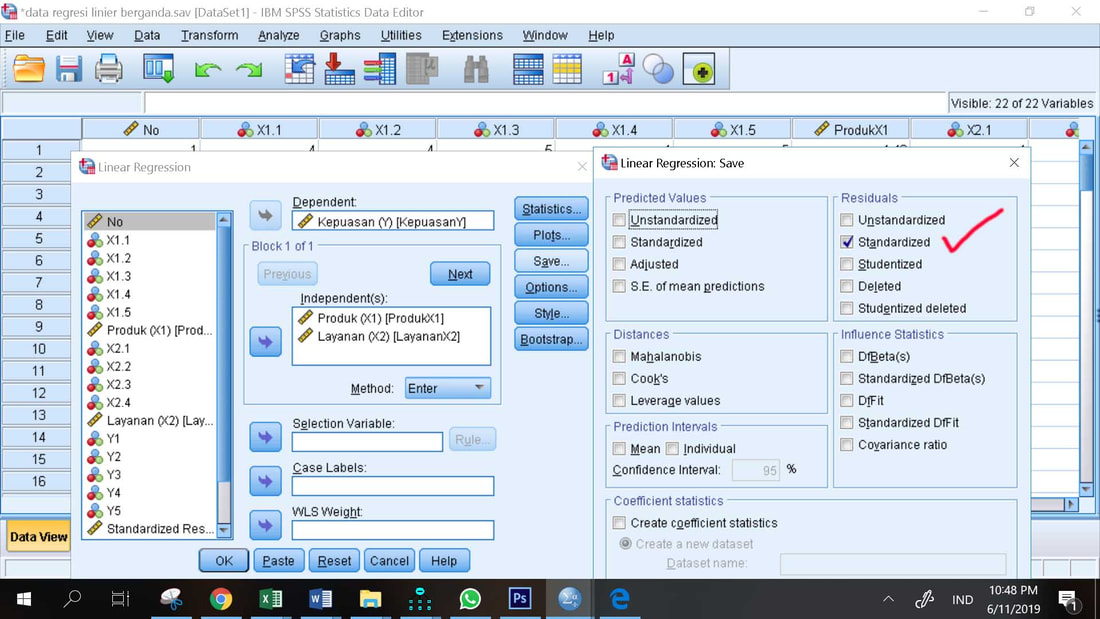
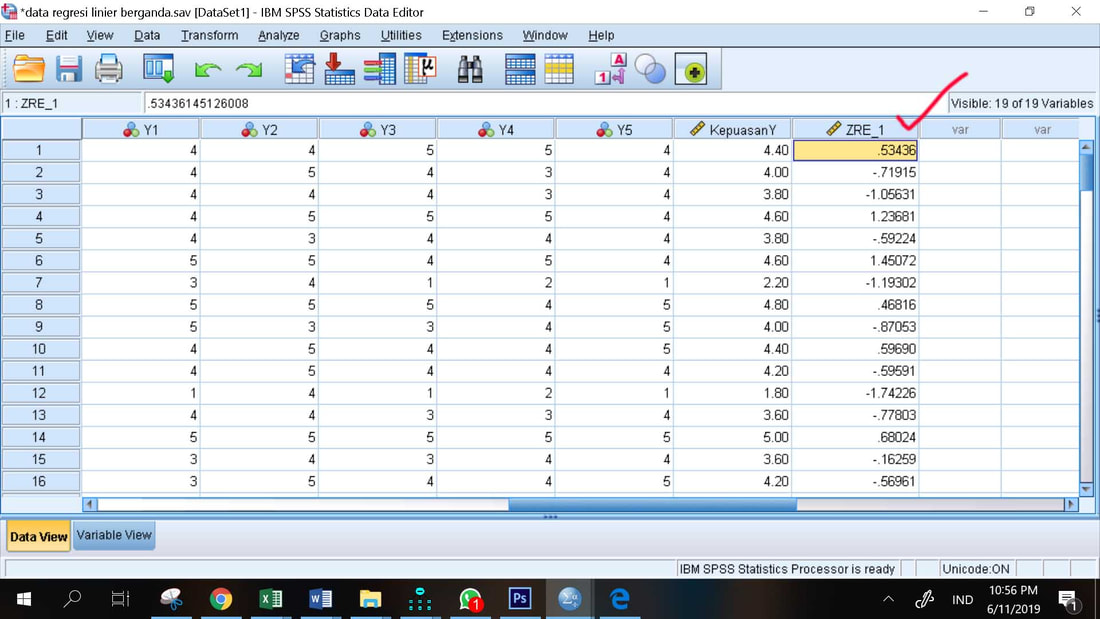
Nilai ZRE_1 pada bagian akhir data SPSS adalah data residual yang ditambahkan oleh program SPSS karena perintah Save pada prosedur regresi. Data inilah yang akan diuji normalitasnya dengan Uji Kolmogorov Smirnov.
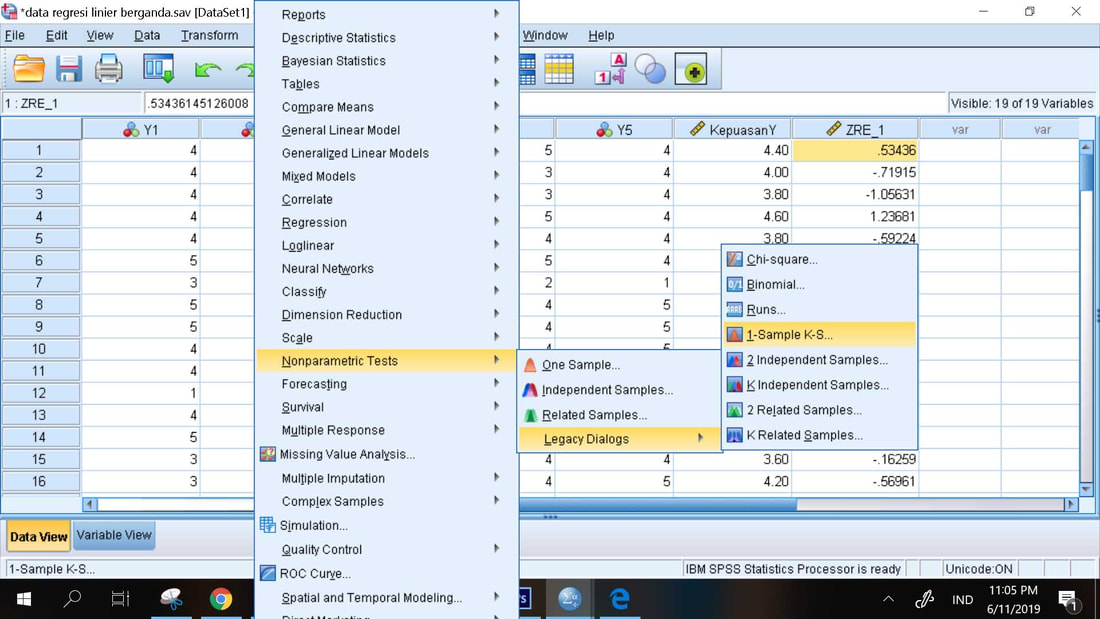
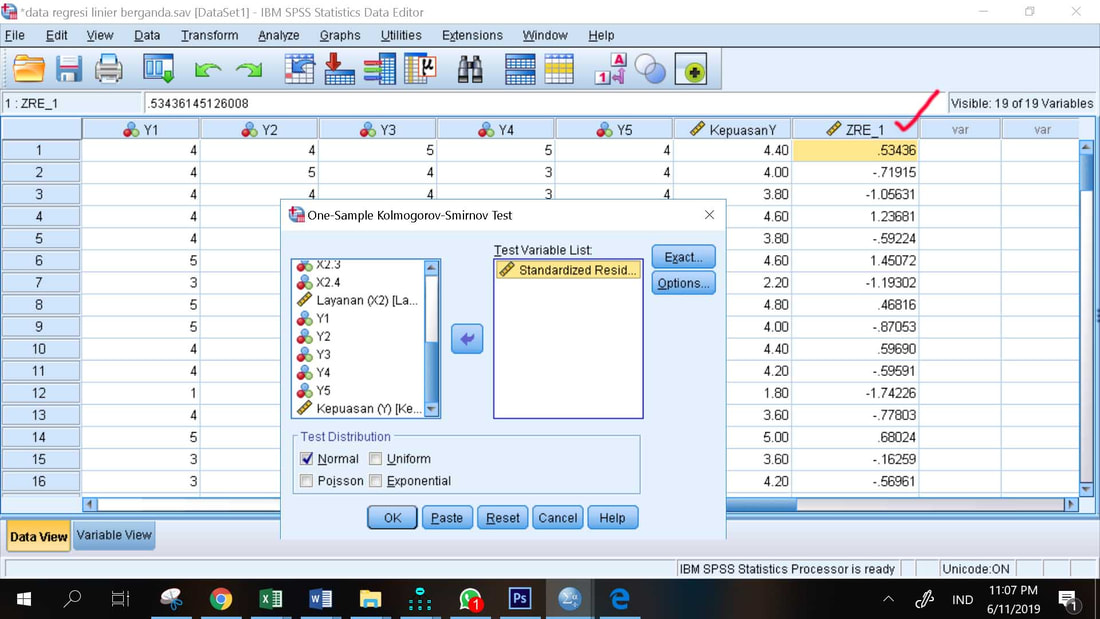
1. Analyze, Nonparametric Tests, Legacy Dialogs, 1-Sample K-S
2. Masukkan data Standardized Residual ke dalam kotak Test variable list
3. OK
1. Analyze, Nonparametric Tests, Legacy Dialogs, 1-Sample K-S
2. Masukkan data Standardized Residual ke dalam kotak Test variable list
3. OK
Hasil uji normalitasnya dengan Uji Kolmogorov Smirnov tertera pada tabel di bawah ini
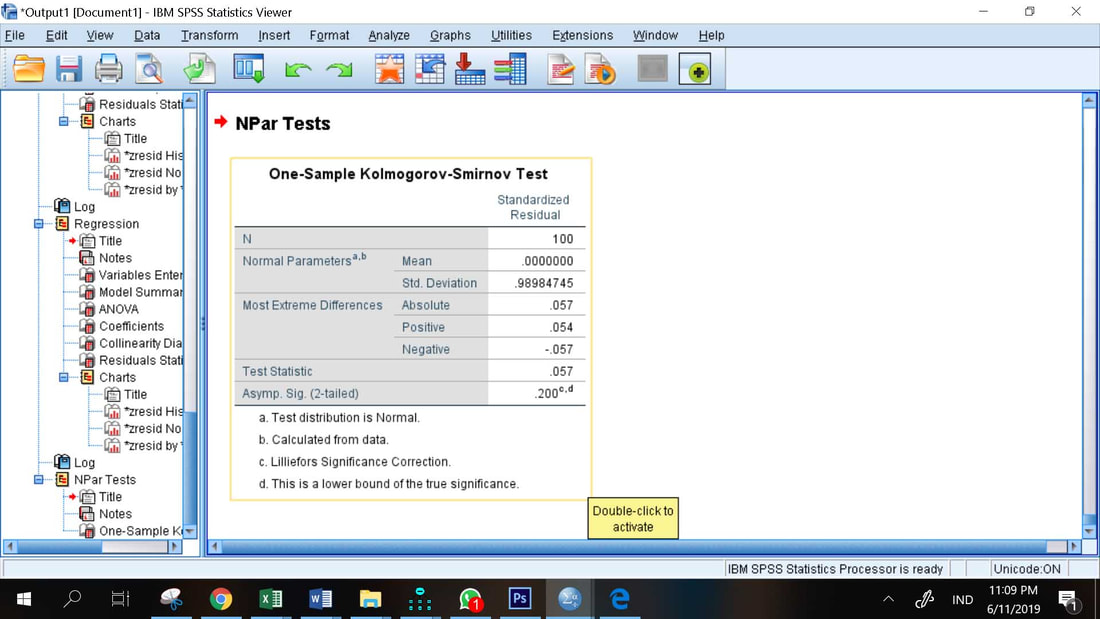
Uji normalitas (uji Kolmogorov- Smirnov)
Uji normalitas adalah untuk melihat apakah nilai residual terdistribusi normal atau tidak. Model regresi yang baik adalah memiliki nilai residual yang terdistribusi normal. Jadi uji normalitas bukan dilakukan pada masing-masing variabel tetapi pada nilai residualnya.
Hipotesis:
H0: data berdistribusi normal
H1: data tidak berdistribusi normal
Dasar Pengambilan Keputusan
Jika probabilitasnya (nilai sig) > 0.05 maka H0 tidak ditolak
Jika probabilitasnya (nilai sig) < 0.05 maka H0 ditolak
Keputusan:
Pada tabel di atas nilai sig = 0.200 > 0.05, sehingga H0 tidak ditolak, yang berarti data residual berdistribusi normal. Jika ternyata data residual tidak berdistribusi normal, maka transformasi data atau penghapusan nilai outlier merupakan pilihan untuk mengatasi masalah ini.
Video berikut ini adalah prosedur uji normalitas
Uji normalitas adalah untuk melihat apakah nilai residual terdistribusi normal atau tidak. Model regresi yang baik adalah memiliki nilai residual yang terdistribusi normal. Jadi uji normalitas bukan dilakukan pada masing-masing variabel tetapi pada nilai residualnya.
Hipotesis:
H0: data berdistribusi normal
H1: data tidak berdistribusi normal
Dasar Pengambilan Keputusan
Jika probabilitasnya (nilai sig) > 0.05 maka H0 tidak ditolak
Jika probabilitasnya (nilai sig) < 0.05 maka H0 ditolak
Keputusan:
Pada tabel di atas nilai sig = 0.200 > 0.05, sehingga H0 tidak ditolak, yang berarti data residual berdistribusi normal. Jika ternyata data residual tidak berdistribusi normal, maka transformasi data atau penghapusan nilai outlier merupakan pilihan untuk mengatasi masalah ini.
Video berikut ini adalah prosedur uji normalitas
C. Prosedur Uji Multikolinearitas
Prosedur uji normalitas secara visual, telah dilakukan pada saat melakukan analisis regresi di bagian atas, dituliskan kembali di sini:
Prosedur Analisis Regresi Berganda
1. Analyze, Regression, Linear
2. Masukkan X1 dan X2 ke kolom Independent(s) dan Y ke kolom Dependent
3. Statistics, dan centang Collinierity Diagnostics (ini untuk uji multikolinieritas), Continue
4. Klik Plot, masukkkan ZRESID ke kolom Y dan ZPRED ke kolom X (ini untuk uji heteroskedastisitas visual)
5. Centang Histogram dan Normal probability plot (ini untuk uji normalitas visual), Continue
6. Pilih Save, centang Standardized pada kotak Residual, ini untuk menyimpan nilai residual atau error dimana nantinya data ini digunakan untuk melakukan uji normalitas dan hetersoskedastisitas secara statistics, lalu tekan tanda x (silang)
7. OK
Prosedur regresi linier berganda nomor 3 yang telah dituliskan di atas, adalah prosedur untuk uji multikolinieritas. Prosedur dan hasilnya tercantum pada gambar di bawah ini.
Prosedur uji normalitas secara visual, telah dilakukan pada saat melakukan analisis regresi di bagian atas, dituliskan kembali di sini:
Prosedur Analisis Regresi Berganda
1. Analyze, Regression, Linear
2. Masukkan X1 dan X2 ke kolom Independent(s) dan Y ke kolom Dependent
3. Statistics, dan centang Collinierity Diagnostics (ini untuk uji multikolinieritas), Continue
4. Klik Plot, masukkkan ZRESID ke kolom Y dan ZPRED ke kolom X (ini untuk uji heteroskedastisitas visual)
5. Centang Histogram dan Normal probability plot (ini untuk uji normalitas visual), Continue
6. Pilih Save, centang Standardized pada kotak Residual, ini untuk menyimpan nilai residual atau error dimana nantinya data ini digunakan untuk melakukan uji normalitas dan hetersoskedastisitas secara statistics, lalu tekan tanda x (silang)
7. OK
Prosedur regresi linier berganda nomor 3 yang telah dituliskan di atas, adalah prosedur untuk uji multikolinieritas. Prosedur dan hasilnya tercantum pada gambar di bawah ini.
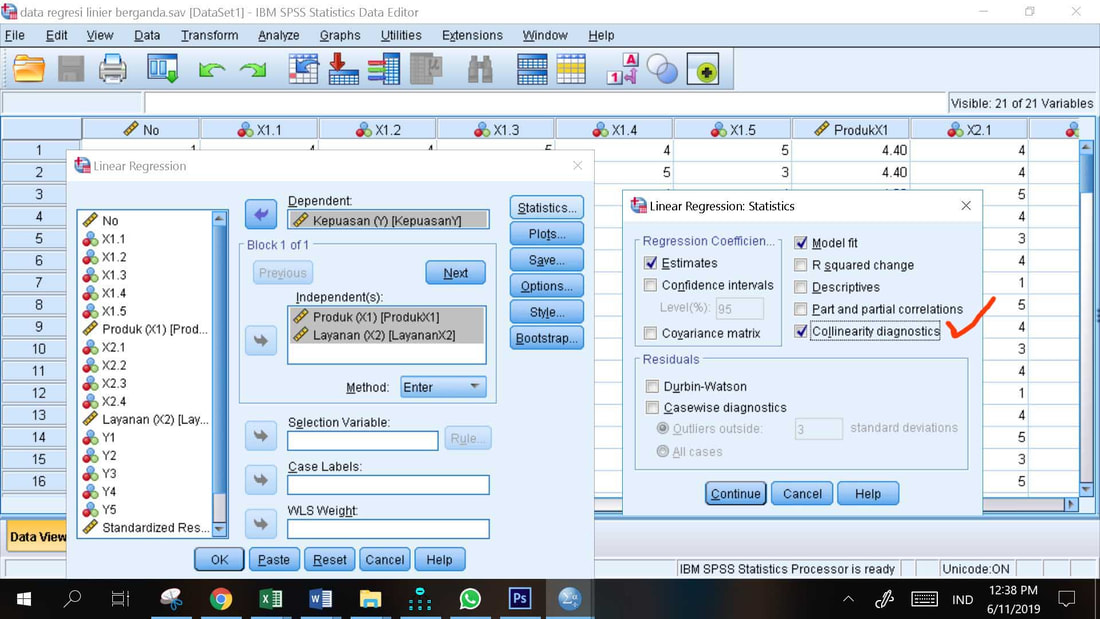
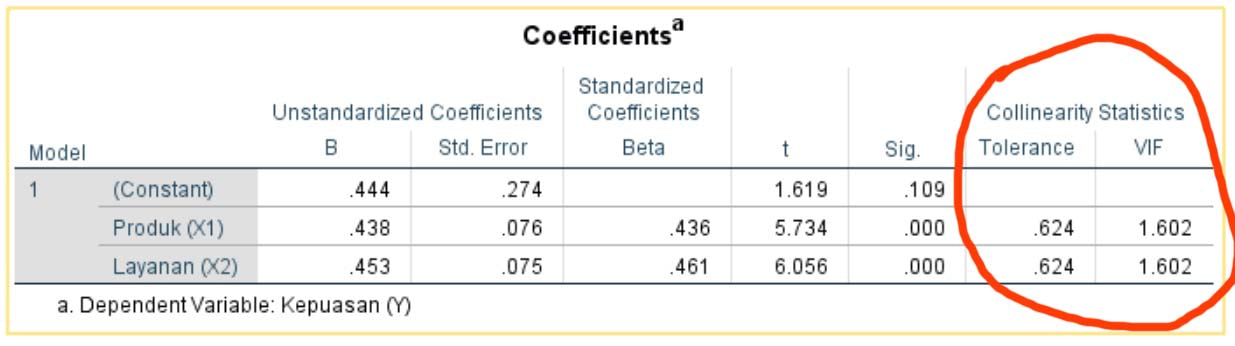
Multikolinearitas (kolinearitas ganda) berarti adanya hubungan linear yang sempurna di antara variabel-variabel bebas dalam model regresi. Korelasi yang kuat antar variabel bebas menunjukkan adanya multikolinearitas. Jika terdapat korelasi yang sempurna di antara variabel bebas, maka konsekuensinya adalah koefisien-koefisien regresi menjadi tidak dapat ditaksir, nilai standard error setiap regresi menjadi tidak terhingga.
Gejala multikolinearitas terjadi bila nilai tolerance kurang dari 0.1 atau VIF lebih dari 10.
Kesimpulan:
Berdasarkan nilai VIF X1 = X2 = 1.0602 yang berada di bawah 10, dan nilai tolerance X1=X2 = 0.624 > 0.1, disimpulkan tidak terjadi multikolinieritas antar variabel independen X1 dan X2.
D. Prosedur Uji Autokorelasi.
Biasanya uji autokorelasi dilakukan pada data urut waktu seperti data harga saham . Data dalam contoh ini adalah data cross section, sehingga sebenanya uji autokorelasi tidak diperlukan pada contoh ini.
Gejala multikolinearitas terjadi bila nilai tolerance kurang dari 0.1 atau VIF lebih dari 10.
Kesimpulan:
Berdasarkan nilai VIF X1 = X2 = 1.0602 yang berada di bawah 10, dan nilai tolerance X1=X2 = 0.624 > 0.1, disimpulkan tidak terjadi multikolinieritas antar variabel independen X1 dan X2.
D. Prosedur Uji Autokorelasi.
Biasanya uji autokorelasi dilakukan pada data urut waktu seperti data harga saham . Data dalam contoh ini adalah data cross section, sehingga sebenanya uji autokorelasi tidak diperlukan pada contoh ini.
E. Prosedur Uji Heteroskedastisitas Secara Visual
Prosedur uji heteroskedastisitas secara visual, telah dilakukan pada saat melakukan analisis regresi di bagian atas, dituliskan kembali di sini:
Prosedur Analisis Regresi Berganda
1. Analyze, Regression, Linear
2. Masukkan X1 dan X2 ke kolom Independent(s) dan Y ke kolom Dependent
3. Statistics, dan centang Collinierity Diagnostics (ini untuk uji multikolinieritas), Continue
4. Klik Plot, masukkkan ZRESID ke kolom Y dan ZPRED ke kolom X (ini untuk uji heteroskedastisitas visual)
5. Centang Histogram dan Normal probability plot (ini untuk uji normalitas visual), Continue
6. Pilih Save, centang Standardized pada kotak Residual, ini untuk menyimpan nilai residual atau error dimana nantinya data ini digunakan untuk melakukan uji normalitas dan hetersoskedastisitas secara statistics, lalu tekan tanda x (silang)
7. OK
Butir nomor empat di atas adalah prosedur uji heteroskedastisitassecara visual. Hasil uji heteroskedastisitas visual tertera pada gambar berikut ini
Prosedur uji heteroskedastisitas secara visual, telah dilakukan pada saat melakukan analisis regresi di bagian atas, dituliskan kembali di sini:
Prosedur Analisis Regresi Berganda
1. Analyze, Regression, Linear
2. Masukkan X1 dan X2 ke kolom Independent(s) dan Y ke kolom Dependent
3. Statistics, dan centang Collinierity Diagnostics (ini untuk uji multikolinieritas), Continue
4. Klik Plot, masukkkan ZRESID ke kolom Y dan ZPRED ke kolom X (ini untuk uji heteroskedastisitas visual)
5. Centang Histogram dan Normal probability plot (ini untuk uji normalitas visual), Continue
6. Pilih Save, centang Standardized pada kotak Residual, ini untuk menyimpan nilai residual atau error dimana nantinya data ini digunakan untuk melakukan uji normalitas dan hetersoskedastisitas secara statistics, lalu tekan tanda x (silang)
7. OK
Butir nomor empat di atas adalah prosedur uji heteroskedastisitassecara visual. Hasil uji heteroskedastisitas visual tertera pada gambar berikut ini
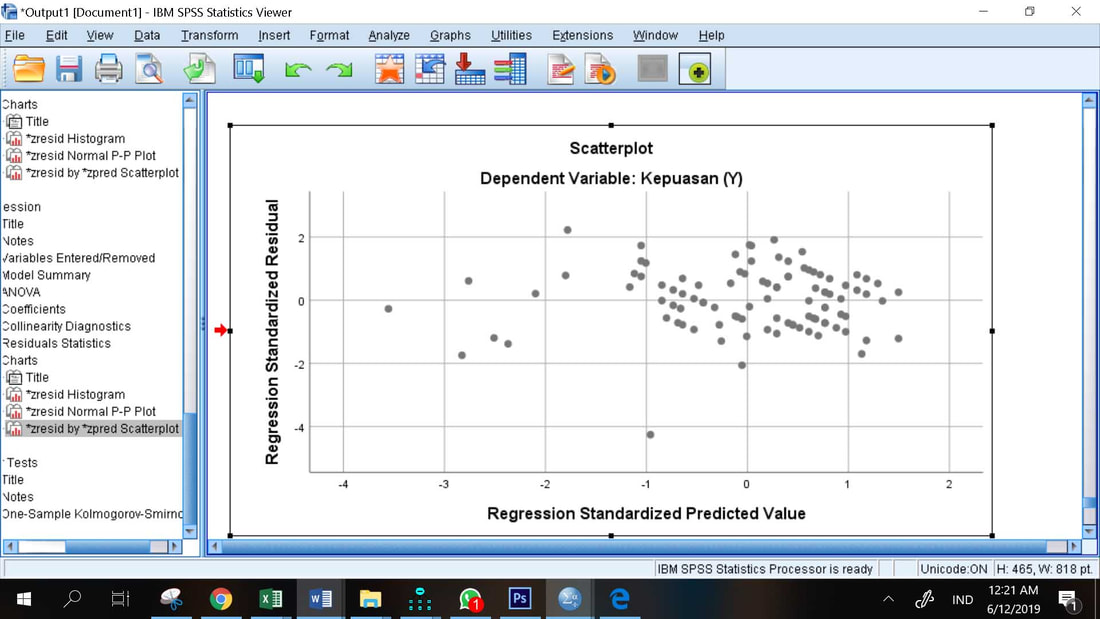
Uji Heteroskedastisitas secara Visual
Pendeteksian ada tidaknya heteroskedastisitas dilakukan dengan cara melihat diagram pencarnya (scatterplot diagram). Bila ada pola tertentu, seperti titik-titik yang membentuk suatu pola tertentu dan teratur (bergelombang, melebar kemudian menyempit) maka terjadi heteroskedastisitas. Jika tidak ada pola yang jelas, serta titik-titik menyebar maka tidak terjadi heteroskedastisitas. Berdasarkan diagram scatterplot di atas, terlihat bahwa data tidak membentuk suatu pola tertentu (berpencar tidak teratur). Hal ini berarti model penelitian terbebas dari masalah heterokedastisitas.
E. Prosedur Uji Heteroskedastisitas Secara Statistik
Heteroskedastisitas adalah kondisi dimana seluruh faktor gangguan tidak memiliki varian yang sama. Heteroskedastisitas akan menyebabkan penaksiran koefisien-koefisien regresi menjadi tidak efisien. Ada beberapa cara untuk melakukan uji heteroskedastisitas. Prosedur Uji Heteroskedastisitas yang akan dijelaskan di sini adalah Uji Glejser. Pendeteksian ada tidaknya heteroskedastisitas mengunakan uji Glejser dengan meregresikan nilai absolute residual terhadap variabel independen.
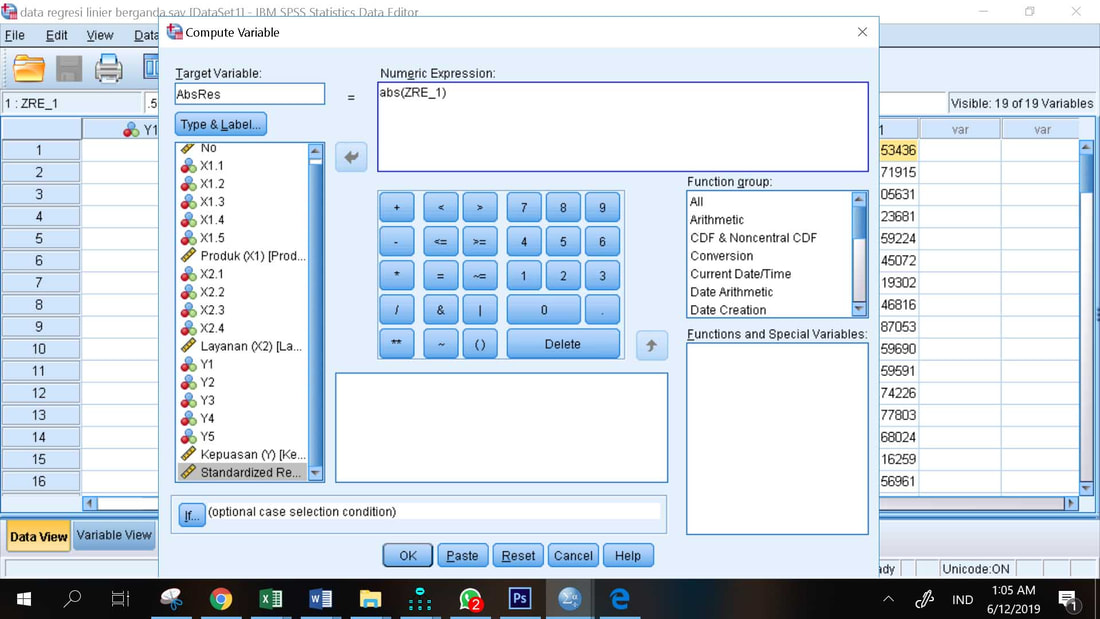
1. Transform, Compute variabel
2. Masukkan nama variabel AbsRes, ini dimaksudkan untuk membuat sebuah variabel baru dengan nama AbsRes (bisa dengan nama lain), yang merupakan nilai absolut dari nilai Standardized Residual yang telah dihasilkan dari perintah Save pada prosedur uji normallitas statistik.
3. Ketik "abs(" lalu Klik dan geser variabel Standardized Residual ke kotak Numeric Expression, lalu ketik lagi ")", sehingga variabel ZRE_1 ada dalam "abs(ZRE_1)"
4. OK
Pendeteksian ada tidaknya heteroskedastisitas dilakukan dengan cara melihat diagram pencarnya (scatterplot diagram). Bila ada pola tertentu, seperti titik-titik yang membentuk suatu pola tertentu dan teratur (bergelombang, melebar kemudian menyempit) maka terjadi heteroskedastisitas. Jika tidak ada pola yang jelas, serta titik-titik menyebar maka tidak terjadi heteroskedastisitas. Berdasarkan diagram scatterplot di atas, terlihat bahwa data tidak membentuk suatu pola tertentu (berpencar tidak teratur). Hal ini berarti model penelitian terbebas dari masalah heterokedastisitas.
E. Prosedur Uji Heteroskedastisitas Secara Statistik
Heteroskedastisitas adalah kondisi dimana seluruh faktor gangguan tidak memiliki varian yang sama. Heteroskedastisitas akan menyebabkan penaksiran koefisien-koefisien regresi menjadi tidak efisien. Ada beberapa cara untuk melakukan uji heteroskedastisitas. Prosedur Uji Heteroskedastisitas yang akan dijelaskan di sini adalah Uji Glejser. Pendeteksian ada tidaknya heteroskedastisitas mengunakan uji Glejser dengan meregresikan nilai absolute residual terhadap variabel independen.
1. Transform, Compute variabel
2. Masukkan nama variabel AbsRes, ini dimaksudkan untuk membuat sebuah variabel baru dengan nama AbsRes (bisa dengan nama lain), yang merupakan nilai absolut dari nilai Standardized Residual yang telah dihasilkan dari perintah Save pada prosedur uji normallitas statistik.
3. Ketik "abs(" lalu Klik dan geser variabel Standardized Residual ke kotak Numeric Expression, lalu ketik lagi ")", sehingga variabel ZRE_1 ada dalam "abs(ZRE_1)"
4. OK
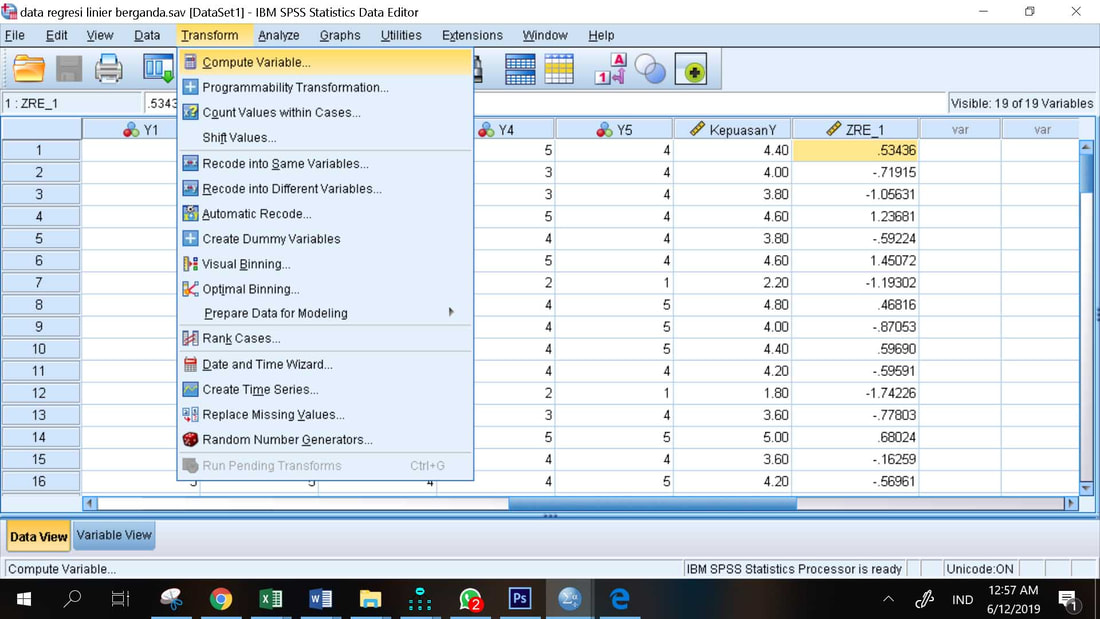
Maka di data pada bagian akhir setelah data Standardized Residual, ada variabel dengan nama AbsRes yang merupakan nilai mutlak dari nilai Standardized Residual
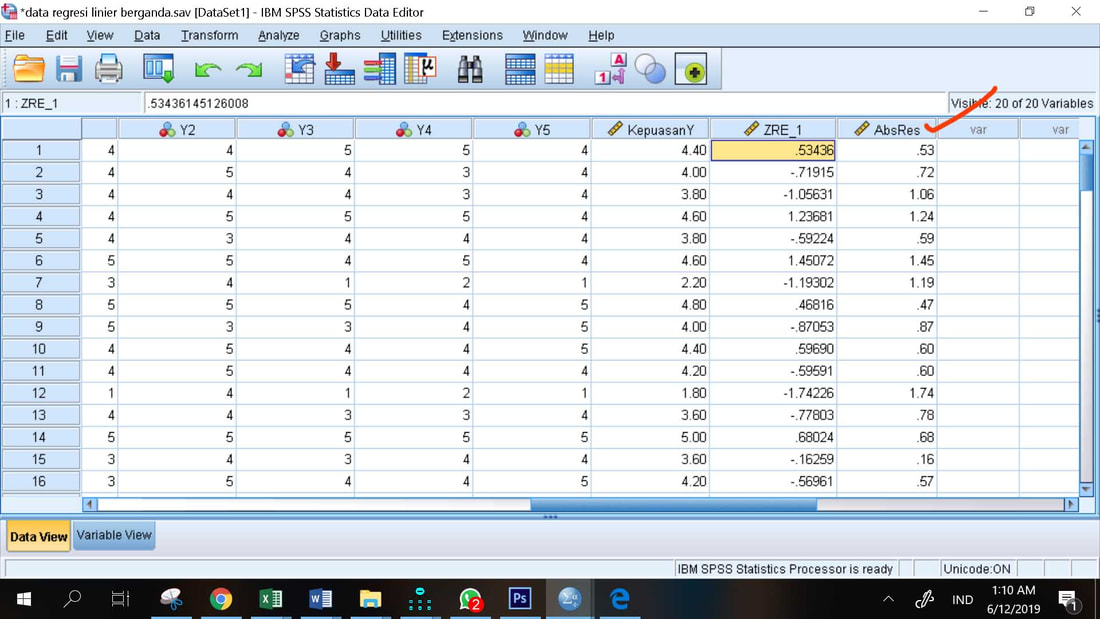
Nilai AbsRes inilah yang diregresikan dengan variabel independen X1 dan X2
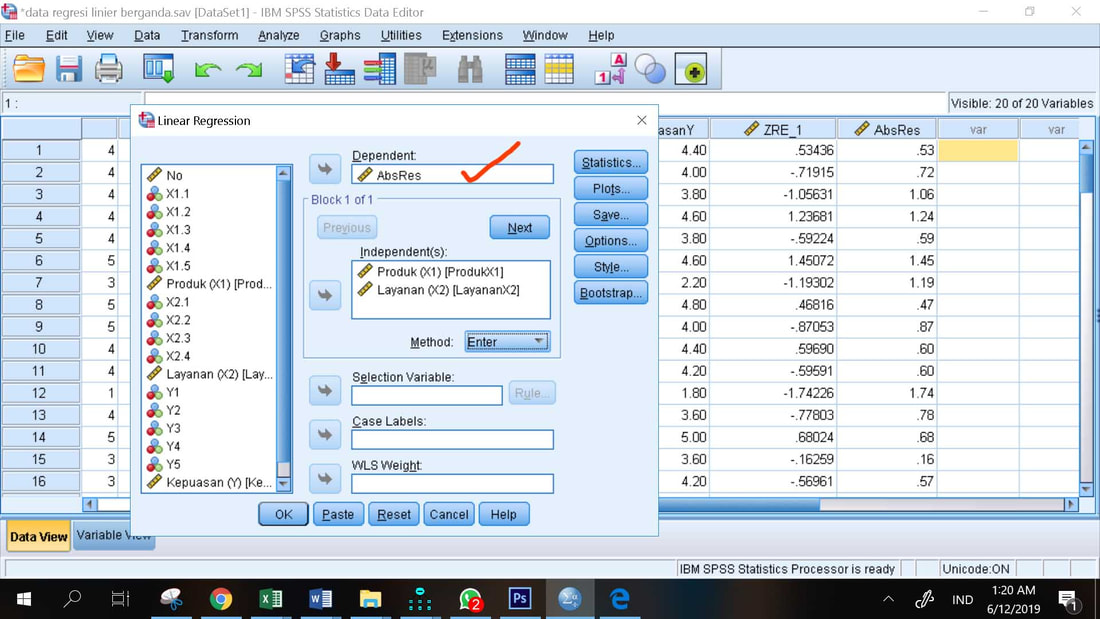
1. Analyze, Regression, Linear
2. Masukkan AbsRes ke kotak Dependent dan X1, X2 ke kotak Independent
3. OK
1. Analyze, Regression, Linear
2. Masukkan AbsRes ke kotak Dependent dan X1, X2 ke kotak Independent
3. OK
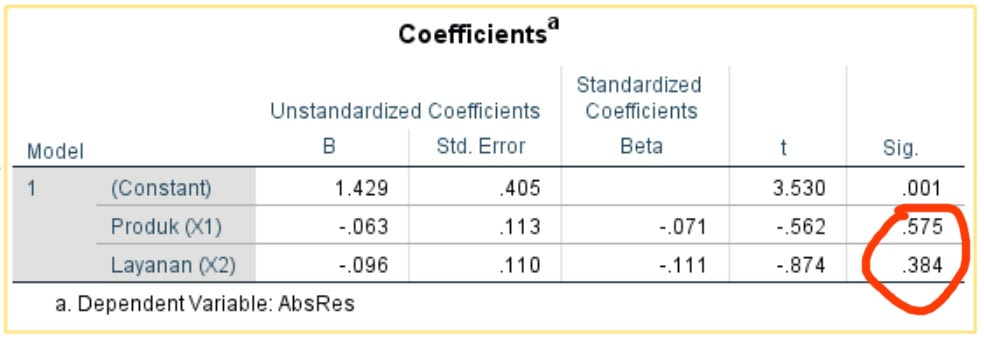
Hipotesis:
H0: tidak terjadi heteroskedastisitas
H1: terjadi heteroskedastisitas
Dasar Pengambilan Keputusan
Jika probabilitasnya (nilai sig) > 0.05 maka H0 tidak ditolak
Jika probabilitasnya (nilai sig) < 0.05 maka H0 ditolak
Keputusan:
Pada tabel di atas nilai sig variabel X1 dan X2 adalah 0.658 dan 0.516 dimana keduanya > 0.05, sehingga H0 tidak ditolak, yang berarti tidak terjadi heteroskedastisitas pada variable X1 dan X2
H0: tidak terjadi heteroskedastisitas
H1: terjadi heteroskedastisitas
Dasar Pengambilan Keputusan
Jika probabilitasnya (nilai sig) > 0.05 maka H0 tidak ditolak
Jika probabilitasnya (nilai sig) < 0.05 maka H0 ditolak
Keputusan:
Pada tabel di atas nilai sig variabel X1 dan X2 adalah 0.658 dan 0.516 dimana keduanya > 0.05, sehingga H0 tidak ditolak, yang berarti tidak terjadi heteroskedastisitas pada variable X1 dan X2

Beberapa alasan menggunakan Jasa Olah Data SPSS kami:
- Pengolahan data atau olah data SPSS disupervisi oleh dosen senior mata kuliah statistik dan metodologi penelitian di program doktor dan magister.
- Hasil pengolahan data, olah data statistik atau olah data SPSS diberikan interpretasi yang rinci sehingga bisa dijadikan komponen utama bab 4 atau bab hasil dan pembahasan
- Mahasiswa diberikan penjelasan via telpon dan atau tatap muka langsung dengan konsultan statistik atau ahli statistik (Jakarta, Depok, Bogor, Bekasi, Tangerang dan sekitarnya)
- Biaya terjangkau dan dibayar setelah hasil pengolahan data atau olah data statistik disampaikan, sehingga mahasiswa tidak menanggung resiko. Reputasi, pengalaman dan kompetensi para pengelola sangat perlu dipertimbangkan untuk menentukan pilihan jasa olah data statistik dengan SPSS secara online, tidak saja mempertimbangkan masalah biaya atau harga murah atau biaya murah saja.
Biasanya pengolahan data atau olah data statistik (olah data spss) berupa analisis regresi linier berganda, analysis variance (ANOVA), rancangan percobaan (design experiment), analisis model persamaan simultan, structural equation modeling (SEM), model linier programming ataupun model kuantitatif lainnya.Untuk permintaan jasa pengolahan data, Anda tinggal kirimkan via email data Anda dan sampaikan analisis apa yang Anda atau dosen Anda inginkan. Hasil analisis akan disampaikan berikut penjelasannya secara tertulis dan penjelasan lisan dengan media komunikasi bila dibutuhkan.
Pada umumnya penelitian dengan metoda kuantitatif meliputi serangkaian pengujian dan analisis data antara lain:
Berbekal pengalaman sebagai konsultan dan dosen pengajar metoda penelitian, ekonomi manajerial, statistika dan ekonometrika di program doktor ekonomi dan program magister di Jakarta, Insya Allah kami bisa menyelesaikan persoalan penelitian atau olah data statistik yang Anda hadapi.
Jasa Olah Data SPSS
Jalan Borobudur 7D, Jakarta Pusat
Tel. 021 – 7777 379
Mobile/SMS/WA : 08159696995, 087784673150
Email: [email protected]
Pada umumnya penelitian dengan metoda kuantitatif meliputi serangkaian pengujian dan analisis data antara lain:
- Uji instrumen penelitian atau kuesioner (uji Reliabilitas dan uji Validitas),
- Uji asumsi dasar (uji Normalitas, Homogenitas, Linieritas)
- Uji penyimpangan asumsi klasik (Multikolinearitas, Heteroskedastisitas, Autokorelasi),
- Regresi Linier
- Regresi Logistik
- Anova (Analysis of Variance)
- Path Analysis
- Structural Equation Modeling (SEM)
Berbekal pengalaman sebagai konsultan dan dosen pengajar metoda penelitian, ekonomi manajerial, statistika dan ekonometrika di program doktor ekonomi dan program magister di Jakarta, Insya Allah kami bisa menyelesaikan persoalan penelitian atau olah data statistik yang Anda hadapi.
Jasa Olah Data SPSS
Jalan Borobudur 7D, Jakarta Pusat
Tel. 021 – 7777 379
Mobile/SMS/WA : 08159696995, 087784673150
Email: [email protected]

Jln. Borobudur No. 7D Jakarta Pusat
Tel. 021 - 7777 379 Mobile/SMS/WA : 08159696995 dan 087784673150 Email: [email protected] |
Contoh hasil analisis data dan interpretasinya
| ||||
Cakupan wilayah jasa olah data statistik menggunakan SPSS, Eviews, Amos, Lisrel, Smart PLS: Jakarta Timur Surabaya Medan Bekasi Bandung Jakarta Barat Jakarta Selatan Makassar Jakarta Utara Depok Semarang Tangerang Palembang Tangerang Selatan Bandar Lampung Jakarta Pusat Batam Bogor Padang Pekanbaru Malang Samarinda Tasikmalaya Pontianak Banjarmasin Denpasar Serang Jambi Balikpapan Surakarta Cimahi Manado Kupang Jayapura Mataram Yogyakarta Cilegon Ambon Bengkulu Palu Kendari Sukabumi Cirebon Pekalongan Kediri Pematangsiantar Tegal Sorong Binjai Dumai Palangka Raya Banda Aceh Singkawang Probolinggo Padang Sidempuan Bitung Banjarbaru Ternate Lubuklinggau Pasuruan Tanjungpinang Pangkalpinang Madiun Tarakan Batu Gorontalo Banjar Lhokseumawe Prabumulih Palopo Langsa Salatiga Parepare Tebing Tinggi Tanjungbalai Metro Bontang Baubau Blitar Gunungsitoli Bima Pagar Alam Mojokerto Payakumbuh Magelang Kotamobagu Bukittinggi Tidore Kepulauan Sungaipenuh Tomohon Sibolga Pariaman Tual Subulussalam Solok Sawahlunto Padang Panjang Sabang
Penggunaan SPSS dalam riset kuantitatif untuk skripsi, tesis, dan disertasi telah menjadi hal yang sangat umum. SPSS (Statistical Package for Social Sciences) merupakan salah satu perangkat lunak yang paling banyak digunakan untuk analisis data kuantitatif di berbagai disiplin ilmu. Peran jasa olah data SPSS sangat penting dalam membantu riset kuantitatif untuk mencapai tujuan yang diinginkan. Artikel ini akan membahas secara detail tentang peran jasa olah data SPSS dalam membantu riset kuantitatif untuk skripsi, tesis, dan disertasi.
Mengolah Data
Peran utama jasa olah data SPSS adalah membantu dalam mengolah data. Olah data dilakukan untuk memeriksa kualitas data, mengisi data yang kosong atau hilang, menghapus data yang tidak relevan, dan mengecek distribusi data. Jasa olah data SPSS akan membantu peneliti untuk membersihkan dan mengorganisir data agar dapat digunakan untuk analisis selanjutnya.
Analisis Deskriptif
Jasa olah data SPSS akan membantu peneliti dalam melakukan analisis deskriptif. Analisis deskriptif digunakan untuk memahami dan menjelaskan data yang telah dikumpulkan. Dalam analisis deskriptif, jasa olah data SPSS akan membantu untuk membuat tabel, grafik, dan diagram yang mampu memberikan gambaran tentang data yang telah dikumpulkan.
Analisis Inferensial
Jasa olah data SPSS juga sangat penting dalam melakukan analisis inferensial. Analisis inferensial digunakan untuk memahami dan menjelaskan hubungan antara variabel-variabel tertentu. Dalam analisis inferensial, jasa olah data SPSS akan membantu peneliti untuk melakukan uji hipotesis, analisis regresi, dan analisis varian. Analisis inferensial akan membantu peneliti dalam mengambil kesimpulan dan membuat rekomendasi berdasarkan hasil analisis data yang telah dilakukan.
Interpretasi Hasil Analisis
Jasa olah data SPSS juga akan membantu dalam melakukan interpretasi hasil analisis. Interpretasi hasil analisis adalah salah satu tahap penting dalam riset kuantitatif. Hasil analisis yang telah didapatkan harus diinterpretasikan agar dapat memberikan pemahaman yang jelas tentang data yang telah dikumpulkan. Dalam tahap interpretasi, jasa olah data SPSS akan membantu peneliti untuk menggambarkan hasil analisis dalam bentuk naratif yang mudah dipahami oleh pembaca.
Kesimpulan
Dalam riset kuantitatif untuk skripsi, tesis, dan disertasi, peran jasa olah data SPSS sangat penting dalam membantu peneliti untuk mencapai tujuan yang diinginkan. Jasa olah data SPSS akan membantu peneliti dalam mengolah data, melakukan analisis deskriptif dan inferensial, serta melakukan interpretasi hasil analisis. Dengan bantuan jasa olah data SPSS, peneliti dapat melakukan analisis data secara efisien dan akurat, sehingga dapat menghasilkan hasil penelitian yang berkualitas.
Mengolah Data
Peran utama jasa olah data SPSS adalah membantu dalam mengolah data. Olah data dilakukan untuk memeriksa kualitas data, mengisi data yang kosong atau hilang, menghapus data yang tidak relevan, dan mengecek distribusi data. Jasa olah data SPSS akan membantu peneliti untuk membersihkan dan mengorganisir data agar dapat digunakan untuk analisis selanjutnya.
Analisis Deskriptif
Jasa olah data SPSS akan membantu peneliti dalam melakukan analisis deskriptif. Analisis deskriptif digunakan untuk memahami dan menjelaskan data yang telah dikumpulkan. Dalam analisis deskriptif, jasa olah data SPSS akan membantu untuk membuat tabel, grafik, dan diagram yang mampu memberikan gambaran tentang data yang telah dikumpulkan.
Analisis Inferensial
Jasa olah data SPSS juga sangat penting dalam melakukan analisis inferensial. Analisis inferensial digunakan untuk memahami dan menjelaskan hubungan antara variabel-variabel tertentu. Dalam analisis inferensial, jasa olah data SPSS akan membantu peneliti untuk melakukan uji hipotesis, analisis regresi, dan analisis varian. Analisis inferensial akan membantu peneliti dalam mengambil kesimpulan dan membuat rekomendasi berdasarkan hasil analisis data yang telah dilakukan.
Interpretasi Hasil Analisis
Jasa olah data SPSS juga akan membantu dalam melakukan interpretasi hasil analisis. Interpretasi hasil analisis adalah salah satu tahap penting dalam riset kuantitatif. Hasil analisis yang telah didapatkan harus diinterpretasikan agar dapat memberikan pemahaman yang jelas tentang data yang telah dikumpulkan. Dalam tahap interpretasi, jasa olah data SPSS akan membantu peneliti untuk menggambarkan hasil analisis dalam bentuk naratif yang mudah dipahami oleh pembaca.
Kesimpulan
Dalam riset kuantitatif untuk skripsi, tesis, dan disertasi, peran jasa olah data SPSS sangat penting dalam membantu peneliti untuk mencapai tujuan yang diinginkan. Jasa olah data SPSS akan membantu peneliti dalam mengolah data, melakukan analisis deskriptif dan inferensial, serta melakukan interpretasi hasil analisis. Dengan bantuan jasa olah data SPSS, peneliti dapat melakukan analisis data secara efisien dan akurat, sehingga dapat menghasilkan hasil penelitian yang berkualitas.
Tentang SPSS
Apa itu SPSS?
SPSS adalah kependekan dari Statistical Package for the Social Sciences (Paket Statistik untuk Ilmu Sosial), dan itu digunakan oleh berbagai jenis peneliti untuk analisis data statistik yang kompleks.
Paket perangkat lunak SPSS dibuat untuk manajemen dan analisis statistik data ilmu sosial. Awalnya diluncurkan pada tahun 1968 oleh SPSS Inc., dan kemudian diakuisisi oleh IBM pada tahun 2009.
Dijuluki secara resmi IBM SPSS Statistics, sebagian besar pengguna masih menyebutnya sebagai SPSS. Sebagai standar dunia untuk analisis data ilmu sosial, SPSS sangat didambakan karena bahasa perintahnya yang lugas dan mirip bahasa Inggris serta panduan pengguna yang sangat teliti.
SPSS digunakan oleh para peneliti pasar, peneliti kesehatan, perusahaan survei, entitas pemerintah, peneliti pendidikan, organisasi pemasaran, penambang data, dan banyak lagi untuk memproses dan menganalisis data survei.
Sementara SurveyGizmo memiliki fitur pelaporan bawaan yang kuat, ketika sampai pada analisis statistik mendalam, peneliti menganggap SPSS solusi terbaik di kelasnya.
Sebagian besar lembaga penelitian top menggunakan SPSS untuk menganalisis data survei dan menambang data teks sehingga mereka bisa mendapatkan hasil maksimal dari proyek penelitian mereka.
Fungsi Inti dari SPSS
SPSS menawarkan empat program yang membantu peneliti dengan kebutuhan analisis data mereka yang kompleks.
Program Statistik
Program Statistik SPSS menyediakan sejumlah besar fungsi statistik dasar, beberapa di antaranya termasuk frekuensi, tabulasi silang, dan statistik bivariat.
Program Modeler
Program Modeler SPSS memungkinkan peneliti untuk membangun dan memvalidasi model prediksi menggunakan prosedur statistik canggih.
Analisis Teks untuk Program Survei
Program SPSS's Text Analytics for Surveys membantu administrator survei mengungkap wawasan yang kuat dari respons terhadap pertanyaan survei terbuka.
Desainer Visualisasi
Program Desainer Visualisasi SPSS memungkinkan para peneliti untuk menggunakan data mereka untuk membuat berbagai macam visual seperti grafik kerapatan dan plot box radial dengan mudah.
Selain empat program yang disebutkan di atas, SPSS juga menyediakan solusi untuk manajemen data, yang memungkinkan para peneliti untuk melakukan pemilihan kasus, membuat data turunan, dan melakukan pembentukan kembali file.
SPSS juga menawarkan solusi fitur dokumentasi data, yang memungkinkan para peneliti untuk menyimpan kamus metadata. Kamus metadata ini bertindak sebagai repositori terpusat dari informasi yang berkaitan dengan data seperti makna, hubungan dengan data lain, asal, penggunaan, dan format.
Ada beberapa metode statistik yang dapat dimanfaatkan dalam SPSS, termasuk:
Statistik deskriptif, termasuk metodologi seperti frekuensi, tabulasi silang, dan statistik rasio deskriptif.
Statistik bivariat, termasuk metodologi seperti analisis varians (ANOVA), berarti, korelasi, dan tes nonparametrik.
Prediksi hasil angka seperti regresi linier.
Prediksi untuk mengidentifikasi kelompok, termasuk metodologi seperti analisis kluster dan analisis faktor.
Manfaat Menggunakan SPSS untuk Analisis Data Survei
Berkat penekanannya pada analisis data statistik, SPSS adalah alat yang sangat kuat untuk memanipulasi dan menguraikan data survei.
Fakta menyenangkan: Data dari survei apa pun yang dikumpulkan melalui SurveyGizmo dapat diekspor ke SPSS untuk analisis terperinci.
Mengekspor data survei ke format .SAV milik SPSS membuat proses menarik, memanipulasi, dan menganalisis data menjadi bersih dan mudah.
Dengan melakukan itu, SPSS akan secara otomatis mengatur dan mengimpor nama variabel yang ditunjuk, tipe variabel, judul, dan label nilai, yang berarti diperlukan kerja keras minimal dari peneliti.
Setelah data survei diekspor ke SPSS, peluang untuk analisis statistik praktis tidak terbatas.
Singkatnya, ingatlah untuk menggunakan SPSS ketika Anda membutuhkan cara yang fleksibel dan dapat disesuaikan untuk mendapatkan super granular pada set data yang paling kompleks sekalipun. Ini memberi Anda, peneliti, lebih banyak waktu untuk melakukan yang terbaik dan mengidentifikasi tren, mengembangkan model prediksi, dan menarik kesimpulan yang tepat.Para pengembang Paket Statistik untuk Ilmu Sosial (SPSS) membuat setiap usaha untuk membuat perangkat lunak mudah digunakan. Ini mencegah Anda dari membuat kesalahan atau bahkan melupakan sesuatu. Itu bukan untuk mengatakan itu tidak mungkin untuk melakukan sesuatu yang salah, namun software SPSS bekerja keras untuk menjaga Anda dari berjalan ke parit. Untuk busuk segalanya, Anda hampir harus bekerja di mencari tahu cara melakukan sesuatu yang salah.
Anda selalu mulai dengan mendefinisikan satu set variabel, dan kemudian Anda memasukkan data untuk variabel untuk membuat sejumlah kasus. Misalnya, jika Anda melakukan analisis mobil, masing-masing mobil dalam studi Anda akan kasus. Variabel yang menentukan kasus bisa menjadi hal-hal seperti tahun pembuatan, tenaga kuda, dan inci kubik perpindahan. Setiap mobil dalam penelitian ini didefinisikan sebagai satu kasus, dan setiap kasus didefinisikan sebagai seperangkat nilai-nilai ditugaskan untuk koleksi variabel. Setiap kasus memiliki nilai untuk setiap variabel. (Nah, Anda dapat memiliki nilai yang hilang, tapi itu situasi khusus dijelaskan kemudian.).
Artinya, masing-masing variabel didefinisikan sebagai mengandung jenis tertentu jumlah. Misalnya, variabel skala adalah pengukuran numerik, seperti berat atau mil per galon. Variabel kategoris mengandung nilai-nilai yang mendefinisikan kategori; misalnya, variabel bernama jender bisa menjadi variabel kategoris didefinisikan hanya berisi nilai 1 untuk perempuan dan 2 laki-laki untuk. Hal-hal yang masuk akal untuk satu jenis variabel tidak selalu masuk akal bagi orang lain. Misalnya, masuk akal untuk menghitung mil per galon rata, tapi bukan jenis kelamin rata-rata.
Setelah data Anda masuk ke SPSS - kasus Anda semua ditentukan oleh nilai-nilai yang tersimpan dalam variabel - Anda dapat menjalankan analisis. Anda sudah selesai bagian yang sulit. Menjalankan analisis data jauh lebih mudah daripada memasukkan data. Untuk menjalankan analisis, Anda pilih salah satu yang ingin menjalankan dari menu, pilih variabel yang sesuai, dan klik tombol OK. SPSS membaca melalui semua kasus Anda, melakukan analisis, dan menyajikan anda dengan output.
Anda dapat menginstruksikan SPSS untuk menarik grafik dan diagram dengan cara yang sama Anda menginstruksikan untuk melakukan analisis. Anda pilih grafik yang diinginkan dari menu, menetapkan variabel untuk itu, dan klik OK.
Ketika mempersiapkan SPSS untuk menjalankan analisis atau menggambar grafik, tombol OK tidak tersedia sampai Anda telah membuat semua pilihan yang diperlukan untuk menghasilkan output. Tidak hanya SPSS mengharuskan Anda memilih jumlah yang memadai variabel untuk menghasilkan output, itu juga mensyaratkan bahwa Anda memilih jenis yang tepat dari variabel. Jika variabel kategoris diperlukan untuk slot tertentu, SPSS tidak akan memungkinkan Anda untuk memilih jenis lain. Apakah output masuk akal terserah Anda dan data Anda, tetapi SPSS membuat yakin bahwa pilihan yang Anda buat dapat digunakan untuk memproduksi beberapa jenis hasil.
Semua keluaran dari SPSS pergi ke tempat yang sama - sebuah kotak dialog bernama SPSS Viewer. Ini membuka untuk menampilkan hasil apa pun yang Anda lakukan. Setelah Anda memiliki output, jika Anda melakukan beberapa tindakan yang menghasilkan lebih banyak output, output baru ditampilkan dalam kotak dialog yang sama. Dan hampir apa pun yang Anda lakukan menghasilkan output.
Bagaimana SPSS (statistik Paket untuk Ilmu Sosial) Bekerja Dengan Arthur Griffith dari SPSS For Dummies Para pengembang Paket Statistik untuk Ilmu Sosial (SPSS) membuat setiap usaha untuk membuat perangkat lunak mudah digunakan. Ini mencegah Anda dari membuat kesalahan atau bahkan melupakan sesuatu. Itu bukan untuk mengatakan itu tidak mungkin untuk melakukan sesuatu yang salah, namun software SPSS bekerja keras untuk menjaga Anda dari berjalan ke parit. Untuk busuk segalanya, Anda hampir harus bekerja di mencari tahu cara melakukan sesuatu yang salah. Anda selalu mulai dengan mendefinisikan satu set variabel, dan kemudian Anda memasukkan data untuk variabel untuk membuat sejumlah kasus. Misalnya, jika Anda melakukan analisis mobil, masing-masing mobil dalam studi Anda akan kasus. Variabel yang menentukan kasus bisa menjadi hal-hal seperti tahun pembuatan, tenaga kuda, dan inci kubik perpindahan. Setiap mobil dalam penelitian ini didefinisikan sebagai satu kasus, dan setiap kasus didefinisikan sebagai seperangkat nilai-nilai ditugaskan untuk koleksi variabel. Setiap kasus memiliki nilai untuk setiap variabel. (Nah, Anda dapat memiliki nilai yang hilang, tapi itu situasi khusus dijelaskan kemudian.) Variabel memiliki tipe. Artinya, masing-masing variabel didefinisikan sebagai mengandung jenis tertentu jumlah. Misalnya, variabel skala adalah pengukuran numerik, seperti berat atau mil per galon. Variabel kategoris mengandung nilai-nilai yang mendefinisikan kategori; misalnya, variabel bernama jender bisa menjadi variabel kategoris didefinisikan hanya berisi nilai 1 untuk perempuan dan 2 laki-laki untuk. Hal-hal yang masuk akal untuk satu jenis variabel tidak selalu masuk akal bagi orang lain. Misalnya, masuk akal untuk menghitung mil per galon rata, tapi bukan jenis kelamin rata-rata. Setelah data Anda masuk ke SPSS - kasus Anda semua ditentukan oleh nilai-nilai yang tersimpan dalam variabel - Anda dapat menjalankan analisis. Anda sudah selesai bagian yang sulit. Menjalankan analisis data jauh lebih mudah daripada memasukkan data. Untuk menjalankan analisis, Anda pilih salah satu yang ingin menjalankan dari menu, pilih variabel yang sesuai, dan klik tombol OK. SPSS membaca melalui semua kasus Anda, melakukan analisis, dan menyajikan anda dengan output. Anda dapat menginstruksikan SPSS untuk menarik grafik dan diagram dengan cara yang sama Anda menginstruksikan untuk melakukan analisis. Anda pilih grafik yang diinginkan dari menu, menetapkan variabel untuk itu, dan klik OK. Ketika mempersiapkan SPSS untuk menjalankan analisis atau menggambar grafik, tombol OK tidak tersedia sampai Anda telah membuat semua pilihan yang diperlukan untuk menghasilkan output. Tidak hanya SPSS mengharuskan Anda memilih jumlah yang memadai variabel untuk menghasilkan output, itu juga mensyaratkan bahwa Anda memilih jenis yang tepat dari variabel. Jika variabel kategoris diperlukan untuk slot tertentu, SPSS tidak akan memungkinkan Anda untuk memilih jenis lain. Apakah output masuk akal terserah Anda dan data Anda, tetapi SPSS membuat yakin bahwa pilihan yang Anda buat dapat digunakan untuk memproduksi beberapa jenis hasil. Semua keluaran dari SPSS pergi ke tempat yang sama - sebuah kotak dialog bernama SPSS Viewer. Ini membuka untuk menampilkan hasil apa pun yang Anda lakukan. Setelah Anda memiliki output, jika Anda melakukan beberapa tindakan yang menghasilkan lebih banyak output, output baru ditampilkan dalam kotak dialog yang sama. Dan hampir apa pun yang Anda lakukan menghasilkan output.
Para pengembang Paket Statistik untuk Ilmu Sosial (SPSS) membuat setiap usaha untuk membuat perangkat lunak mudah digunakan. Ini mencegah Anda dari membuat kesalahan atau bahkan melupakan sesuatu. Itu bukan untuk mengatakan itu tidak mungkin untuk melakukan sesuatu yang salah, namun software SPSS bekerja keras untuk menjaga Anda dari berjalan ke parit. Untuk busuk segalanya, Anda hampir harus bekerja di mencari tahu cara melakukan sesuatu yang salah. Anda selalu mulai dengan mendefinisikan satu set variabel, dan kemudian Anda memasukkan data untuk variabel untuk membuat sejumlah kasus. Misalnya, jika Anda melakukan analisis mobil, masing-masing mobil dalam studi Anda akan kasus. Variabel yang menentukan kasus bisa menjadi hal-hal seperti tahun pembuatan, tenaga kuda, dan inci kubik perpindahan. Setiap mobil dalam penelitian ini didefinisikan sebagai satu kasus, dan setiap kasus didefinisikan sebagai seperangkat nilai-nilai ditugaskan untuk koleksi variabel. Setiap kasus memiliki nilai untuk setiap variabel. (Nah, Anda dapat memiliki nilai yang hilang, tapi itu situasi khusus dijelaskan kemudian.) Variabel memiliki tipe. Artinya, masing-masing variabel didefinisikan sebagai mengandung jenis tertentu jumlah. Misalnya, variabel skala adalah pengukuran numerik, seperti berat atau mil per galon. Variabel kategoris mengandung nilai-nilai yang mendefinisikan kategori; misalnya, variabel bernama jender bisa menjadi variabel kategoris didefinisikan hanya berisi nilai 1 untuk perempuan dan 2 laki-laki untuk. Hal-hal yang masuk akal untuk satu jenis variabel tidak selalu masuk akal bagi orang lain. Misalnya, masuk akal untuk menghitung mil per galon rata, tapi bukan jenis kelamin rata-rata. Setelah data Anda masuk ke SPSS - kasus Anda semua ditentukan oleh nilai-nilai yang tersimpan dalam variabel - Anda dapat menjalankan analisis. Anda sudah selesai bagian yang sulit. Menjalankan analisis data jauh lebih mudah daripada memasukkan data. Untuk menjalankan analisis, Anda pilih salah satu yang ingin menjalankan dari menu, pilih variabel yang sesuai, dan klik tombol OK. SPSS membaca melalui semua kasus Anda, melakukan analisis, dan menyajikan anda dengan output. Anda dapat menginstruksikan SPSS untuk menarik grafik dan diagram dengan cara yang sama Anda menginstruksikan untuk melakukan analisis. Anda pilih grafik yang diinginkan dari menu, menetapkan variabel untuk itu, dan klik OK. Ketika mempersiapkan SPSS untuk menjalankan analisis atau menggambar grafik, tombol OK tidak tersedia sampai Anda telah membuat semua pilihan yang diperlukan untuk menghasilkan output. Tidak hanya SPSS mengharuskan Anda memilih jumlah yang memadai variabel untuk menghasilkan output, itu juga mensyaratkan bahwa Anda memilih jenis yang tepat dari variabel. Jika variabel kategoris diperlukan untuk slot tertentu, SPSS tidak akan memungkinkan Anda untuk memilih jenis lain. Apakah output masuk akal terserah Anda dan data Anda, tetapi SPSS membuat yakin bahwa pilihan yang Anda buat dapat digunakan untuk memproduksi beberapa jenis hasil. Semua keluaran dari SPSS pergi ke tempat yang sama - sebuah kotak dialog bernama SPSS Viewer. Ini membuka untuk menampilkan hasil apa pun yang Anda lakukan. Setelah Anda memiliki output, jika Anda melakukan beberapa tindakan yang menghasilkan lebih banyak output, output baru ditampilkan dalam kotak dialog yang sama. Dan hampir apa pun yang Anda lakukan menghasilkan output.
SPSS adalah kependekan dari Statistical Package for the Social Sciences (Paket Statistik untuk Ilmu Sosial), dan itu digunakan oleh berbagai jenis peneliti untuk analisis data statistik yang kompleks.
Paket perangkat lunak SPSS dibuat untuk manajemen dan analisis statistik data ilmu sosial. Awalnya diluncurkan pada tahun 1968 oleh SPSS Inc., dan kemudian diakuisisi oleh IBM pada tahun 2009.
Dijuluki secara resmi IBM SPSS Statistics, sebagian besar pengguna masih menyebutnya sebagai SPSS. Sebagai standar dunia untuk analisis data ilmu sosial, SPSS sangat didambakan karena bahasa perintahnya yang lugas dan mirip bahasa Inggris serta panduan pengguna yang sangat teliti.
SPSS digunakan oleh para peneliti pasar, peneliti kesehatan, perusahaan survei, entitas pemerintah, peneliti pendidikan, organisasi pemasaran, penambang data, dan banyak lagi untuk memproses dan menganalisis data survei.
Sementara SurveyGizmo memiliki fitur pelaporan bawaan yang kuat, ketika sampai pada analisis statistik mendalam, peneliti menganggap SPSS solusi terbaik di kelasnya.
Sebagian besar lembaga penelitian top menggunakan SPSS untuk menganalisis data survei dan menambang data teks sehingga mereka bisa mendapatkan hasil maksimal dari proyek penelitian mereka.
Fungsi Inti dari SPSS
SPSS menawarkan empat program yang membantu peneliti dengan kebutuhan analisis data mereka yang kompleks.
Program Statistik
Program Statistik SPSS menyediakan sejumlah besar fungsi statistik dasar, beberapa di antaranya termasuk frekuensi, tabulasi silang, dan statistik bivariat.
Program Modeler
Program Modeler SPSS memungkinkan peneliti untuk membangun dan memvalidasi model prediksi menggunakan prosedur statistik canggih.
Analisis Teks untuk Program Survei
Program SPSS's Text Analytics for Surveys membantu administrator survei mengungkap wawasan yang kuat dari respons terhadap pertanyaan survei terbuka.
Desainer Visualisasi
Program Desainer Visualisasi SPSS memungkinkan para peneliti untuk menggunakan data mereka untuk membuat berbagai macam visual seperti grafik kerapatan dan plot box radial dengan mudah.
Selain empat program yang disebutkan di atas, SPSS juga menyediakan solusi untuk manajemen data, yang memungkinkan para peneliti untuk melakukan pemilihan kasus, membuat data turunan, dan melakukan pembentukan kembali file.
SPSS juga menawarkan solusi fitur dokumentasi data, yang memungkinkan para peneliti untuk menyimpan kamus metadata. Kamus metadata ini bertindak sebagai repositori terpusat dari informasi yang berkaitan dengan data seperti makna, hubungan dengan data lain, asal, penggunaan, dan format.
Ada beberapa metode statistik yang dapat dimanfaatkan dalam SPSS, termasuk:
Statistik deskriptif, termasuk metodologi seperti frekuensi, tabulasi silang, dan statistik rasio deskriptif.
Statistik bivariat, termasuk metodologi seperti analisis varians (ANOVA), berarti, korelasi, dan tes nonparametrik.
Prediksi hasil angka seperti regresi linier.
Prediksi untuk mengidentifikasi kelompok, termasuk metodologi seperti analisis kluster dan analisis faktor.
Manfaat Menggunakan SPSS untuk Analisis Data Survei
Berkat penekanannya pada analisis data statistik, SPSS adalah alat yang sangat kuat untuk memanipulasi dan menguraikan data survei.
Fakta menyenangkan: Data dari survei apa pun yang dikumpulkan melalui SurveyGizmo dapat diekspor ke SPSS untuk analisis terperinci.
Mengekspor data survei ke format .SAV milik SPSS membuat proses menarik, memanipulasi, dan menganalisis data menjadi bersih dan mudah.
Dengan melakukan itu, SPSS akan secara otomatis mengatur dan mengimpor nama variabel yang ditunjuk, tipe variabel, judul, dan label nilai, yang berarti diperlukan kerja keras minimal dari peneliti.
Setelah data survei diekspor ke SPSS, peluang untuk analisis statistik praktis tidak terbatas.
Singkatnya, ingatlah untuk menggunakan SPSS ketika Anda membutuhkan cara yang fleksibel dan dapat disesuaikan untuk mendapatkan super granular pada set data yang paling kompleks sekalipun. Ini memberi Anda, peneliti, lebih banyak waktu untuk melakukan yang terbaik dan mengidentifikasi tren, mengembangkan model prediksi, dan menarik kesimpulan yang tepat.Para pengembang Paket Statistik untuk Ilmu Sosial (SPSS) membuat setiap usaha untuk membuat perangkat lunak mudah digunakan. Ini mencegah Anda dari membuat kesalahan atau bahkan melupakan sesuatu. Itu bukan untuk mengatakan itu tidak mungkin untuk melakukan sesuatu yang salah, namun software SPSS bekerja keras untuk menjaga Anda dari berjalan ke parit. Untuk busuk segalanya, Anda hampir harus bekerja di mencari tahu cara melakukan sesuatu yang salah.
Anda selalu mulai dengan mendefinisikan satu set variabel, dan kemudian Anda memasukkan data untuk variabel untuk membuat sejumlah kasus. Misalnya, jika Anda melakukan analisis mobil, masing-masing mobil dalam studi Anda akan kasus. Variabel yang menentukan kasus bisa menjadi hal-hal seperti tahun pembuatan, tenaga kuda, dan inci kubik perpindahan. Setiap mobil dalam penelitian ini didefinisikan sebagai satu kasus, dan setiap kasus didefinisikan sebagai seperangkat nilai-nilai ditugaskan untuk koleksi variabel. Setiap kasus memiliki nilai untuk setiap variabel. (Nah, Anda dapat memiliki nilai yang hilang, tapi itu situasi khusus dijelaskan kemudian.).
Artinya, masing-masing variabel didefinisikan sebagai mengandung jenis tertentu jumlah. Misalnya, variabel skala adalah pengukuran numerik, seperti berat atau mil per galon. Variabel kategoris mengandung nilai-nilai yang mendefinisikan kategori; misalnya, variabel bernama jender bisa menjadi variabel kategoris didefinisikan hanya berisi nilai 1 untuk perempuan dan 2 laki-laki untuk. Hal-hal yang masuk akal untuk satu jenis variabel tidak selalu masuk akal bagi orang lain. Misalnya, masuk akal untuk menghitung mil per galon rata, tapi bukan jenis kelamin rata-rata.
Setelah data Anda masuk ke SPSS - kasus Anda semua ditentukan oleh nilai-nilai yang tersimpan dalam variabel - Anda dapat menjalankan analisis. Anda sudah selesai bagian yang sulit. Menjalankan analisis data jauh lebih mudah daripada memasukkan data. Untuk menjalankan analisis, Anda pilih salah satu yang ingin menjalankan dari menu, pilih variabel yang sesuai, dan klik tombol OK. SPSS membaca melalui semua kasus Anda, melakukan analisis, dan menyajikan anda dengan output.
Anda dapat menginstruksikan SPSS untuk menarik grafik dan diagram dengan cara yang sama Anda menginstruksikan untuk melakukan analisis. Anda pilih grafik yang diinginkan dari menu, menetapkan variabel untuk itu, dan klik OK.
Ketika mempersiapkan SPSS untuk menjalankan analisis atau menggambar grafik, tombol OK tidak tersedia sampai Anda telah membuat semua pilihan yang diperlukan untuk menghasilkan output. Tidak hanya SPSS mengharuskan Anda memilih jumlah yang memadai variabel untuk menghasilkan output, itu juga mensyaratkan bahwa Anda memilih jenis yang tepat dari variabel. Jika variabel kategoris diperlukan untuk slot tertentu, SPSS tidak akan memungkinkan Anda untuk memilih jenis lain. Apakah output masuk akal terserah Anda dan data Anda, tetapi SPSS membuat yakin bahwa pilihan yang Anda buat dapat digunakan untuk memproduksi beberapa jenis hasil.
Semua keluaran dari SPSS pergi ke tempat yang sama - sebuah kotak dialog bernama SPSS Viewer. Ini membuka untuk menampilkan hasil apa pun yang Anda lakukan. Setelah Anda memiliki output, jika Anda melakukan beberapa tindakan yang menghasilkan lebih banyak output, output baru ditampilkan dalam kotak dialog yang sama. Dan hampir apa pun yang Anda lakukan menghasilkan output.
Bagaimana SPSS (statistik Paket untuk Ilmu Sosial) Bekerja Dengan Arthur Griffith dari SPSS For Dummies Para pengembang Paket Statistik untuk Ilmu Sosial (SPSS) membuat setiap usaha untuk membuat perangkat lunak mudah digunakan. Ini mencegah Anda dari membuat kesalahan atau bahkan melupakan sesuatu. Itu bukan untuk mengatakan itu tidak mungkin untuk melakukan sesuatu yang salah, namun software SPSS bekerja keras untuk menjaga Anda dari berjalan ke parit. Untuk busuk segalanya, Anda hampir harus bekerja di mencari tahu cara melakukan sesuatu yang salah. Anda selalu mulai dengan mendefinisikan satu set variabel, dan kemudian Anda memasukkan data untuk variabel untuk membuat sejumlah kasus. Misalnya, jika Anda melakukan analisis mobil, masing-masing mobil dalam studi Anda akan kasus. Variabel yang menentukan kasus bisa menjadi hal-hal seperti tahun pembuatan, tenaga kuda, dan inci kubik perpindahan. Setiap mobil dalam penelitian ini didefinisikan sebagai satu kasus, dan setiap kasus didefinisikan sebagai seperangkat nilai-nilai ditugaskan untuk koleksi variabel. Setiap kasus memiliki nilai untuk setiap variabel. (Nah, Anda dapat memiliki nilai yang hilang, tapi itu situasi khusus dijelaskan kemudian.) Variabel memiliki tipe. Artinya, masing-masing variabel didefinisikan sebagai mengandung jenis tertentu jumlah. Misalnya, variabel skala adalah pengukuran numerik, seperti berat atau mil per galon. Variabel kategoris mengandung nilai-nilai yang mendefinisikan kategori; misalnya, variabel bernama jender bisa menjadi variabel kategoris didefinisikan hanya berisi nilai 1 untuk perempuan dan 2 laki-laki untuk. Hal-hal yang masuk akal untuk satu jenis variabel tidak selalu masuk akal bagi orang lain. Misalnya, masuk akal untuk menghitung mil per galon rata, tapi bukan jenis kelamin rata-rata. Setelah data Anda masuk ke SPSS - kasus Anda semua ditentukan oleh nilai-nilai yang tersimpan dalam variabel - Anda dapat menjalankan analisis. Anda sudah selesai bagian yang sulit. Menjalankan analisis data jauh lebih mudah daripada memasukkan data. Untuk menjalankan analisis, Anda pilih salah satu yang ingin menjalankan dari menu, pilih variabel yang sesuai, dan klik tombol OK. SPSS membaca melalui semua kasus Anda, melakukan analisis, dan menyajikan anda dengan output. Anda dapat menginstruksikan SPSS untuk menarik grafik dan diagram dengan cara yang sama Anda menginstruksikan untuk melakukan analisis. Anda pilih grafik yang diinginkan dari menu, menetapkan variabel untuk itu, dan klik OK. Ketika mempersiapkan SPSS untuk menjalankan analisis atau menggambar grafik, tombol OK tidak tersedia sampai Anda telah membuat semua pilihan yang diperlukan untuk menghasilkan output. Tidak hanya SPSS mengharuskan Anda memilih jumlah yang memadai variabel untuk menghasilkan output, itu juga mensyaratkan bahwa Anda memilih jenis yang tepat dari variabel. Jika variabel kategoris diperlukan untuk slot tertentu, SPSS tidak akan memungkinkan Anda untuk memilih jenis lain. Apakah output masuk akal terserah Anda dan data Anda, tetapi SPSS membuat yakin bahwa pilihan yang Anda buat dapat digunakan untuk memproduksi beberapa jenis hasil. Semua keluaran dari SPSS pergi ke tempat yang sama - sebuah kotak dialog bernama SPSS Viewer. Ini membuka untuk menampilkan hasil apa pun yang Anda lakukan. Setelah Anda memiliki output, jika Anda melakukan beberapa tindakan yang menghasilkan lebih banyak output, output baru ditampilkan dalam kotak dialog yang sama. Dan hampir apa pun yang Anda lakukan menghasilkan output.
Para pengembang Paket Statistik untuk Ilmu Sosial (SPSS) membuat setiap usaha untuk membuat perangkat lunak mudah digunakan. Ini mencegah Anda dari membuat kesalahan atau bahkan melupakan sesuatu. Itu bukan untuk mengatakan itu tidak mungkin untuk melakukan sesuatu yang salah, namun software SPSS bekerja keras untuk menjaga Anda dari berjalan ke parit. Untuk busuk segalanya, Anda hampir harus bekerja di mencari tahu cara melakukan sesuatu yang salah. Anda selalu mulai dengan mendefinisikan satu set variabel, dan kemudian Anda memasukkan data untuk variabel untuk membuat sejumlah kasus. Misalnya, jika Anda melakukan analisis mobil, masing-masing mobil dalam studi Anda akan kasus. Variabel yang menentukan kasus bisa menjadi hal-hal seperti tahun pembuatan, tenaga kuda, dan inci kubik perpindahan. Setiap mobil dalam penelitian ini didefinisikan sebagai satu kasus, dan setiap kasus didefinisikan sebagai seperangkat nilai-nilai ditugaskan untuk koleksi variabel. Setiap kasus memiliki nilai untuk setiap variabel. (Nah, Anda dapat memiliki nilai yang hilang, tapi itu situasi khusus dijelaskan kemudian.) Variabel memiliki tipe. Artinya, masing-masing variabel didefinisikan sebagai mengandung jenis tertentu jumlah. Misalnya, variabel skala adalah pengukuran numerik, seperti berat atau mil per galon. Variabel kategoris mengandung nilai-nilai yang mendefinisikan kategori; misalnya, variabel bernama jender bisa menjadi variabel kategoris didefinisikan hanya berisi nilai 1 untuk perempuan dan 2 laki-laki untuk. Hal-hal yang masuk akal untuk satu jenis variabel tidak selalu masuk akal bagi orang lain. Misalnya, masuk akal untuk menghitung mil per galon rata, tapi bukan jenis kelamin rata-rata. Setelah data Anda masuk ke SPSS - kasus Anda semua ditentukan oleh nilai-nilai yang tersimpan dalam variabel - Anda dapat menjalankan analisis. Anda sudah selesai bagian yang sulit. Menjalankan analisis data jauh lebih mudah daripada memasukkan data. Untuk menjalankan analisis, Anda pilih salah satu yang ingin menjalankan dari menu, pilih variabel yang sesuai, dan klik tombol OK. SPSS membaca melalui semua kasus Anda, melakukan analisis, dan menyajikan anda dengan output. Anda dapat menginstruksikan SPSS untuk menarik grafik dan diagram dengan cara yang sama Anda menginstruksikan untuk melakukan analisis. Anda pilih grafik yang diinginkan dari menu, menetapkan variabel untuk itu, dan klik OK. Ketika mempersiapkan SPSS untuk menjalankan analisis atau menggambar grafik, tombol OK tidak tersedia sampai Anda telah membuat semua pilihan yang diperlukan untuk menghasilkan output. Tidak hanya SPSS mengharuskan Anda memilih jumlah yang memadai variabel untuk menghasilkan output, itu juga mensyaratkan bahwa Anda memilih jenis yang tepat dari variabel. Jika variabel kategoris diperlukan untuk slot tertentu, SPSS tidak akan memungkinkan Anda untuk memilih jenis lain. Apakah output masuk akal terserah Anda dan data Anda, tetapi SPSS membuat yakin bahwa pilihan yang Anda buat dapat digunakan untuk memproduksi beberapa jenis hasil. Semua keluaran dari SPSS pergi ke tempat yang sama - sebuah kotak dialog bernama SPSS Viewer. Ini membuka untuk menampilkan hasil apa pun yang Anda lakukan. Setelah Anda memiliki output, jika Anda melakukan beberapa tindakan yang menghasilkan lebih banyak output, output baru ditampilkan dalam kotak dialog yang sama. Dan hampir apa pun yang Anda lakukan menghasilkan output.
Keunggulan SPSS
Sementara itu tepat bahwa program spreadsheet menawarkan kontrol yang lebih berkaitan dengan organisasi data, ini juga dapat dilihat sebagai kekurangan. Sebaliknya, Anda tidak dapat memindahkan data blok di SPSS seperti yang dimaksudkan untuk mengatur data secara optimal. Baris A merupakan satu kasus, sedangkan kolom menunjukkan satu variabel. SPSS membuat analisis data lebih cepat karena program tahu lokasi kasus dan variabel. Bila menggunakan spreadsheet, pengguna harus secara manual mendefinisikan hubungan ini dalam setiap analisis.
SPSS secara khusus dibuat untuk menganalisis data statistik dan dengan demikian menawarkan berbagai macam metode, grafik dan diagram. Program umum mungkin menawarkan prosedur lain seperti faktur dan akuntansi bentuk, tetapi program khusus yang lebih cocok untuk fungsi ini. SPSS juga dilengkapi dengan teknik yang lebih dari penyaringan atau membersihkan informasi dalam persiapan untuk analisis lebih lanjut. Selanjutnya, program spreadsheet yang normal hanya dapat mendukung analisis data segera setelah instalasi, dengan tambahan plug-in yang diperlukan untuk mengakses teknik yang lebih rumit.
SPSS dirancang untuk memastikan bahwa output disimpan terpisah dari data itu sendiri. Bahkan, ia menyimpan semua hasil dalam file terpisah yang berbeda dari data. Namun, dalam program-program seperti Excel, hasil analisis ditempatkan dalam satu lembar kerja dan ada kemungkinan Timpa informasi lainnya oleh kecelakaan.
Manfaat analisis statistik SPSS dapat dilakukan dengan menggunakan dua metode utama. Salah satunya adalah hanya dengan menggunakan spreadsheet atau manajemen data program umum seperti MS Excel atau melalui menggunakan paket statistik khusus seperti SPSS. Berikut adalah alasan utama mengapa SPSS adalah pilihan terbaik untuk digunakan. Manajemen data yang efektif Meskipun tepat bahwa program spreadsheet menawarkan kontrol yang lebih berkaitan dengan organisasi data, ini juga dapat dilihat sebagai kekurangan. Sebaliknya, Anda tidak dapat memindahkan data blok di SPSS seperti yang dimaksudkan untuk mengatur data secara optimal. Baris A merupakan satu kasus, sedangkan kolom menunjukkan satu variabel. SPSS membuat analisis data lebih cepat karena program tahu lokasi kasus dan variabel. Bila menggunakan spreadsheet, pengguna harus secara manual mendefinisikan hubungan ini dalam setiap analisis. Berbagai pilihan SPSS secara khusus dibuat untuk menganalisis data statistik dan dengan demikian menawarkan berbagai macam metode, grafik dan diagram. Program umum mungkin menawarkan prosedur lain seperti faktur dan akuntansi bentuk, tetapi program khusus yang lebih cocok
untuk fungsi ini. SPSS juga dilengkapi dengan teknik yang lebih dari penyaringan atau membersihkan informasi dalam persiapan untuk analisis lebih lanjut. Selanjutnya, program spreadsheet yang normal hanya dapat mendukung analisis data segera setelah instalasi, dengan tambahan plug-in yang diperlukan untuk mengakses teknik yang lebih rumit. Organisasi output yang lebih baik SPSS dirancang untuk memastikan bahwa output disimpan terpisah dari data itu sendiri. Bahkan, ia menyimpan semua hasil dalam file terpisah yang berbeda dari data. Namun, dalam program-program seperti Excel, hasil analisis ditempatkan dalam satu lembar kerja dan ada kemungkinan Timpa informasi lainnya oleh kecelakaan. Meskipun Excel masih menawarkan cara yang baik untuk organisasi data, menggunakan software khusus seperti SPSS lebih cocok untuk di analisis data mendalam. Berbagi: Berbagi di FacebookClick ke email ini untuk friendClick untuk berbagi pada TwitterClick untuk berbagi pada PinterestClick untuk berbagi di Google + Klik untuk mencetak Manfaat terkait SPSS.
Manfaat analisis statistik SPSS dapat dilakukan dengan menggunakan dua metode utama. Salah satunya adalah hanya dengan menggunakan spreadsheet atau manajemen data program umum seperti MS Excel atau melalui menggunakan paket statistik khusus seperti SPSS. Berikut adalah alasan utama mengapa SPSS adalah pilihan terbaik untuk digunakan. Manajemen data yang efektif Meskipun tepat bahwa program spreadsheet menawarkan kontrol yang lebih berkaitan dengan organisasi data, ini juga dapat dilihat sebagai kekurangan. Sebaliknya, Anda tidak dapat memindahkan data blok di SPSS seperti yang dimaksudkan untuk mengatur data secara optimal. Baris A merupakan satu kasus, sedangkan kolom menunjukkan satu variabel. SPSS membuat analisis data lebih cepat karena program tahu lokasi kasus dan variabel. Bila menggunakan spreadsheet, pengguna harus secara manual mendefinisikan hubungan ini dalam setiap analisis. Berbagai pilihan SPSS secara khusus dibuat untuk menganalisis data statistik dan dengan demikian menawarkan berbagai macam metode, grafik dan diagram. Program umum mungkin menawarkan prosedur lain seperti faktur dan akuntansi bentuk, tetapi program khusus yang lebih cocok
untuk fungsi ini. SPSS juga dilengkapi dengan teknik yang lebih dari penyaringan atau membersihkan informasi dalam persiapan untuk analisis lebih lanjut. Selanjutnya, program spreadsheet yang normal hanya dapat mendukung analisis data segera setelah instalasi, dengan tambahan plug-in yang diperlukan untuk mengakses teknik yang lebih rumit. Organisasi output yang lebih baik SPSS dirancang untuk memastikan bahwa output disimpan terpisah dari data itu sendiri. Bahkan, ia menyimpan semua hasil dalam file terpisah yang berbeda dari data. Namun, dalam program-program seperti Excel, hasil analisis ditempatkan dalam satu lembar kerja dan ada kemungkinan Timpa informasi lainnya oleh kecelakaan. Meskipun Excel masih menawarkan cara yang baik untuk organisasi data, menggunakan software khusus seperti SPSS lebih cocok untuk di analisis data mendalam.
Analisis statistik dapat dilakukan dengan menggunakan dua metode utama. Salah satunya adalah hanya dengan menggunakan spreadsheet atau manajemen data program umum seperti MS Excel atau melalui menggunakan paket statistik khusus seperti SPSS. Berikut adalah alasan utama mengapa SPSS adalah pilihan terbaik untuk digunakan. Manajemen data yang efektif Meskipun tepat bahwa program spreadsheet menawarkan kontrol yang lebih berkaitan dengan organisasi data, ini juga dapat dilihat sebagai kekurangan. Sebaliknya, Anda tidak dapat memindahkan data blok di SPSS seperti yang dimaksudkan untuk mengatur data secara optimal. Baris A merupakan satu kasus, sedangkan kolom menunjukkan satu variabel. SPSS membuat analisis data lebih cepat karena program tahu lokasi kasus dan variabel. Bila menggunakan spreadsheet, pengguna harus secara manual mendefinisikan hubungan ini dalam setiap analisis. Berbagai pilihan SPSS secara khusus dibuat untuk menganalisis data statistik dan dengan demikian menawarkan berbagai macam metode, grafik dan diagram. Program umum mungkin menawarkan prosedur lain seperti faktur dan akuntansi bentuk, tetapi program khusus yang lebih cocok untuk fungsi ini. SPSS juga dilengkapi dengan teknik yang lebih dari penyaringan atau membersihkan informasi dalam persiapan untuk analisis lebih lanjut.
Selanjutnya, program spreadsheet yang normal hanya dapat mendukung analisis data segera setelah instalasi, dengan tambahan plug-in yang diperlukan untuk mengakses teknik yang lebih rumit. Organisasi output yang lebih baik SPSS dirancang untuk memastikan bahwa output disimpan terpisah dari data itu sendiri. Bahkan, ia menyimpan semua hasil dalam file terpisah yang berbeda dari data. Namun, dalam program-program seperti Excel, hasil analisis ditempatkan dalam satu lembar kerja dan ada kemungkinan Timpa informasi lainnya oleh kecelakaan. Meskipun Excel masih menawarkan cara yang baik untuk organisasi data, menggunakan software khusus seperti SPSS lebih cocok untuk di analisis data mendalam.
Ada berbagai kalkulator berbasis web yang tersedia secara gratis, dan kualitas kalkulator ini umumnya cukup baik. Ini adalah alternatif yang masuk akal jika Anda melakukan analisis yang sama lagi dan lagi dan Anda jarang menyimpang dari rutinitas itu. Kalkulator berbasis web ini, bagaimanapun, jarang memberikan ringkasan grafis dari data Anda. Juga, jika Anda beralih ke berbagai jenis analisis, Anda harus menemukan berbasis web kalkulator yang berbeda.
Jika perhatian utama Anda adalah dengan entri data yang akurat, terutama untuk proyek penelitian yang kompleks, seperti percobaan multi-pusat, Anda harus menggunakan perangkat lunak database, seperti Microsoft Access atau MySQL. Sayangnya, perangkat lunak database tidak akan memberikan apa-apa kecuali untuk ringkasan statistik yang paling dasar, sehingga Anda harus memasangkan database Anda dengan program yang berbeda untuk analisis data.
R, SAS, dan Stata. Saya hanya daftar tiga program di sini, tapi setidaknya ada selusin program di luar sana yang pesaing serius untuk IBM SPSS. Ini semua adalah program yang sangat baik dengan banyak keuntungan yang sama dari IBM SPSS. Jika Anda sudah akrab dengan salah satu program ini, Anda harus tetap menggunakannya. Satu-satunya kelemahan yang serius dari program ini adalah bahwa mereka sulit untuk belajar untuk pemula.
Alat manajemen data yang komprehensif. Bagian paling penting dari setiap analisis data entri data awal. Jika Anda memasukkan data dengan cara yang salah, Anda tidak akan dapat menganalisis dengan benar. Meskipun Anda dapat menggunakan berbagai pilihan untuk entri data, sering memasukkan data ke dalam IBM SPSS adalah pilihan terbaik. IBM SPSS menawarkan format spreadsheet sederhana untuk entri data yang intuitif dan mudah untuk memulai dengan. Lebih penting lagi, IBM SPSS menyediakan berbagai dokumentasi data (terutama label nilai) yang akan membantu Anda untuk memastikan konsistensi dalam entri data Anda.
Baik grafis opsi tampilan. Sebelum Anda mulai analisis data Anda, Anda perlu memahami bagaimana data Anda berperilaku. Hal ini paling baik dilakukan secara grafis. IBM SPSS menyediakan scatterplots, boxplots, dan histogram yang membantu Anda untuk melihat pola dalam data Anda. Anda tidak harus mempublikasikan temuan hanya berdasarkan interpretasi intuitif grafis, tentu saja. Sebaliknya, grafis ini akan memberikan Anda dengan kerangka umum untuk memahami data Anda, sehingga Anda akan lebih mampu menginterpretasikan prosedur disimpulkan kompleks yang mengikuti.
Sebuah berbagai model statistik. Seringkali Anda tidak akan tahu pada awal proyek penelitian apa model statistik akan paling cocok untuk proyek tertentu. Kadang-kadang Anda akan memiliki gambaran umum, tetapi sering model statistik akan berubah setelah Anda mulai memeriksa data Anda. Atau Anda akan ingin menjalankan analisis alternatif sebagai cek kualitas untuk analisis awalnya direncanakan.
IBM SPSS menawarkan berbagai model statistik yang sangat fleksibel: terutama model linier umum dan berbagai model regresi logistik. Ini memungkinkan Anda untuk memiliki satu program yang akan memenuhi hampir semua kebutuhan Anda analisis data. Meskipun beberapa orang mungkin perlu untuk melengkapi IBM SPSS dengan program lain seperti R, untuk sebagian besar orang yang saya bekerja dengan, IBM SPSS akan menjadi satu-satunya paket perangkat lunak statitical yang mereka butuhkan.
Yang mudah untuk belajar menu didorong antarmuka. Banyak program perangkat lunak bersaing statistik, seperti R, SAS, dan Stata, dijalankan terutama sebagai bahasa pemrograman. Sementara bahasa pemrograman menawarkan beberapa keuntungan penting, itu memakan waktu lebih lama untuk belajar. Selanjutnya, kompleksitas sering enggan Anda dari mencoba pendekatan baru dan berbeda.
Sementara Excel adalah alat bisnis yang sangat berguna, ia memiliki keterbatasan â € "dan sekarang dapat menangani dataset besar, Anda juga perlu bantuan untuk mengelola data ini. IBM SPSS Keuntungan untuk Microsoft Excel memberikan alat-alat canggih untuk lebih efisien dan efektif mengelola dan menganalisis dataset bisnis.
Ini berarti Anda dapat menemukan informasi dalam data Anda bahkan jika Anda dona € ™ t memiliki pengetahuan rinci tentang statistik. IBM SPSS Keuntungan untuk Microsoft Excel termasuk 10 prosedur khusus dipilih untuk memungkinkan pengguna bisnis untuk menggunakan penyiapan data dan analisis canggih alat dalam Excel. Secara khusus, ia memiliki prosedur untuk melakukan kebaruan, frekuensi dan nilai moneter (RFM) analisis. Wizards memandu Anda melalui langkah-langkah untuk membantu Anda mengelola dan mengeksplorasi data, menemukan nilai dalam dataset besar dan melakukan analisis.
IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk membuat pohon klasifikasi yang sangat visual yang membantu Anda mengidentifikasi segmen pasar. Misalnya, menggunakan pohon klasifikasi untuk mengidentifikasi karakteristik pelanggan cenderung membeli jenis produk tertentu. Karena Anda menampilkan hasil visual, Anda dapat lebih jelas melihat hubungan dalam data Anda. Analisis pohon klasifikasi canggih, namun mudah digunakan ini memungkinkan Anda untuk menjelajahi hasil dan menemukan subkelompok tertentu dan hubungan dalam data Anda bahwa Anda mungkin tidak menemukan dengan menggunakan statistik dalam Excel.
Sekarang dataset Excel dapat lebih besar dari sebelumnya, ita € ™ s tidak mungkin lagi untuk â € œeyeballâ € ?? data Anda untuk memastikan tidak ada yang salah. Selain itu, lebih banyak data berarti risiko yang lebih tinggi dari data yang buruk.
IBM SPSS Keuntungan untuk Microsoft Excel menyediakan Anda dengan prosedur yang memungkinkan Anda untuk mempersiapkan dan mengubah data. Gunakan prosedur ini untuk mengatur ulang data dan menempatkan mereka dalam format untuk membantu analisis. Selain itu, Anda mendapatkan lebih banyak pilihan untuk mengeksplorasi data, yang membuatnya lebih mudah untuk menemukan nilai dalam dataset yang lebih besar.
Selama beberapa dekade, para analis telah mengandalkan IBM SPSS Statistik untuk membantu mereka memandu melalui analisis data pengambilan keputusan. IBM SPSS Keuntungan untuk Excel 2007 menyediakan karena teknik IBM SPSS Statistics, ditambah kemampuan untuk mengakses, mengelola dan menganalisis sejumlah besar data. Ini berarti Anda dapat menemukan informasi dalam data Anda bahkan jika Anda dona € ™ t memiliki pengetahuan rinci tentang statistik. IBM SPSS Keuntungan untuk Microsoft Excel termasuk 10 prosedur khusus dipilih untuk memungkinkan pengguna bisnis untuk menggunakan penyiapan data dan analisis canggih alat dalam Excel. Secara khusus, ia memiliki prosedur untuk melakukan kebaruan, frekuensi dan nilai moneter (RFM) analisis. Wizards memandu Anda melalui langkah-langkah untuk membantu Anda mengelola dan mengeksplorasi data, menemukan nilai dalam dataset besar dan melakukan analisis. Persiapan IBM SPSS
Keuntungan untuk Microsoft Excel mulus terintegrasi ke antarmuka Excel. Cukup klik pada â € œIBM SPSS Advantageâ € ?? dari menu Excel, dan pilih prosedur dari pita untuk memulai. Setiap fungsi IBM SPSS Statistics dioperasikan melalui wizard atau dialog tab, sehingga mudah bagi Anda untuk mendapatkan hasil. Anda dona € ™ t perlu scripting atau pemrograman keterampilan sering dibutuhkan untuk memanfaatkan produk statistik yang kompleks. Melakukan analisis RFM muat, frekuensi dan nilai moneter (RFM) analisis adalah teknik yang sering digunakan dalam pemasaran langsung untuk mengidentifikasi pelanggan yang paling menguntungkan Anda. Pengalaman menunjukkan bahwa kebaruan (waktu terbaru Anda memiliki interaksi dengan pelanggan), frekuensi (jumlah interaksi Anda memiliki Anda telah dengan pelanggan), dan nilai moneter (jumlah uang yang telah Anda terima dari pelanggan) adalah prediktor terbaik dari kecenderungan untuk membeli dari Anda di masa depan. Dengan IBM SPSS Keuntungan untuk Microsoft Excel, Anda dapat dengan mudah melakukan analisis RFM untuk mengidentifikasi pelanggan ini. Wizards membantu Anda membuat skor RFM untuk pelanggan atau transaksi data dengan melangkah Anda melalui analisis RFM. IBM SPSS Keuntungan untuk Excel 2007 juga menghasilkan grafik untuk tes diagnostik, yang membantu Anda memahami distribusi data Anda. Setelah Anda memiliki hasil, youâ € ™ akan siap untuk pasar untuk pelanggan lama yang paling mungkin untuk menanggapi tawaran baru. Mudah mengidentifikasi kelompok IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk membuat pohon klasifikasi yang sangat visual yang membantu Anda mengidentifikasi segmen pasar. Misalnya, menggunakan pohon klasifikasi untuk mengidentifikasi karakteristik pelanggan cenderung membeli jenis produk tertentu. Karena Anda menampilkan hasil visual, Anda dapat lebih jelas melihat hubungan dalam data Anda. Analisis pohon klasifikasi canggih, namun mudah digunakan ini memungkinkan Anda untuk menjelajahi hasil dan menemukan subkelompok tertentu dan hubungan dalam data Anda bahwa Anda mungkin tidak menemukan dengan menggunakan statistik dalam Excel. Cari data yang tidak biasa Sekarang dataset Excel dapat lebih besar dari sebelumnya, ita € ™ s tidak mungkin lagi untuk â € œeyeballâ € ?? data Anda untuk memastikan tidak ada yang salah. Selain itu, lebih banyak data berarti risiko yang lebih tinggi dari data yang buruk. Sebuah prosedur tertentu dalam IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk menangkap data yang masalah sehingga Anda dapat menghapus atau memperbaiki mereka sebelum analisis. Gunakan prosedur ini untuk mendeteksi nilai yang tidak valid yang disebabkan oleh kesalahan entri data dan untuk mendeteksi kasus yang benar-benar tidak
biasa yang cocok untuk analisis. IBM SPSS Keuntungan untuk Microsoft Excel akan menyoroti sel data dan memberikan penjelasan singkat mengapa itu menemukan anomali. Menyiapkan dan mengubah data IBM SPSS Keuntungan untuk Microsoft Excel menyediakan Anda dengan prosedur yang memungkinkan Anda untuk mempersiapkan dan mengubah data. Gunakan prosedur ini untuk mengatur ulang data dan menempatkan mereka dalam format untuk membantu analisis. Selain itu, Anda mendapatkan lebih banyak pilihan untuk mengeksplorasi data, yang membuatnya lebih mudah untuk menemukan nilai dalam dataset yang lebih besar. Bergabunglah tabel â € "Dengan IBM SPSS Keuntungan untuk Microsoft Excel, Anda dapat menggabungkan dua tabel Excel berdasarkan kriteria yang sesuai baris dalam satu meja dengan baris dalam tabel lainnya. Merestrukturisasi Data â € "Anda dapat merestrukturisasi tabel untuk menggabungkan informasi dari beberapa baris. Misalnya, menggunakan prosedur ini untuk merestrukturisasi data transaksional. Anda dapat membuat satu baris untuk setiap pelanggan, dengan setiap transaksi dicatat dalam kolom terpisah â € "memberikan cara baru untuk melihat data. Baris Agregat â € "Menggabungkan kelompok baris dalam tabel yang dipilih ke dalam baris tunggal untuk dengan mudah membuat yang baru, tabel yang berisi data agregat ringkasan untuk masing-masing kelompok. Misalnya, jika Anda memiliki sebuah meja yang mencatat setiap pembelian yang dilakukan oleh pelanggan pada baris terpisah dan mengidentifikasi setiap pelanggan dengan nilai ID yang unik, Anda dapat mengelompokkan catatan berdasarkan nilai ID. IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk membuat tabel dikumpulkan dengan satu baris untuk setiap pelanggan, menggunakan nilai ringkasan yang dipilih untuk kolom lain dari tabel asli. Data kelompok dalam rentang â € "Kadang-kadang Anda ingin â € œbinâ € ?? data sehingga Anda dapat melihat rentang nya. Misalnya, Anda mungkin ingin kelompok usia dengan rentang (kurang dari 20, 20-29, 30-39, 40-49, dan sebagainya) untuk meneliti kebiasaan membeli dari kelompok usia yang berbeda. Nilai bin prosedur IBM SPSS Keuntungan untuk Microsoft Excel menyediakan antarmuka yang mudah digunakan untuk membangun rentang data. IBM SPSS Keuntungan untuk Microsoft Excel menyajikan anda dengan cutpoints otomatis mengatur bahwa Anda dapat menyesuaikan sesuai terbaik distribusi data Anda. Ketika Anda menyimpan nilai-nilai binned, IBM SPSS Keuntungan untuk Microsoft Excel menciptakan kolom baru yang berisi data dikelompokkan ke dalam rentang. Anda juga dapat membuat kolom yang berisi nilai-nilai teks baru yang menggambarkan setiap rentang, serta kolom yang berisi nilai integer sekuensial ditugaskan untuk setiap kategori rentang dalam urutan. Optimalkan sampah
untuk model â € "Dengan IBM SPSS Keuntungan untuk Microsoft Excel, Anda dapat mengubah skala-tipe data dengan mendistribusikan nilai-
nilai ke tempat sampah. Anda kemudian dapat menggunakan data binned bukan nilai data asli untuk analisis lebih lanjut. Misalnya, Anda mungkin ingin mengoptimalkan data ke tempat sampah untuk menjaga privasi sumber data. Alih-alih melaporkan nilai yang sebenarnya, Anda dapat menggunakan nomor binned. Selain itu, beberapa analisis lebih efisien ketika bekerja dengan berkurangnya jumlah variabel.
Dioptimalkan Binning menciptakan kelompok untuk kolom pilihan (seperti usia) dalam kaitannya dengan variabel lain. Tabel Simpan Excel untuk IBM SPSS Statistik asli file data Untuk manajemen data tambahan dan kemampuan analisis, Anda mungkin ingin mempertimbangkan update ke versi lengkap dari IBM SPSS Statistics. Apakah Anda memilih untuk melakukan hal ini dalam waktu jangka panjang dekat atau, Anda akan dapat menggunakan tabel Excel Anda di IBM SPSS Statistics. IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk menyimpan tabel Excel di file data IBM SPSS Statistics-diformat. Grafik distribusi ini menunjukkan nilai moneter rata-rata untuk kategori didefinisikan berdasar dan frekuensi skor. Daerah gelap menunjukkan nilai moneter rata yang lebih tinggi. Dalam contoh ini, pelanggan yang paling baru dan sering juga memiliki nilai moneter rata yang lebih tinggi. Tentukan Properti Variabel klasifikasi pohon ini memprediksi harga rata-rata orang akan membayar untuk mobil. Setiap node dari pohon menampilkan mean (rata-rata) harga yang harus dibayar, standar deviasi, dan jumlah kasus (baris) dalam node. Contoh ini menunjukkan bahwa pendapatan adalah faktor yang paling penting yang mempengaruhi harga pembelian rata-rata. Tentukan Properti Variabel Lihat distribusi data dan menyesuaikan cutpoints di Bin Nilai dialog. Tentukan Properti Variabel Selengkapnya tentang Statistik Family.
Selama beberapa dekade, para analis telah mengandalkan IBM SPSS Statistik untuk membantu mereka memandu melalui analisis data pengambilan keputusan. IBM SPSS Keuntungan untuk Excel 2007 menyediakan karena teknik IBM SPSS Statistics, ditambah kemampuan untuk mengakses, mengelola dan menganalisis sejumlah besar data. Ini berarti Anda dapat menemukan informasi dalam data Anda bahkan jika Anda dona € ™ t memiliki pengetahuan rinci tentang statistik. IBM SPSS Keuntungan untuk Microsoft Excel termasuk 10 prosedur khusus dipilih untuk memungkinkan pengguna bisnis untuk menggunakan penyiapan data dan analisis canggih alat dalam Excel. Secara khusus, ia memiliki prosedur untuk melakukan kebaruan, frekuensi dan nilai moneter (RFM) analisis. Wizards memandu Anda melalui langkah-langkah untuk membantu Anda mengelola dan mengeksplorasi data, menemukan nilai dalam dataset besar dan melakukan analisis. Persiapan IBM SPSS
Keuntungan untuk Microsoft Excel mulus terintegrasi ke antarmuka Excel. Cukup klik pada â € œIBM SPSS Advantageâ € ?? dari menu Excel,dan pilih prosedur dari pita untuk memulai. Setiap fungsi IBM SPSS Statistics dioperasikan melalui wizard atau dialog tab, sehingga mudah bagi Anda untuk mendapatkan hasil. Anda dona € ™ t perlu scripting atau pemrograman keterampilan sering dibutuhkan untuk memanfaatkan produk statistik yang kompleks. Melakukan analisis RFM muat, frekuensi dan nilai moneter (RFM) analisis adalah teknik yang sering digunakan dalam pemasaran langsung untuk mengidentifikasi pelanggan yang paling menguntungkan Anda. Pengalaman menunjukkan bahwa kebaruan (waktu terbaru Anda memiliki interaksi dengan pelanggan), frekuensi (jumlah interaksi Anda memiliki Anda telah dengan pelanggan), dan nilai moneter (jumlah uang yang telah Anda terima dari pelanggan) adalah prediktor terbaik dari kecenderungan untuk membeli dari Anda di masa depan. Dengan IBM SPSS Keuntungan untuk Microsoft Excel, Anda dapat dengan mudah melakukan analisis RFM untuk mengidentifikasi pelanggan ini. Wizards membantu Anda membuat skor RFM untuk pelanggan atau transaksi data dengan melangkah Anda melalui analisis RFM. IBM SPSS Keuntungan untuk Excel 2007 juga menghasilkan grafik untuk tes diagnostik, yang membantu Anda memahami distribusi data Anda. Setelah Anda memiliki hasil, youâ € ™ akan siap untuk pasar untuk pelanggan lama yang paling mungkin untuk menanggapi tawaran baru. Mudah mengidentifikasi kelompok IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk membuat pohon klasifikasi yang sangat visual yang membantu Anda mengidentifikasi segmen pasar. Misalnya, menggunakan pohon klasifikasi untuk mengidentifikasi karakteristik pelanggan cenderung membeli jenis produk tertentu. Karena Anda menampilkan hasil visual, Anda dapat lebih jelas melihat hubungan dalam data Anda. Analisis pohon klasifikasi canggih, namun mudah digunakan ini memungkinkan Anda untuk menjelajahi hasil dan menemukan subkelompok tertentu dan hubungan dalam data Anda bahwa Anda mungkin tidak menemukan dengan menggunakan statistik dalam Excel. Cari data yang tidak biasa Sekarang dataset Excel dapat lebih besar dari sebelumnya, ita € ™ s tidak mungkin lagi untuk â € œeyeballâ € ?? data Anda untuk memastikan tidak ada yang salah. Selain itu, lebih banyak data berarti risiko yang lebih tinggi dari data yang buruk. Sebuah prosedur tertentu dalam IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk menangkap data yang masalah sehingga Anda dapat menghapus atau memperbaiki mereka sebelum analisis. Gunakan prosedur ini untuk mendeteksi nilai yang tidak valid yang disebabkan oleh kesalahan entri data dan untuk mendeteksi kasus yang benar-benar tidak
biasa yang cocok untuk analisis. IBM SPSS Keuntungan untuk Microsoft Excel akan menyoroti sel data dan memberikan penjelasan singkat mengapa itu menemukan anomali. Menyiapkan dan mengubah data IBM SPSS Keuntungan untuk Microsoft Excel menyediakan Anda dengan prosedur yang memungkinkan Anda untuk mempersiapkan dan mengubah data. Gunakan prosedur ini untuk mengatur ulang data dan menempatkan mereka dalam format untuk membantu analisis. Selain itu, Anda mendapatkan lebih banyak pilihan untuk mengeksplorasi data, yang membuatnya lebih mudah untuk menemukan nilai dalam dataset yang lebih besar. Bergabunglah tabel â € "Dengan IBM SPSS Keuntungan untuk Microsoft
Excel, Anda dapat menggabungkan dua tabel Excel berdasarkan kriteria yang sesuai baris dalam satu meja dengan baris dalam tabel lainnya. Merestrukturisasi Data â € "Anda dapat merestrukturisasi tabel untuk menggabungkan informasi dari beberapa baris. Misalnya, menggunakan prosedur ini untuk merestrukturisasi data transaksional. Anda dapat membuat satu baris untuk setiap pelanggan, dengan setiap transaksi dicatat dalam kolom terpisah â € "memberikan cara baru untuk melihat data. Baris Agregat â € "Menggabungkan kelompok baris dalam tabel yang dipilih ke dalam baris tunggal untuk dengan mudah membuat yang baru, tabel yang berisi data agregat ringkasan untuk masing-masing kelompok. Misalnya, jika Anda memiliki sebuah meja yang mencatat setiap pembelian yang dilakukan oleh pelanggan pada baris terpisah dan mengidentifikasi setiap pelanggan dengan nilai ID yang unik, Anda dapat mengelompokkan catatan berdasarkan nilai ID. IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk membuat tabel dikumpulkan dengan satu baris untuk setiap pelanggan, menggunakan nilai ringkasan yang dipilih untuk kolom lain dari tabel asli. Data kelompok dalam rentang â € "Kadang-kadang Anda ingin â € œbinâ € ?? data sehingga Anda dapat melihat rentang nya. Misalnya, Anda mungkin ingin kelompok usia dengan rentang
(kurang dari 20, 20-29, 30-39, 40-49, dan sebagainya) untuk meneliti kebiasaan membeli dari kelompok usia yang berbeda. Nilai bin prosedur IBM SPSS Keuntungan untuk Microsoft Excel menyediakan antarmuka yang mudah digunakan untuk membangun rentang data. IBM SPSS Keuntungan untuk Microsoft Excel menyajikan anda dengan cutpoints otomatis mengatur bahwa Anda dapat menyesuaikan sesuai terbaik distribusi data Anda. Ketika Anda menyimpan nilai-nilai binned, IBM SPSS Keuntungan untuk Microsoft Excel menciptakan kolom baru yang berisi data dikelompokkan ke dalam rentang. Anda juga dapat membuat kolom yang berisi nilai-nilai teks baru yang menggambarkan setiap rentang, serta kolom yang berisi nilai integer sekuensial ditugaskan untuk setiap kategori rentang dalam urutan. Optimalkan sampah untuk model â € "Dengan IBM SPSS Keuntungan untuk Microsoft Excel, Anda dapat mengubah skala-tipe data dengan mendistribusikan nilai-nilai ke tempat sampah. Anda kemudian dapat menggunakan data binned bukan nilai data asli untuk analisis lebih lanjut. Misalnya, Anda mungkin ingin mengoptimalkan data ke tempat sampah untuk menjaga privasi sumber data. Alih-alih melaporkan nilai yang sebenarnya, Anda dapat menggunakan nomor binned. Selain itu, beberapa analisis lebih efisien ketika bekerja dengan berkurangnya jumlah variabel.
Dioptimalkan Binning menciptakan kelompok untuk kolom pilihan (seperti usia) dalam kaitannya dengan variabel lain. Tabel Simpan Excel untuk IBM SPSS Statistik asli file data Untuk manajemen data tambahan dan kemampuan analisis, Anda mungkin ingin mempertimbangkan update ke versi lengkap dari IBM SPSS Statistics. Apakah Anda memilih untuk melakukan hal ini dalam waktu jangka panjang dekat atau, Anda akan dapat menggunakan tabel Excel Anda di IBM SPSS Statistics. IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk menyimpan tabel Excel di file data IBM SPSS Statistics-diformat.
Grafik distribusi ini menunjukkan nilai moneter rata-rata untuk kategori didefinisikan berdasar dan frekuensi skor. Daerah gelap menunjukkan nilai moneter rata yang lebih tinggi. Dalam contoh ini, pelanggan yang paling baru dan sering juga memiliki nilai moneter rata yang lebih tinggi. Tentukan Properti Variabel klasifikasi pohon ini memprediksi harga rata-rata orang akan membayar untuk mobil.
Setiap node dari pohon menampilkan mean (rata-rata) harga yang harus dibayar, standar deviasi, dan jumlah kasus (baris) dalam node. Contoh ini menunjukkan bahwa pendapatan adalah faktor yang paling penting yang mempengaruhi harga pembelian rata-rata. Tentukan Properti Variabel Lihat distribusi data dan menyesuaikan cutpoints di Bin Nilai dialog.
Klasifikasi pohon ini memprediksi harga rata-rata orang akan membayar untuk mobil. Setiap node dari pohon menampilkan mean (rata-rata) harga yang harus dibayar, standar deviasi, dan jumlah kasus (baris) dalam node. Contoh ini menunjukkan bahwa pendapatan adalah faktor yang paling penting yang mempengaruhi harga pembelian rata-rata.
Klasifikasi pohon ini memprediksi harga rata-rata orang akan membayar untuk mobil. Setiap node dari pohon menampilkan mean (rata-rata) harga yang harus dibayar, standar deviasi, dan jumlah kasus (baris) dalam node. Contoh ini menunjukkan bahwa pendapatan adalah faktor
yang paling penting yang mempengaruhi harga pembelian rata-rata.
Sebuah file sistem SPSS dibuat pada perintah dengan program SPSS itu sendiri, yang menghasilkan sebuah file biner yang dirancang untuk jenis tertentu dari komputer menggunakan sistem operasi yang ditunjuk. File ini dapat dibaca oleh program SPSS operasi pada komputer dan sistem operasi yang kompatibel. Sebuah sistem file tidak dapat dibaca oleh manusia normal - hanya dengan komputer dan sistem operasi yang diciptakan. Artinya, sistem file yang dibuat untuk komputer unix tidak dapat dibaca di kedua Windows atau komputer Macintosh.Namun, ada cara untuk mengekspor file sistem untuk impor berbagai jenis komputer. Perintah SPSS mengizinkan penggantian nama, menjatuhkan, dan penataan kembali variabel dalam file yang baru dibuat. Tugas ini juga dilakukan melalui perintah antarmuka.
SPSS secara khusus dibuat untuk menganalisis data statistik dan dengan demikian menawarkan berbagai macam metode, grafik dan diagram. Program umum mungkin menawarkan prosedur lain seperti faktur dan akuntansi bentuk, tetapi program khusus yang lebih cocok untuk fungsi ini. SPSS juga dilengkapi dengan teknik yang lebih dari penyaringan atau membersihkan informasi dalam persiapan untuk analisis lebih lanjut. Selanjutnya, program spreadsheet yang normal hanya dapat mendukung analisis data segera setelah instalasi, dengan tambahan plug-in yang diperlukan untuk mengakses teknik yang lebih rumit.
SPSS dirancang untuk memastikan bahwa output disimpan terpisah dari data itu sendiri. Bahkan, ia menyimpan semua hasil dalam file terpisah yang berbeda dari data. Namun, dalam program-program seperti Excel, hasil analisis ditempatkan dalam satu lembar kerja dan ada kemungkinan Timpa informasi lainnya oleh kecelakaan.
Manfaat analisis statistik SPSS dapat dilakukan dengan menggunakan dua metode utama. Salah satunya adalah hanya dengan menggunakan spreadsheet atau manajemen data program umum seperti MS Excel atau melalui menggunakan paket statistik khusus seperti SPSS. Berikut adalah alasan utama mengapa SPSS adalah pilihan terbaik untuk digunakan. Manajemen data yang efektif Meskipun tepat bahwa program spreadsheet menawarkan kontrol yang lebih berkaitan dengan organisasi data, ini juga dapat dilihat sebagai kekurangan. Sebaliknya, Anda tidak dapat memindahkan data blok di SPSS seperti yang dimaksudkan untuk mengatur data secara optimal. Baris A merupakan satu kasus, sedangkan kolom menunjukkan satu variabel. SPSS membuat analisis data lebih cepat karena program tahu lokasi kasus dan variabel. Bila menggunakan spreadsheet, pengguna harus secara manual mendefinisikan hubungan ini dalam setiap analisis. Berbagai pilihan SPSS secara khusus dibuat untuk menganalisis data statistik dan dengan demikian menawarkan berbagai macam metode, grafik dan diagram. Program umum mungkin menawarkan prosedur lain seperti faktur dan akuntansi bentuk, tetapi program khusus yang lebih cocok
untuk fungsi ini. SPSS juga dilengkapi dengan teknik yang lebih dari penyaringan atau membersihkan informasi dalam persiapan untuk analisis lebih lanjut. Selanjutnya, program spreadsheet yang normal hanya dapat mendukung analisis data segera setelah instalasi, dengan tambahan plug-in yang diperlukan untuk mengakses teknik yang lebih rumit. Organisasi output yang lebih baik SPSS dirancang untuk memastikan bahwa output disimpan terpisah dari data itu sendiri. Bahkan, ia menyimpan semua hasil dalam file terpisah yang berbeda dari data. Namun, dalam program-program seperti Excel, hasil analisis ditempatkan dalam satu lembar kerja dan ada kemungkinan Timpa informasi lainnya oleh kecelakaan. Meskipun Excel masih menawarkan cara yang baik untuk organisasi data, menggunakan software khusus seperti SPSS lebih cocok untuk di analisis data mendalam. Berbagi: Berbagi di FacebookClick ke email ini untuk friendClick untuk berbagi pada TwitterClick untuk berbagi pada PinterestClick untuk berbagi di Google + Klik untuk mencetak Manfaat terkait SPSS.
Manfaat analisis statistik SPSS dapat dilakukan dengan menggunakan dua metode utama. Salah satunya adalah hanya dengan menggunakan spreadsheet atau manajemen data program umum seperti MS Excel atau melalui menggunakan paket statistik khusus seperti SPSS. Berikut adalah alasan utama mengapa SPSS adalah pilihan terbaik untuk digunakan. Manajemen data yang efektif Meskipun tepat bahwa program spreadsheet menawarkan kontrol yang lebih berkaitan dengan organisasi data, ini juga dapat dilihat sebagai kekurangan. Sebaliknya, Anda tidak dapat memindahkan data blok di SPSS seperti yang dimaksudkan untuk mengatur data secara optimal. Baris A merupakan satu kasus, sedangkan kolom menunjukkan satu variabel. SPSS membuat analisis data lebih cepat karena program tahu lokasi kasus dan variabel. Bila menggunakan spreadsheet, pengguna harus secara manual mendefinisikan hubungan ini dalam setiap analisis. Berbagai pilihan SPSS secara khusus dibuat untuk menganalisis data statistik dan dengan demikian menawarkan berbagai macam metode, grafik dan diagram. Program umum mungkin menawarkan prosedur lain seperti faktur dan akuntansi bentuk, tetapi program khusus yang lebih cocok
untuk fungsi ini. SPSS juga dilengkapi dengan teknik yang lebih dari penyaringan atau membersihkan informasi dalam persiapan untuk analisis lebih lanjut. Selanjutnya, program spreadsheet yang normal hanya dapat mendukung analisis data segera setelah instalasi, dengan tambahan plug-in yang diperlukan untuk mengakses teknik yang lebih rumit. Organisasi output yang lebih baik SPSS dirancang untuk memastikan bahwa output disimpan terpisah dari data itu sendiri. Bahkan, ia menyimpan semua hasil dalam file terpisah yang berbeda dari data. Namun, dalam program-program seperti Excel, hasil analisis ditempatkan dalam satu lembar kerja dan ada kemungkinan Timpa informasi lainnya oleh kecelakaan. Meskipun Excel masih menawarkan cara yang baik untuk organisasi data, menggunakan software khusus seperti SPSS lebih cocok untuk di analisis data mendalam.
Analisis statistik dapat dilakukan dengan menggunakan dua metode utama. Salah satunya adalah hanya dengan menggunakan spreadsheet atau manajemen data program umum seperti MS Excel atau melalui menggunakan paket statistik khusus seperti SPSS. Berikut adalah alasan utama mengapa SPSS adalah pilihan terbaik untuk digunakan. Manajemen data yang efektif Meskipun tepat bahwa program spreadsheet menawarkan kontrol yang lebih berkaitan dengan organisasi data, ini juga dapat dilihat sebagai kekurangan. Sebaliknya, Anda tidak dapat memindahkan data blok di SPSS seperti yang dimaksudkan untuk mengatur data secara optimal. Baris A merupakan satu kasus, sedangkan kolom menunjukkan satu variabel. SPSS membuat analisis data lebih cepat karena program tahu lokasi kasus dan variabel. Bila menggunakan spreadsheet, pengguna harus secara manual mendefinisikan hubungan ini dalam setiap analisis. Berbagai pilihan SPSS secara khusus dibuat untuk menganalisis data statistik dan dengan demikian menawarkan berbagai macam metode, grafik dan diagram. Program umum mungkin menawarkan prosedur lain seperti faktur dan akuntansi bentuk, tetapi program khusus yang lebih cocok untuk fungsi ini. SPSS juga dilengkapi dengan teknik yang lebih dari penyaringan atau membersihkan informasi dalam persiapan untuk analisis lebih lanjut.
Selanjutnya, program spreadsheet yang normal hanya dapat mendukung analisis data segera setelah instalasi, dengan tambahan plug-in yang diperlukan untuk mengakses teknik yang lebih rumit. Organisasi output yang lebih baik SPSS dirancang untuk memastikan bahwa output disimpan terpisah dari data itu sendiri. Bahkan, ia menyimpan semua hasil dalam file terpisah yang berbeda dari data. Namun, dalam program-program seperti Excel, hasil analisis ditempatkan dalam satu lembar kerja dan ada kemungkinan Timpa informasi lainnya oleh kecelakaan. Meskipun Excel masih menawarkan cara yang baik untuk organisasi data, menggunakan software khusus seperti SPSS lebih cocok untuk di analisis data mendalam.
Ada berbagai kalkulator berbasis web yang tersedia secara gratis, dan kualitas kalkulator ini umumnya cukup baik. Ini adalah alternatif yang masuk akal jika Anda melakukan analisis yang sama lagi dan lagi dan Anda jarang menyimpang dari rutinitas itu. Kalkulator berbasis web ini, bagaimanapun, jarang memberikan ringkasan grafis dari data Anda. Juga, jika Anda beralih ke berbagai jenis analisis, Anda harus menemukan berbasis web kalkulator yang berbeda.
Jika perhatian utama Anda adalah dengan entri data yang akurat, terutama untuk proyek penelitian yang kompleks, seperti percobaan multi-pusat, Anda harus menggunakan perangkat lunak database, seperti Microsoft Access atau MySQL. Sayangnya, perangkat lunak database tidak akan memberikan apa-apa kecuali untuk ringkasan statistik yang paling dasar, sehingga Anda harus memasangkan database Anda dengan program yang berbeda untuk analisis data.
R, SAS, dan Stata. Saya hanya daftar tiga program di sini, tapi setidaknya ada selusin program di luar sana yang pesaing serius untuk IBM SPSS. Ini semua adalah program yang sangat baik dengan banyak keuntungan yang sama dari IBM SPSS. Jika Anda sudah akrab dengan salah satu program ini, Anda harus tetap menggunakannya. Satu-satunya kelemahan yang serius dari program ini adalah bahwa mereka sulit untuk belajar untuk pemula.
Alat manajemen data yang komprehensif. Bagian paling penting dari setiap analisis data entri data awal. Jika Anda memasukkan data dengan cara yang salah, Anda tidak akan dapat menganalisis dengan benar. Meskipun Anda dapat menggunakan berbagai pilihan untuk entri data, sering memasukkan data ke dalam IBM SPSS adalah pilihan terbaik. IBM SPSS menawarkan format spreadsheet sederhana untuk entri data yang intuitif dan mudah untuk memulai dengan. Lebih penting lagi, IBM SPSS menyediakan berbagai dokumentasi data (terutama label nilai) yang akan membantu Anda untuk memastikan konsistensi dalam entri data Anda.
Baik grafis opsi tampilan. Sebelum Anda mulai analisis data Anda, Anda perlu memahami bagaimana data Anda berperilaku. Hal ini paling baik dilakukan secara grafis. IBM SPSS menyediakan scatterplots, boxplots, dan histogram yang membantu Anda untuk melihat pola dalam data Anda. Anda tidak harus mempublikasikan temuan hanya berdasarkan interpretasi intuitif grafis, tentu saja. Sebaliknya, grafis ini akan memberikan Anda dengan kerangka umum untuk memahami data Anda, sehingga Anda akan lebih mampu menginterpretasikan prosedur disimpulkan kompleks yang mengikuti.
Sebuah berbagai model statistik. Seringkali Anda tidak akan tahu pada awal proyek penelitian apa model statistik akan paling cocok untuk proyek tertentu. Kadang-kadang Anda akan memiliki gambaran umum, tetapi sering model statistik akan berubah setelah Anda mulai memeriksa data Anda. Atau Anda akan ingin menjalankan analisis alternatif sebagai cek kualitas untuk analisis awalnya direncanakan.
IBM SPSS menawarkan berbagai model statistik yang sangat fleksibel: terutama model linier umum dan berbagai model regresi logistik. Ini memungkinkan Anda untuk memiliki satu program yang akan memenuhi hampir semua kebutuhan Anda analisis data. Meskipun beberapa orang mungkin perlu untuk melengkapi IBM SPSS dengan program lain seperti R, untuk sebagian besar orang yang saya bekerja dengan, IBM SPSS akan menjadi satu-satunya paket perangkat lunak statitical yang mereka butuhkan.
Yang mudah untuk belajar menu didorong antarmuka. Banyak program perangkat lunak bersaing statistik, seperti R, SAS, dan Stata, dijalankan terutama sebagai bahasa pemrograman. Sementara bahasa pemrograman menawarkan beberapa keuntungan penting, itu memakan waktu lebih lama untuk belajar. Selanjutnya, kompleksitas sering enggan Anda dari mencoba pendekatan baru dan berbeda.
Sementara Excel adalah alat bisnis yang sangat berguna, ia memiliki keterbatasan â € "dan sekarang dapat menangani dataset besar, Anda juga perlu bantuan untuk mengelola data ini. IBM SPSS Keuntungan untuk Microsoft Excel memberikan alat-alat canggih untuk lebih efisien dan efektif mengelola dan menganalisis dataset bisnis.
Ini berarti Anda dapat menemukan informasi dalam data Anda bahkan jika Anda dona € ™ t memiliki pengetahuan rinci tentang statistik. IBM SPSS Keuntungan untuk Microsoft Excel termasuk 10 prosedur khusus dipilih untuk memungkinkan pengguna bisnis untuk menggunakan penyiapan data dan analisis canggih alat dalam Excel. Secara khusus, ia memiliki prosedur untuk melakukan kebaruan, frekuensi dan nilai moneter (RFM) analisis. Wizards memandu Anda melalui langkah-langkah untuk membantu Anda mengelola dan mengeksplorasi data, menemukan nilai dalam dataset besar dan melakukan analisis.
IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk membuat pohon klasifikasi yang sangat visual yang membantu Anda mengidentifikasi segmen pasar. Misalnya, menggunakan pohon klasifikasi untuk mengidentifikasi karakteristik pelanggan cenderung membeli jenis produk tertentu. Karena Anda menampilkan hasil visual, Anda dapat lebih jelas melihat hubungan dalam data Anda. Analisis pohon klasifikasi canggih, namun mudah digunakan ini memungkinkan Anda untuk menjelajahi hasil dan menemukan subkelompok tertentu dan hubungan dalam data Anda bahwa Anda mungkin tidak menemukan dengan menggunakan statistik dalam Excel.
Sekarang dataset Excel dapat lebih besar dari sebelumnya, ita € ™ s tidak mungkin lagi untuk â € œeyeballâ € ?? data Anda untuk memastikan tidak ada yang salah. Selain itu, lebih banyak data berarti risiko yang lebih tinggi dari data yang buruk.
IBM SPSS Keuntungan untuk Microsoft Excel menyediakan Anda dengan prosedur yang memungkinkan Anda untuk mempersiapkan dan mengubah data. Gunakan prosedur ini untuk mengatur ulang data dan menempatkan mereka dalam format untuk membantu analisis. Selain itu, Anda mendapatkan lebih banyak pilihan untuk mengeksplorasi data, yang membuatnya lebih mudah untuk menemukan nilai dalam dataset yang lebih besar.
Selama beberapa dekade, para analis telah mengandalkan IBM SPSS Statistik untuk membantu mereka memandu melalui analisis data pengambilan keputusan. IBM SPSS Keuntungan untuk Excel 2007 menyediakan karena teknik IBM SPSS Statistics, ditambah kemampuan untuk mengakses, mengelola dan menganalisis sejumlah besar data. Ini berarti Anda dapat menemukan informasi dalam data Anda bahkan jika Anda dona € ™ t memiliki pengetahuan rinci tentang statistik. IBM SPSS Keuntungan untuk Microsoft Excel termasuk 10 prosedur khusus dipilih untuk memungkinkan pengguna bisnis untuk menggunakan penyiapan data dan analisis canggih alat dalam Excel. Secara khusus, ia memiliki prosedur untuk melakukan kebaruan, frekuensi dan nilai moneter (RFM) analisis. Wizards memandu Anda melalui langkah-langkah untuk membantu Anda mengelola dan mengeksplorasi data, menemukan nilai dalam dataset besar dan melakukan analisis. Persiapan IBM SPSS
Keuntungan untuk Microsoft Excel mulus terintegrasi ke antarmuka Excel. Cukup klik pada â € œIBM SPSS Advantageâ € ?? dari menu Excel, dan pilih prosedur dari pita untuk memulai. Setiap fungsi IBM SPSS Statistics dioperasikan melalui wizard atau dialog tab, sehingga mudah bagi Anda untuk mendapatkan hasil. Anda dona € ™ t perlu scripting atau pemrograman keterampilan sering dibutuhkan untuk memanfaatkan produk statistik yang kompleks. Melakukan analisis RFM muat, frekuensi dan nilai moneter (RFM) analisis adalah teknik yang sering digunakan dalam pemasaran langsung untuk mengidentifikasi pelanggan yang paling menguntungkan Anda. Pengalaman menunjukkan bahwa kebaruan (waktu terbaru Anda memiliki interaksi dengan pelanggan), frekuensi (jumlah interaksi Anda memiliki Anda telah dengan pelanggan), dan nilai moneter (jumlah uang yang telah Anda terima dari pelanggan) adalah prediktor terbaik dari kecenderungan untuk membeli dari Anda di masa depan. Dengan IBM SPSS Keuntungan untuk Microsoft Excel, Anda dapat dengan mudah melakukan analisis RFM untuk mengidentifikasi pelanggan ini. Wizards membantu Anda membuat skor RFM untuk pelanggan atau transaksi data dengan melangkah Anda melalui analisis RFM. IBM SPSS Keuntungan untuk Excel 2007 juga menghasilkan grafik untuk tes diagnostik, yang membantu Anda memahami distribusi data Anda. Setelah Anda memiliki hasil, youâ € ™ akan siap untuk pasar untuk pelanggan lama yang paling mungkin untuk menanggapi tawaran baru. Mudah mengidentifikasi kelompok IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk membuat pohon klasifikasi yang sangat visual yang membantu Anda mengidentifikasi segmen pasar. Misalnya, menggunakan pohon klasifikasi untuk mengidentifikasi karakteristik pelanggan cenderung membeli jenis produk tertentu. Karena Anda menampilkan hasil visual, Anda dapat lebih jelas melihat hubungan dalam data Anda. Analisis pohon klasifikasi canggih, namun mudah digunakan ini memungkinkan Anda untuk menjelajahi hasil dan menemukan subkelompok tertentu dan hubungan dalam data Anda bahwa Anda mungkin tidak menemukan dengan menggunakan statistik dalam Excel. Cari data yang tidak biasa Sekarang dataset Excel dapat lebih besar dari sebelumnya, ita € ™ s tidak mungkin lagi untuk â € œeyeballâ € ?? data Anda untuk memastikan tidak ada yang salah. Selain itu, lebih banyak data berarti risiko yang lebih tinggi dari data yang buruk. Sebuah prosedur tertentu dalam IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk menangkap data yang masalah sehingga Anda dapat menghapus atau memperbaiki mereka sebelum analisis. Gunakan prosedur ini untuk mendeteksi nilai yang tidak valid yang disebabkan oleh kesalahan entri data dan untuk mendeteksi kasus yang benar-benar tidak
biasa yang cocok untuk analisis. IBM SPSS Keuntungan untuk Microsoft Excel akan menyoroti sel data dan memberikan penjelasan singkat mengapa itu menemukan anomali. Menyiapkan dan mengubah data IBM SPSS Keuntungan untuk Microsoft Excel menyediakan Anda dengan prosedur yang memungkinkan Anda untuk mempersiapkan dan mengubah data. Gunakan prosedur ini untuk mengatur ulang data dan menempatkan mereka dalam format untuk membantu analisis. Selain itu, Anda mendapatkan lebih banyak pilihan untuk mengeksplorasi data, yang membuatnya lebih mudah untuk menemukan nilai dalam dataset yang lebih besar. Bergabunglah tabel â € "Dengan IBM SPSS Keuntungan untuk Microsoft Excel, Anda dapat menggabungkan dua tabel Excel berdasarkan kriteria yang sesuai baris dalam satu meja dengan baris dalam tabel lainnya. Merestrukturisasi Data â € "Anda dapat merestrukturisasi tabel untuk menggabungkan informasi dari beberapa baris. Misalnya, menggunakan prosedur ini untuk merestrukturisasi data transaksional. Anda dapat membuat satu baris untuk setiap pelanggan, dengan setiap transaksi dicatat dalam kolom terpisah â € "memberikan cara baru untuk melihat data. Baris Agregat â € "Menggabungkan kelompok baris dalam tabel yang dipilih ke dalam baris tunggal untuk dengan mudah membuat yang baru, tabel yang berisi data agregat ringkasan untuk masing-masing kelompok. Misalnya, jika Anda memiliki sebuah meja yang mencatat setiap pembelian yang dilakukan oleh pelanggan pada baris terpisah dan mengidentifikasi setiap pelanggan dengan nilai ID yang unik, Anda dapat mengelompokkan catatan berdasarkan nilai ID. IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk membuat tabel dikumpulkan dengan satu baris untuk setiap pelanggan, menggunakan nilai ringkasan yang dipilih untuk kolom lain dari tabel asli. Data kelompok dalam rentang â € "Kadang-kadang Anda ingin â € œbinâ € ?? data sehingga Anda dapat melihat rentang nya. Misalnya, Anda mungkin ingin kelompok usia dengan rentang (kurang dari 20, 20-29, 30-39, 40-49, dan sebagainya) untuk meneliti kebiasaan membeli dari kelompok usia yang berbeda. Nilai bin prosedur IBM SPSS Keuntungan untuk Microsoft Excel menyediakan antarmuka yang mudah digunakan untuk membangun rentang data. IBM SPSS Keuntungan untuk Microsoft Excel menyajikan anda dengan cutpoints otomatis mengatur bahwa Anda dapat menyesuaikan sesuai terbaik distribusi data Anda. Ketika Anda menyimpan nilai-nilai binned, IBM SPSS Keuntungan untuk Microsoft Excel menciptakan kolom baru yang berisi data dikelompokkan ke dalam rentang. Anda juga dapat membuat kolom yang berisi nilai-nilai teks baru yang menggambarkan setiap rentang, serta kolom yang berisi nilai integer sekuensial ditugaskan untuk setiap kategori rentang dalam urutan. Optimalkan sampah
untuk model â € "Dengan IBM SPSS Keuntungan untuk Microsoft Excel, Anda dapat mengubah skala-tipe data dengan mendistribusikan nilai-
nilai ke tempat sampah. Anda kemudian dapat menggunakan data binned bukan nilai data asli untuk analisis lebih lanjut. Misalnya, Anda mungkin ingin mengoptimalkan data ke tempat sampah untuk menjaga privasi sumber data. Alih-alih melaporkan nilai yang sebenarnya, Anda dapat menggunakan nomor binned. Selain itu, beberapa analisis lebih efisien ketika bekerja dengan berkurangnya jumlah variabel.
Dioptimalkan Binning menciptakan kelompok untuk kolom pilihan (seperti usia) dalam kaitannya dengan variabel lain. Tabel Simpan Excel untuk IBM SPSS Statistik asli file data Untuk manajemen data tambahan dan kemampuan analisis, Anda mungkin ingin mempertimbangkan update ke versi lengkap dari IBM SPSS Statistics. Apakah Anda memilih untuk melakukan hal ini dalam waktu jangka panjang dekat atau, Anda akan dapat menggunakan tabel Excel Anda di IBM SPSS Statistics. IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk menyimpan tabel Excel di file data IBM SPSS Statistics-diformat. Grafik distribusi ini menunjukkan nilai moneter rata-rata untuk kategori didefinisikan berdasar dan frekuensi skor. Daerah gelap menunjukkan nilai moneter rata yang lebih tinggi. Dalam contoh ini, pelanggan yang paling baru dan sering juga memiliki nilai moneter rata yang lebih tinggi. Tentukan Properti Variabel klasifikasi pohon ini memprediksi harga rata-rata orang akan membayar untuk mobil. Setiap node dari pohon menampilkan mean (rata-rata) harga yang harus dibayar, standar deviasi, dan jumlah kasus (baris) dalam node. Contoh ini menunjukkan bahwa pendapatan adalah faktor yang paling penting yang mempengaruhi harga pembelian rata-rata. Tentukan Properti Variabel Lihat distribusi data dan menyesuaikan cutpoints di Bin Nilai dialog. Tentukan Properti Variabel Selengkapnya tentang Statistik Family.
Selama beberapa dekade, para analis telah mengandalkan IBM SPSS Statistik untuk membantu mereka memandu melalui analisis data pengambilan keputusan. IBM SPSS Keuntungan untuk Excel 2007 menyediakan karena teknik IBM SPSS Statistics, ditambah kemampuan untuk mengakses, mengelola dan menganalisis sejumlah besar data. Ini berarti Anda dapat menemukan informasi dalam data Anda bahkan jika Anda dona € ™ t memiliki pengetahuan rinci tentang statistik. IBM SPSS Keuntungan untuk Microsoft Excel termasuk 10 prosedur khusus dipilih untuk memungkinkan pengguna bisnis untuk menggunakan penyiapan data dan analisis canggih alat dalam Excel. Secara khusus, ia memiliki prosedur untuk melakukan kebaruan, frekuensi dan nilai moneter (RFM) analisis. Wizards memandu Anda melalui langkah-langkah untuk membantu Anda mengelola dan mengeksplorasi data, menemukan nilai dalam dataset besar dan melakukan analisis. Persiapan IBM SPSS
Keuntungan untuk Microsoft Excel mulus terintegrasi ke antarmuka Excel. Cukup klik pada â € œIBM SPSS Advantageâ € ?? dari menu Excel,dan pilih prosedur dari pita untuk memulai. Setiap fungsi IBM SPSS Statistics dioperasikan melalui wizard atau dialog tab, sehingga mudah bagi Anda untuk mendapatkan hasil. Anda dona € ™ t perlu scripting atau pemrograman keterampilan sering dibutuhkan untuk memanfaatkan produk statistik yang kompleks. Melakukan analisis RFM muat, frekuensi dan nilai moneter (RFM) analisis adalah teknik yang sering digunakan dalam pemasaran langsung untuk mengidentifikasi pelanggan yang paling menguntungkan Anda. Pengalaman menunjukkan bahwa kebaruan (waktu terbaru Anda memiliki interaksi dengan pelanggan), frekuensi (jumlah interaksi Anda memiliki Anda telah dengan pelanggan), dan nilai moneter (jumlah uang yang telah Anda terima dari pelanggan) adalah prediktor terbaik dari kecenderungan untuk membeli dari Anda di masa depan. Dengan IBM SPSS Keuntungan untuk Microsoft Excel, Anda dapat dengan mudah melakukan analisis RFM untuk mengidentifikasi pelanggan ini. Wizards membantu Anda membuat skor RFM untuk pelanggan atau transaksi data dengan melangkah Anda melalui analisis RFM. IBM SPSS Keuntungan untuk Excel 2007 juga menghasilkan grafik untuk tes diagnostik, yang membantu Anda memahami distribusi data Anda. Setelah Anda memiliki hasil, youâ € ™ akan siap untuk pasar untuk pelanggan lama yang paling mungkin untuk menanggapi tawaran baru. Mudah mengidentifikasi kelompok IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk membuat pohon klasifikasi yang sangat visual yang membantu Anda mengidentifikasi segmen pasar. Misalnya, menggunakan pohon klasifikasi untuk mengidentifikasi karakteristik pelanggan cenderung membeli jenis produk tertentu. Karena Anda menampilkan hasil visual, Anda dapat lebih jelas melihat hubungan dalam data Anda. Analisis pohon klasifikasi canggih, namun mudah digunakan ini memungkinkan Anda untuk menjelajahi hasil dan menemukan subkelompok tertentu dan hubungan dalam data Anda bahwa Anda mungkin tidak menemukan dengan menggunakan statistik dalam Excel. Cari data yang tidak biasa Sekarang dataset Excel dapat lebih besar dari sebelumnya, ita € ™ s tidak mungkin lagi untuk â € œeyeballâ € ?? data Anda untuk memastikan tidak ada yang salah. Selain itu, lebih banyak data berarti risiko yang lebih tinggi dari data yang buruk. Sebuah prosedur tertentu dalam IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk menangkap data yang masalah sehingga Anda dapat menghapus atau memperbaiki mereka sebelum analisis. Gunakan prosedur ini untuk mendeteksi nilai yang tidak valid yang disebabkan oleh kesalahan entri data dan untuk mendeteksi kasus yang benar-benar tidak
biasa yang cocok untuk analisis. IBM SPSS Keuntungan untuk Microsoft Excel akan menyoroti sel data dan memberikan penjelasan singkat mengapa itu menemukan anomali. Menyiapkan dan mengubah data IBM SPSS Keuntungan untuk Microsoft Excel menyediakan Anda dengan prosedur yang memungkinkan Anda untuk mempersiapkan dan mengubah data. Gunakan prosedur ini untuk mengatur ulang data dan menempatkan mereka dalam format untuk membantu analisis. Selain itu, Anda mendapatkan lebih banyak pilihan untuk mengeksplorasi data, yang membuatnya lebih mudah untuk menemukan nilai dalam dataset yang lebih besar. Bergabunglah tabel â € "Dengan IBM SPSS Keuntungan untuk Microsoft
Excel, Anda dapat menggabungkan dua tabel Excel berdasarkan kriteria yang sesuai baris dalam satu meja dengan baris dalam tabel lainnya. Merestrukturisasi Data â € "Anda dapat merestrukturisasi tabel untuk menggabungkan informasi dari beberapa baris. Misalnya, menggunakan prosedur ini untuk merestrukturisasi data transaksional. Anda dapat membuat satu baris untuk setiap pelanggan, dengan setiap transaksi dicatat dalam kolom terpisah â € "memberikan cara baru untuk melihat data. Baris Agregat â € "Menggabungkan kelompok baris dalam tabel yang dipilih ke dalam baris tunggal untuk dengan mudah membuat yang baru, tabel yang berisi data agregat ringkasan untuk masing-masing kelompok. Misalnya, jika Anda memiliki sebuah meja yang mencatat setiap pembelian yang dilakukan oleh pelanggan pada baris terpisah dan mengidentifikasi setiap pelanggan dengan nilai ID yang unik, Anda dapat mengelompokkan catatan berdasarkan nilai ID. IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk membuat tabel dikumpulkan dengan satu baris untuk setiap pelanggan, menggunakan nilai ringkasan yang dipilih untuk kolom lain dari tabel asli. Data kelompok dalam rentang â € "Kadang-kadang Anda ingin â € œbinâ € ?? data sehingga Anda dapat melihat rentang nya. Misalnya, Anda mungkin ingin kelompok usia dengan rentang
(kurang dari 20, 20-29, 30-39, 40-49, dan sebagainya) untuk meneliti kebiasaan membeli dari kelompok usia yang berbeda. Nilai bin prosedur IBM SPSS Keuntungan untuk Microsoft Excel menyediakan antarmuka yang mudah digunakan untuk membangun rentang data. IBM SPSS Keuntungan untuk Microsoft Excel menyajikan anda dengan cutpoints otomatis mengatur bahwa Anda dapat menyesuaikan sesuai terbaik distribusi data Anda. Ketika Anda menyimpan nilai-nilai binned, IBM SPSS Keuntungan untuk Microsoft Excel menciptakan kolom baru yang berisi data dikelompokkan ke dalam rentang. Anda juga dapat membuat kolom yang berisi nilai-nilai teks baru yang menggambarkan setiap rentang, serta kolom yang berisi nilai integer sekuensial ditugaskan untuk setiap kategori rentang dalam urutan. Optimalkan sampah untuk model â € "Dengan IBM SPSS Keuntungan untuk Microsoft Excel, Anda dapat mengubah skala-tipe data dengan mendistribusikan nilai-nilai ke tempat sampah. Anda kemudian dapat menggunakan data binned bukan nilai data asli untuk analisis lebih lanjut. Misalnya, Anda mungkin ingin mengoptimalkan data ke tempat sampah untuk menjaga privasi sumber data. Alih-alih melaporkan nilai yang sebenarnya, Anda dapat menggunakan nomor binned. Selain itu, beberapa analisis lebih efisien ketika bekerja dengan berkurangnya jumlah variabel.
Dioptimalkan Binning menciptakan kelompok untuk kolom pilihan (seperti usia) dalam kaitannya dengan variabel lain. Tabel Simpan Excel untuk IBM SPSS Statistik asli file data Untuk manajemen data tambahan dan kemampuan analisis, Anda mungkin ingin mempertimbangkan update ke versi lengkap dari IBM SPSS Statistics. Apakah Anda memilih untuk melakukan hal ini dalam waktu jangka panjang dekat atau, Anda akan dapat menggunakan tabel Excel Anda di IBM SPSS Statistics. IBM SPSS Keuntungan untuk Microsoft Excel memungkinkan Anda untuk menyimpan tabel Excel di file data IBM SPSS Statistics-diformat.
Grafik distribusi ini menunjukkan nilai moneter rata-rata untuk kategori didefinisikan berdasar dan frekuensi skor. Daerah gelap menunjukkan nilai moneter rata yang lebih tinggi. Dalam contoh ini, pelanggan yang paling baru dan sering juga memiliki nilai moneter rata yang lebih tinggi. Tentukan Properti Variabel klasifikasi pohon ini memprediksi harga rata-rata orang akan membayar untuk mobil.
Setiap node dari pohon menampilkan mean (rata-rata) harga yang harus dibayar, standar deviasi, dan jumlah kasus (baris) dalam node. Contoh ini menunjukkan bahwa pendapatan adalah faktor yang paling penting yang mempengaruhi harga pembelian rata-rata. Tentukan Properti Variabel Lihat distribusi data dan menyesuaikan cutpoints di Bin Nilai dialog.
Klasifikasi pohon ini memprediksi harga rata-rata orang akan membayar untuk mobil. Setiap node dari pohon menampilkan mean (rata-rata) harga yang harus dibayar, standar deviasi, dan jumlah kasus (baris) dalam node. Contoh ini menunjukkan bahwa pendapatan adalah faktor yang paling penting yang mempengaruhi harga pembelian rata-rata.
Klasifikasi pohon ini memprediksi harga rata-rata orang akan membayar untuk mobil. Setiap node dari pohon menampilkan mean (rata-rata) harga yang harus dibayar, standar deviasi, dan jumlah kasus (baris) dalam node. Contoh ini menunjukkan bahwa pendapatan adalah faktor
yang paling penting yang mempengaruhi harga pembelian rata-rata.
Sebuah file sistem SPSS dibuat pada perintah dengan program SPSS itu sendiri, yang menghasilkan sebuah file biner yang dirancang untuk jenis tertentu dari komputer menggunakan sistem operasi yang ditunjuk. File ini dapat dibaca oleh program SPSS operasi pada komputer dan sistem operasi yang kompatibel. Sebuah sistem file tidak dapat dibaca oleh manusia normal - hanya dengan komputer dan sistem operasi yang diciptakan. Artinya, sistem file yang dibuat untuk komputer unix tidak dapat dibaca di kedua Windows atau komputer Macintosh.Namun, ada cara untuk mengekspor file sistem untuk impor berbagai jenis komputer. Perintah SPSS mengizinkan penggantian nama, menjatuhkan, dan penataan kembali variabel dalam file yang baru dibuat. Tugas ini juga dilakukan melalui perintah antarmuka.
Structural Equation Modeling (SEM)
Pemodelan persamaan struktural atau Structural equation modeling (SEM) adalah istilah umum yang digunakan untuk menggambarkan keluarga metode statistik yang dirancang untuk menguji model konseptual atau teoritis. Beberapa metode SEM umum termasuk analisis konfirmatori faktor, analisis jalur, dan pemodelan pertumbuhan laten. Istilah "model persamaan struktural" yang paling sering mengacu pada kombinasi dari dua hal: "model pengukuran" yang mendefinisikan variabel laten menggunakan satu atau lebih variabel yang diamati, dan "model regresi struktural" yang menghubungkan variabel laten bersama-sama. Bagian-bagian dari model persamaan struktural terkait satu sama lain dengan menggunakan sistem persamaan regresi simultan.
SEM banyak digunakan dalam ilmu-ilmu sosial karena kemampuannya untuk mengisolasi kesalahan pengamatan dari pengukuran variabel laten. Untuk memberikan contoh sederhana, konsep kecerdasan manusia tidak dapat diukur secara langsung sebagai salah satu bisa mengukur tinggi badan atau berat. Sebaliknya, psikolog mengembangkan teori kecerdasan dan menulis instrumen pengukuran dengan item (pertanyaan) yang dirancang untuk mengukur kecerdasan menurut teori mereka. Mereka kemudian akan menggunakan SEM untuk menguji teori mereka menggunakan data yang dikumpulkan dari orang-orang yang mengambil tes kecerdasan mereka. Dengan SEM, "kecerdasan" akan menjadi variabel laten dan item tes akan menjadi variabel yang diamati.
Sebuah model sederhana menunjukkan bahwa kecerdasan (yang diukur dengan lima pertanyaan) dapat memprediksi kinerja akademik (yang diukur dengan SAT, ACT, dan sekolah tinggi IPK) ditampilkan di bawah. Dalam diagram SEM, variabel laten biasanya ditampilkan sebagai oval dan mengamati variabel sebagai persegi panjang. Diagram di bawah menunjukkan bagaimana kesalahan (e) mempengaruhi setiap pertanyaan kecerdasan dan skor SAT, ACT, dan IPK, tetapi tidak mempengaruhi variabel laten. SEM memberikan perkiraan numerik untuk masing-masing parameter (panah) dalam model untuk menunjukkan kekuatan hubungan. Dengan demikian, selain menguji teori secara keseluruhan, SEM karena itu memungkinkan peneliti untuk mendiagnosa yang diamati variabel indikator yang baik dari variabel laten.
Studi modern biasanya menguji lebih spesifik model yang melibatkan beberapa teori, misalnya, Jansen, Scherer, dan Schroeders mempelajari bagaimana konsep diri siswa dan self-efficacy mempengaruhi hasil pendidikan. SEM juga digunakan dalam ilmu, bisnis, pendidikan, dan bidang lainnya. Terminologi longgar dan membingungkan telah dikaburkan apa SEM dilakukan dengan data. Secara khusus, PLS-PA (algoritma Lohmoller) cukup sering bingung dengan parsial kuadrat regresi, yang biasanya hanya disebut PLS. PLS regresi cenderung berguna dengan sangat besar, dataset multicolinear, dan menemukan aplikasi dalam spektroskopi. PLS-PA, sebaliknya, biasanya dipromosikan sebagai metode yang bekerja dengan dataset kecil ketika pendekatan estimasi lain gagal; meskipun anggapan ini, bahkan di tahun 1970-an, dikenal tidak benar; misalnya lihat (Dhrymes 1972, 1974; Dhrymes & amp; Erlat, 1972;. Dhrymes et al, 1972; Gupta, 1969; Sobel, 1982).
Kedua LISREL dan PLS-PA yang dipahami sebagai algoritma komputer berulang, dengan penekanan dari awal untuk menciptakan sebuah grafis dan data antarmuka entri diakses dan perluasan analisis jalur Wright. Komisi Cowles awal 'bekerja pada estimasi persamaan simultan berpusat pada Koopman dan algoritma Hood dari ekonomi transportasi dan routing yang optimal, dengan estimasi maksimum likelihood, dan perhitungan bentuk aljabar tertutup, seperti teknik pencarian solusi berulang terbatas pada hari-hari sebelum komputer. Anderson dan Rubin (1949, 1950) mengembangkan informasi yang terbatas maksimum estimator kemungkinan untuk parameter persamaan struktural tunggal, yang secara tidak langsung termasuk dua tahap kuadrat terkecil estimator dan distribusi asimtotik nya (Anderson, 2005) dan Farebrother. Dua tahap kuadrat terkecil awalnya diusulkan sebagai metode estimasi parameter dari persamaan struktural tunggal dalam sistem persamaan linear simultan, yang diperkenalkan oleh Theil (1953a, 1953b, 1961) dan lebih atau kurang secara independen oleh Basmann dan Sargan. Informasi yang terbatas estimasi kemungkinan maksimum Anderson akhirnya diimplementasikan dalam algoritma pencarian komputer, di mana ia bersaing dengan algoritma SEM berulang lainnya. Dari jumlah tersebut, dua tahap kuadrat terkecil adalah jauh metode yang paling banyak digunakan di tahun 1960-an dan awal 1970-an.
LISREL dan PLS jalan pendekatan pemodelan yang diperjuangkan di Komisi Cowles terutama oleh Nobelist Trygve Haavelmo, sedangkan asumsi yang mendasari LISREL dan PLS ditantang oleh ahli statistik seperti Freedman yang keberatan dengan "kegagalan mereka untuk membedakan antara asumsi kausal, implikasi statistik, dan kebijakan klaim telah menjadi salah satu alasan utama untuk kecurigaan dan kebingungan sekitarnya metode kuantitatif dalam ilmu sosial "(lihat juga tanggapan Wold ini). Analisis jalur Haavelmo tidak pernah mendapatkan pengikut di antara US ekonometri, tapi berhasil dalam mempengaruhi generasi sesama statistik Skandinavia Haavelmo, termasuk Hermann
Wold, Karl Joreskog, dan Claes Fornell. Fornell diperkenalkan LISREL dan PLS teknik untuk banyak rekan Michigan melalui makalah berpengaruh dalam akuntansi (Fornell dan Larker 1981), dan sistem informasi (Davis, et al., 1989). Dhrymes (1971;. Dhrymes, et al 1974) memberikan bukti bahwa PLS memperkirakan asimtotik mendekati orang-orang dari dua tahap kuadrat terkecil dengan persamaan persis diidentifikasi. Hal ini lebih penting daripada akademik praktis, karena sebagian besar studi empiris overidentify. Tapi di satu sisi, semua metode informasi terbatas (OLS dikecualikan) menghasilkan hasil yang sama. kemajuan dalam komputer dan peningkatan eksponensial dalam penyimpanan data telah menciptakan banyak peluang baru untuk menerapkan metode persamaan struktural dalam analisis komputer-intensif dataset besar di kompleks, masalah tidak terstruktur. Teknik solusi yang paling populer jatuh ke dalam tiga kelas dari algoritma: biasa kuadrat algoritma diterapkan secara independen untuk setiap jalur, seperti yang diterapkan dalam yang disebut paket analisis jalur PLS yang dapat memperkirakan dengan OLS atau Plsr; analisis kovarians algoritma berkembang dari pekerjaan mani oleh Wold dan muridnya Karl Joreskog dilaksanakan di LISREL, AMOS, EQS, dan; dan persamaan simultan algoritma regresi dikembangkan di Komisi Cowles oleh Tjalling Koopmans. Popularitas SEM metode analisis jalur dalam ilmu sosial ulang proyek-fl kausal yang lebih holistik, dan kurang terang-terangan, interpretasi banyak fenomena dunia nyata - khususnya di bidang psikologi dan interaksi sosial - dari dapat diadopsi dalam ilmu alam. Arah dalam model jaringan diarahkan SEM muncul dari dugaan asumsi sebab-akibat yang dibuat tentang realitas. Interaksi sosial dan artefak sering epiphenomena - fenomena sekunder yang sulit untuk langsung link ke kausal faktor. Contoh dari epiphenomenon fisiologis, misalnya, waktu untuk menyelesaikan sprint 100 meter yang. Aku mungkin bisa meningkatkan kecepatan berlari saya dari 12 detik untuk 11 detik - tapi saya akan mengalami kesulitan menghubungkan peningkatan itu untuk setiap faktor penyebab langsung, seperti diet, sikap, cuaca, dll 1 perbaikan kedua di sprint waktu adalah epiphenomenon - produk holistik interaksi banyak faktor individu.
Dua komponen utama model dibedakan dalam SEM: model struktural menunjukkan ketergantungan kausal potensial antara endogen dan variabel eksogen, dan model pengukuran menunjukkan hubungan antara variabel laten dan indikator mereka. Model analisis faktor eksplorasi dan Konfirmatori, misalnya, hanya berisi bagian pengukuran, sedangkan diagram jalur dapat dilihat sebagai SEM yang hanya berisi bagian struktural.
Sebuah modeler akan sering menentukan satu set model teoritis yang masuk akal untuk menilai apakah model yang diusulkan adalah yang terbaik dari himpunan model mungkin. Tidak hanya harus rekening modeler untuk alasan teoritis untuk membangun model seperti itu, tapi pemodel juga harus memperhitungkan jumlah titik data dan jumlah parameter yang model harus memperkirakan untuk mengidentifikasi model.
Model diidentifikasi adalah model di mana nilai parameter tertentu secara unik mengidentifikasi model, dan tidak ada formulasi setara lainnya dapat diberikan oleh nilai parameter yang berbeda. Sebuah titik data variabel dengan skor yang diamati, seperti variabel yang berisi nilai pada pertanyaan atau berapa kali responden membeli mobil. Parameter adalah nilai bunga, yang mungkin menjadi koefisien regresi antara eksogen dan variabel endogen atau pemuatan faktor (koefisien regresi antara indikator dan faktor nya). Jika ada titik data lebih sedikit dari jumlah yang diperkirakan parameter, model yang dihasilkan adalah "tak dikenal", karena ada terlalu sedikit titik referensi untuk memperhitungkan semua varian dalam model. Solusinya adalah dengan membatasi salah satu jalur ke nol, yang berarti bahwa itu tidak lagi merupakan bagian dari model.
Estimasi parameter dilakukan dengan membandingkan matriks kovarians yang sebenarnya mewakili hubungan antara variabel dan matriks kovarians diperkirakan dari model pas terbaik. Hal ini diperoleh melalui maksimalisasi numerik dari kriteria fit seperti yang disediakan oleh estimasi maksimum likelihood, estimasi kemungkinan kuasi-maksimum, tertimbang kuadrat atau metode distribusi bebas asimtotik. Hal ini sering dilakukan dengan menggunakan program analisis SEM khusus, yang beberapa ada.
Hal ini penting untuk memeriksa "cocok" dari model diperkirakan untuk menentukan seberapa baik model data. Ini adalah tugas dasar dalam pemodelan SEM: membentuk dasar untuk menerima atau menolak model dan, lebih biasanya, menerima satu model yang bersaing di atas yang lain. Output dari program SEM meliputi matriks hubungan diperkirakan antara variabel dalam model. Penilaian fit dasarnya menghitung seberapa mirip data diprediksi adalah untuk matriks yang mengandung hubungan dalam data yang sebenarnya.
Uji statistik formal dan fit indeks telah dikembangkan untuk tujuan ini. Parameter individu model juga dapat diperiksa dalam model estimasi untuk melihat seberapa baik model yang diusulkan sesuai dengan teori mengemudi. Kebanyakan, meskipun tidak semua, metode estimasi membuat tes seperti model mungkin.
Tentu saja seperti dalam semua tes hipotesis statistik, model tes SEM didasarkan pada asumsi bahwa data yang relevan yang benar dan lengkap telah dimodelkan. Dalam literatur SEM, pembahasan fit telah menyebabkan berbagai rekomendasi yang berbeda pada aplikasi yang tepat dari berbagai fit indeks dan tes hipotesis.
Ada yang berbeda pendekatan untuk menilai fit. Pendekatan tradisional untuk pemodelan awal dari hipotesis nol, penghargaan model yang lebih pelit (yaitu orang-orang dengan parameter bebas yang lebih sedikit), kepada orang lain seperti AIC yang fokus pada betapa sedikit nilai-nilai pas menyimpang dari model jenuh (yaitu seberapa baik mereka mereproduksi nilai yang terukur ), dengan mempertimbangkan sejumlah parameter bebas digunakan. Karena ukuran yang berbeda dari fit menangkap berbagai elemen fit dari model, adalah tepat untuk melaporkan pilihan tindakan fit berbeda. Pedoman (yaitu, "cutoff skor") untuk menafsirkan tindakan fit, termasuk yang tercantum di bawah ini, adalah subyek dari banyak perdebatan di kalangan peneliti SEM.
Untuk setiap ukuran fit, keputusan seperti apa mewakili cocok-cukup antara model dan data harus mencerminkan faktor-faktor kontekstual lainnya seperti ukuran sampel, rasio indikator untuk faktor, dan kompleksitas keseluruhan model. Misalnya, sampel yang sangat besar membuat uji Chi-kuadrat terlalu sensitif dan lebih mungkin untuk menunjukkan kurangnya model-data yang fit.
Model ini mungkin perlu dimodifikasi untuk meningkatkan fit, sehingga memperkirakan hubungan yang paling mungkin antara variabel. Banyak program memberikan indeks modifikasi yang dapat memandu modifikasi kecil. Indeks modifikasi melaporkan perubahan χ² yang dihasilkan dari membebaskan parameter tetap: biasanya, karena itu menambahkan jalan untuk model yang saat ini diatur ke nol.
Modifikasi yang meningkatkan model fit dapat ditandai sebagai perubahan potensial yang dapat dibuat untuk model. Modifikasi model, terutama model struktural, perubahan teori mengklaim untuk menjadi kenyataan. Modifikasi karena itu harus masuk akal dalam hal teori yang diuji, atau diakui sebagai batasan teori itu. Perubahan model pengukuran secara efektif mengklaim bahwa item / data indikator murni dari variabel laten ditentukan oleh teori.
Sementara para peneliti setuju bahwa ukuran sampel yang besar diperlukan untuk memberikan kekuatan statistik yang cukup dan perkiraan yang tepat menggunakan SEM, tidak ada konsensus umum tentang metode yang tepat untuk menentukan ukuran sampel yang memadai. Umumnya, pertimbangan untuk menentukan ukuran sampel meliputi jumlah pengamatan per parameter, jumlah pengamatan yang diperlukan untuk indeks fit untuk melakukan memadai, dan jumlah pengamatan per derajat kebebasan. Para peneliti telah mengusulkan pedoman berdasarkan studi simulasi (Chou & amp; Bentler, 1995), pengalaman profesional (Bentler dan Chou, 1987), dan formula matematika (MacCallum, Browne, dan Sugawara, 1996; Westland, 2010).
Perhatian harus selalu diambil ketika membuat klaim kausalitas bahkan ketika eksperimen atau studi waktu-memerintahkan telah dilakukan. Model kausal jangka harus dipahami: "model yang menyampaikan asumsi kausal," belum tentu model yang menghasilkan divalidasi kesimpulan kausal. Pengumpulan data di beberapa titik waktu dan menggunakan desain eksperimental atau quasi-eksperimental dapat membantu menyingkirkan hipotesis saingan tertentu tetapi bahkan percobaan acak tidak bisa mengesampingkan semua ancaman tersebut untuk kausal inferensi. Baik fit dengan model yang konsisten dengan satu kausal hipotesis selalu memerlukan fit sama baik oleh model lain yang konsisten dengan hipotesis kausal lawan. Tidak ada desain penelitian, tidak peduli seberapa pintar, dapat membantu membedakan hipotesis saingan seperti, kecuali percobaan intervensi.
SEM banyak digunakan dalam ilmu-ilmu sosial karena kemampuannya untuk mengisolasi kesalahan pengamatan dari pengukuran variabel laten. Untuk memberikan contoh sederhana, konsep kecerdasan manusia tidak dapat diukur secara langsung sebagai salah satu bisa mengukur tinggi badan atau berat. Sebaliknya, psikolog mengembangkan teori kecerdasan dan menulis instrumen pengukuran dengan item (pertanyaan) yang dirancang untuk mengukur kecerdasan menurut teori mereka. Mereka kemudian akan menggunakan SEM untuk menguji teori mereka menggunakan data yang dikumpulkan dari orang-orang yang mengambil tes kecerdasan mereka. Dengan SEM, "kecerdasan" akan menjadi variabel laten dan item tes akan menjadi variabel yang diamati.
Sebuah model sederhana menunjukkan bahwa kecerdasan (yang diukur dengan lima pertanyaan) dapat memprediksi kinerja akademik (yang diukur dengan SAT, ACT, dan sekolah tinggi IPK) ditampilkan di bawah. Dalam diagram SEM, variabel laten biasanya ditampilkan sebagai oval dan mengamati variabel sebagai persegi panjang. Diagram di bawah menunjukkan bagaimana kesalahan (e) mempengaruhi setiap pertanyaan kecerdasan dan skor SAT, ACT, dan IPK, tetapi tidak mempengaruhi variabel laten. SEM memberikan perkiraan numerik untuk masing-masing parameter (panah) dalam model untuk menunjukkan kekuatan hubungan. Dengan demikian, selain menguji teori secara keseluruhan, SEM karena itu memungkinkan peneliti untuk mendiagnosa yang diamati variabel indikator yang baik dari variabel laten.
Studi modern biasanya menguji lebih spesifik model yang melibatkan beberapa teori, misalnya, Jansen, Scherer, dan Schroeders mempelajari bagaimana konsep diri siswa dan self-efficacy mempengaruhi hasil pendidikan. SEM juga digunakan dalam ilmu, bisnis, pendidikan, dan bidang lainnya. Terminologi longgar dan membingungkan telah dikaburkan apa SEM dilakukan dengan data. Secara khusus, PLS-PA (algoritma Lohmoller) cukup sering bingung dengan parsial kuadrat regresi, yang biasanya hanya disebut PLS. PLS regresi cenderung berguna dengan sangat besar, dataset multicolinear, dan menemukan aplikasi dalam spektroskopi. PLS-PA, sebaliknya, biasanya dipromosikan sebagai metode yang bekerja dengan dataset kecil ketika pendekatan estimasi lain gagal; meskipun anggapan ini, bahkan di tahun 1970-an, dikenal tidak benar; misalnya lihat (Dhrymes 1972, 1974; Dhrymes & amp; Erlat, 1972;. Dhrymes et al, 1972; Gupta, 1969; Sobel, 1982).
Kedua LISREL dan PLS-PA yang dipahami sebagai algoritma komputer berulang, dengan penekanan dari awal untuk menciptakan sebuah grafis dan data antarmuka entri diakses dan perluasan analisis jalur Wright. Komisi Cowles awal 'bekerja pada estimasi persamaan simultan berpusat pada Koopman dan algoritma Hood dari ekonomi transportasi dan routing yang optimal, dengan estimasi maksimum likelihood, dan perhitungan bentuk aljabar tertutup, seperti teknik pencarian solusi berulang terbatas pada hari-hari sebelum komputer. Anderson dan Rubin (1949, 1950) mengembangkan informasi yang terbatas maksimum estimator kemungkinan untuk parameter persamaan struktural tunggal, yang secara tidak langsung termasuk dua tahap kuadrat terkecil estimator dan distribusi asimtotik nya (Anderson, 2005) dan Farebrother. Dua tahap kuadrat terkecil awalnya diusulkan sebagai metode estimasi parameter dari persamaan struktural tunggal dalam sistem persamaan linear simultan, yang diperkenalkan oleh Theil (1953a, 1953b, 1961) dan lebih atau kurang secara independen oleh Basmann dan Sargan. Informasi yang terbatas estimasi kemungkinan maksimum Anderson akhirnya diimplementasikan dalam algoritma pencarian komputer, di mana ia bersaing dengan algoritma SEM berulang lainnya. Dari jumlah tersebut, dua tahap kuadrat terkecil adalah jauh metode yang paling banyak digunakan di tahun 1960-an dan awal 1970-an.
LISREL dan PLS jalan pendekatan pemodelan yang diperjuangkan di Komisi Cowles terutama oleh Nobelist Trygve Haavelmo, sedangkan asumsi yang mendasari LISREL dan PLS ditantang oleh ahli statistik seperti Freedman yang keberatan dengan "kegagalan mereka untuk membedakan antara asumsi kausal, implikasi statistik, dan kebijakan klaim telah menjadi salah satu alasan utama untuk kecurigaan dan kebingungan sekitarnya metode kuantitatif dalam ilmu sosial "(lihat juga tanggapan Wold ini). Analisis jalur Haavelmo tidak pernah mendapatkan pengikut di antara US ekonometri, tapi berhasil dalam mempengaruhi generasi sesama statistik Skandinavia Haavelmo, termasuk Hermann
Wold, Karl Joreskog, dan Claes Fornell. Fornell diperkenalkan LISREL dan PLS teknik untuk banyak rekan Michigan melalui makalah berpengaruh dalam akuntansi (Fornell dan Larker 1981), dan sistem informasi (Davis, et al., 1989). Dhrymes (1971;. Dhrymes, et al 1974) memberikan bukti bahwa PLS memperkirakan asimtotik mendekati orang-orang dari dua tahap kuadrat terkecil dengan persamaan persis diidentifikasi. Hal ini lebih penting daripada akademik praktis, karena sebagian besar studi empiris overidentify. Tapi di satu sisi, semua metode informasi terbatas (OLS dikecualikan) menghasilkan hasil yang sama. kemajuan dalam komputer dan peningkatan eksponensial dalam penyimpanan data telah menciptakan banyak peluang baru untuk menerapkan metode persamaan struktural dalam analisis komputer-intensif dataset besar di kompleks, masalah tidak terstruktur. Teknik solusi yang paling populer jatuh ke dalam tiga kelas dari algoritma: biasa kuadrat algoritma diterapkan secara independen untuk setiap jalur, seperti yang diterapkan dalam yang disebut paket analisis jalur PLS yang dapat memperkirakan dengan OLS atau Plsr; analisis kovarians algoritma berkembang dari pekerjaan mani oleh Wold dan muridnya Karl Joreskog dilaksanakan di LISREL, AMOS, EQS, dan; dan persamaan simultan algoritma regresi dikembangkan di Komisi Cowles oleh Tjalling Koopmans. Popularitas SEM metode analisis jalur dalam ilmu sosial ulang proyek-fl kausal yang lebih holistik, dan kurang terang-terangan, interpretasi banyak fenomena dunia nyata - khususnya di bidang psikologi dan interaksi sosial - dari dapat diadopsi dalam ilmu alam. Arah dalam model jaringan diarahkan SEM muncul dari dugaan asumsi sebab-akibat yang dibuat tentang realitas. Interaksi sosial dan artefak sering epiphenomena - fenomena sekunder yang sulit untuk langsung link ke kausal faktor. Contoh dari epiphenomenon fisiologis, misalnya, waktu untuk menyelesaikan sprint 100 meter yang. Aku mungkin bisa meningkatkan kecepatan berlari saya dari 12 detik untuk 11 detik - tapi saya akan mengalami kesulitan menghubungkan peningkatan itu untuk setiap faktor penyebab langsung, seperti diet, sikap, cuaca, dll 1 perbaikan kedua di sprint waktu adalah epiphenomenon - produk holistik interaksi banyak faktor individu.
Dua komponen utama model dibedakan dalam SEM: model struktural menunjukkan ketergantungan kausal potensial antara endogen dan variabel eksogen, dan model pengukuran menunjukkan hubungan antara variabel laten dan indikator mereka. Model analisis faktor eksplorasi dan Konfirmatori, misalnya, hanya berisi bagian pengukuran, sedangkan diagram jalur dapat dilihat sebagai SEM yang hanya berisi bagian struktural.
Sebuah modeler akan sering menentukan satu set model teoritis yang masuk akal untuk menilai apakah model yang diusulkan adalah yang terbaik dari himpunan model mungkin. Tidak hanya harus rekening modeler untuk alasan teoritis untuk membangun model seperti itu, tapi pemodel juga harus memperhitungkan jumlah titik data dan jumlah parameter yang model harus memperkirakan untuk mengidentifikasi model.
Model diidentifikasi adalah model di mana nilai parameter tertentu secara unik mengidentifikasi model, dan tidak ada formulasi setara lainnya dapat diberikan oleh nilai parameter yang berbeda. Sebuah titik data variabel dengan skor yang diamati, seperti variabel yang berisi nilai pada pertanyaan atau berapa kali responden membeli mobil. Parameter adalah nilai bunga, yang mungkin menjadi koefisien regresi antara eksogen dan variabel endogen atau pemuatan faktor (koefisien regresi antara indikator dan faktor nya). Jika ada titik data lebih sedikit dari jumlah yang diperkirakan parameter, model yang dihasilkan adalah "tak dikenal", karena ada terlalu sedikit titik referensi untuk memperhitungkan semua varian dalam model. Solusinya adalah dengan membatasi salah satu jalur ke nol, yang berarti bahwa itu tidak lagi merupakan bagian dari model.
Estimasi parameter dilakukan dengan membandingkan matriks kovarians yang sebenarnya mewakili hubungan antara variabel dan matriks kovarians diperkirakan dari model pas terbaik. Hal ini diperoleh melalui maksimalisasi numerik dari kriteria fit seperti yang disediakan oleh estimasi maksimum likelihood, estimasi kemungkinan kuasi-maksimum, tertimbang kuadrat atau metode distribusi bebas asimtotik. Hal ini sering dilakukan dengan menggunakan program analisis SEM khusus, yang beberapa ada.
Hal ini penting untuk memeriksa "cocok" dari model diperkirakan untuk menentukan seberapa baik model data. Ini adalah tugas dasar dalam pemodelan SEM: membentuk dasar untuk menerima atau menolak model dan, lebih biasanya, menerima satu model yang bersaing di atas yang lain. Output dari program SEM meliputi matriks hubungan diperkirakan antara variabel dalam model. Penilaian fit dasarnya menghitung seberapa mirip data diprediksi adalah untuk matriks yang mengandung hubungan dalam data yang sebenarnya.
Uji statistik formal dan fit indeks telah dikembangkan untuk tujuan ini. Parameter individu model juga dapat diperiksa dalam model estimasi untuk melihat seberapa baik model yang diusulkan sesuai dengan teori mengemudi. Kebanyakan, meskipun tidak semua, metode estimasi membuat tes seperti model mungkin.
Tentu saja seperti dalam semua tes hipotesis statistik, model tes SEM didasarkan pada asumsi bahwa data yang relevan yang benar dan lengkap telah dimodelkan. Dalam literatur SEM, pembahasan fit telah menyebabkan berbagai rekomendasi yang berbeda pada aplikasi yang tepat dari berbagai fit indeks dan tes hipotesis.
Ada yang berbeda pendekatan untuk menilai fit. Pendekatan tradisional untuk pemodelan awal dari hipotesis nol, penghargaan model yang lebih pelit (yaitu orang-orang dengan parameter bebas yang lebih sedikit), kepada orang lain seperti AIC yang fokus pada betapa sedikit nilai-nilai pas menyimpang dari model jenuh (yaitu seberapa baik mereka mereproduksi nilai yang terukur ), dengan mempertimbangkan sejumlah parameter bebas digunakan. Karena ukuran yang berbeda dari fit menangkap berbagai elemen fit dari model, adalah tepat untuk melaporkan pilihan tindakan fit berbeda. Pedoman (yaitu, "cutoff skor") untuk menafsirkan tindakan fit, termasuk yang tercantum di bawah ini, adalah subyek dari banyak perdebatan di kalangan peneliti SEM.
Untuk setiap ukuran fit, keputusan seperti apa mewakili cocok-cukup antara model dan data harus mencerminkan faktor-faktor kontekstual lainnya seperti ukuran sampel, rasio indikator untuk faktor, dan kompleksitas keseluruhan model. Misalnya, sampel yang sangat besar membuat uji Chi-kuadrat terlalu sensitif dan lebih mungkin untuk menunjukkan kurangnya model-data yang fit.
Model ini mungkin perlu dimodifikasi untuk meningkatkan fit, sehingga memperkirakan hubungan yang paling mungkin antara variabel. Banyak program memberikan indeks modifikasi yang dapat memandu modifikasi kecil. Indeks modifikasi melaporkan perubahan χ² yang dihasilkan dari membebaskan parameter tetap: biasanya, karena itu menambahkan jalan untuk model yang saat ini diatur ke nol.
Modifikasi yang meningkatkan model fit dapat ditandai sebagai perubahan potensial yang dapat dibuat untuk model. Modifikasi model, terutama model struktural, perubahan teori mengklaim untuk menjadi kenyataan. Modifikasi karena itu harus masuk akal dalam hal teori yang diuji, atau diakui sebagai batasan teori itu. Perubahan model pengukuran secara efektif mengklaim bahwa item / data indikator murni dari variabel laten ditentukan oleh teori.
Sementara para peneliti setuju bahwa ukuran sampel yang besar diperlukan untuk memberikan kekuatan statistik yang cukup dan perkiraan yang tepat menggunakan SEM, tidak ada konsensus umum tentang metode yang tepat untuk menentukan ukuran sampel yang memadai. Umumnya, pertimbangan untuk menentukan ukuran sampel meliputi jumlah pengamatan per parameter, jumlah pengamatan yang diperlukan untuk indeks fit untuk melakukan memadai, dan jumlah pengamatan per derajat kebebasan. Para peneliti telah mengusulkan pedoman berdasarkan studi simulasi (Chou & amp; Bentler, 1995), pengalaman profesional (Bentler dan Chou, 1987), dan formula matematika (MacCallum, Browne, dan Sugawara, 1996; Westland, 2010).
Perhatian harus selalu diambil ketika membuat klaim kausalitas bahkan ketika eksperimen atau studi waktu-memerintahkan telah dilakukan. Model kausal jangka harus dipahami: "model yang menyampaikan asumsi kausal," belum tentu model yang menghasilkan divalidasi kesimpulan kausal. Pengumpulan data di beberapa titik waktu dan menggunakan desain eksperimental atau quasi-eksperimental dapat membantu menyingkirkan hipotesis saingan tertentu tetapi bahkan percobaan acak tidak bisa mengesampingkan semua ancaman tersebut untuk kausal inferensi. Baik fit dengan model yang konsisten dengan satu kausal hipotesis selalu memerlukan fit sama baik oleh model lain yang konsisten dengan hipotesis kausal lawan. Tidak ada desain penelitian, tidak peduli seberapa pintar, dapat membantu membedakan hipotesis saingan seperti, kecuali percobaan intervensi.
Sekelumit tentang Eviews
Apa Eviews Software
EViews dibangun di sekitar konsep objek. Seri, persamaan, dan sistem hanya beberapa contoh benda. Setiap objek memiliki jendela sendiri, menu sendiri, prosedur sendiri, dan pandangan sendiri datanya. Kebanyakan prosedur statistik hanya pandangan alternatif dari objek. Misalnya, pilihan menu sederhana dari jendela seri mengubah tampilan antara spreadsheet, garis dan grafik batang, tampilan histogram-dan-statistik, correlogram, dan uji unit root.
Statistik deskriptif dasar dengan mudah dihitung melalui seluruh sampel, dengan kategorisasi berdasarkan satu atau lebih variabel, atau dengan penampang atau periode di panel atau data dikumpulkan. Tes hipotesis mean, median dan varians dapat dilakukan, termasuk pengujian terhadap nilai-nilai tertentu, pengujian untuk kesetaraan antara seri, atau pengujian untuk kesetaraan dalam serangkaian tunggal ketika diklasifikasikan oleh variabel lain (yang memungkinkan Anda untuk melakukan ANOVA satu arah).
Anda dapat melihat grafis distribusi data Anda menggunakan histogram, atau distribusi kumulatif, selamat, dan plot kuantil. QQ-plot (plot kuantil-kuantil) dapat digunakan untuk membandingkan distribusi sepasang seri, atau distribusi dari serangkaian tunggal terhadap berbagai distribusi teoritis. Anda bahkan dapat melakukan Kolmogorov-Smirnov, Liliefors, Cramer von Mises, dan Anderson-Darling tes. untuk melihat apakah seri Anda didistribusikan secara normal, atau apakah itu berasal dari distribusi lain seperti, nilai ekstrem eksponensial, logistik, chi-square, Weibull , atau distribusi gamma. Anda dapat memberikan parameter untuk distribusi, atau membiarkan EViews memperkirakan parameter untuk Anda. EViews juga menghitung perkiraan kepadatan kernel, dan menghasilkan plot pencar dengan kurva fitting menggunakan biasa, transformasi, kernel, dan regresi tetangga terdekat.
EViews memberikan nomor acak generator (Knuth, L'Ecuyer atau Mersenne Twister-), fungsi kepadatan dan fungsi distribusi kumulatif selama delapan belas distribusi yang berbeda. Ini dapat digunakan dalam menghasilkan seri baru, atau dalam menghitung skalar dan matriks ekspresi.
EViews mencakup berbagai teknik estimasi persamaan tunggal dan ganda untuk kedua time series dan data cross section. Dasar estimator termasuk kotak biasa setidaknya (regresi berganda), dua-tahap kuadrat terkecil, dan nonlinier kuadrat. Estimasi tertimbang tersedia dengan semua teknik ini. Spesifikasi dapat mencakup struktur lag polinomial pada sejumlah variabel independen.
EViews mendukung estimasi GMM untuk kedua penampang dan data time series (tunggal dan persamaan multiple). Pilihan Pembobotan termasuk kovarians matriks Putih untuk data cross-section dan berbagai HAC kovarians matriks untuk data time series. Pilihan HAC termasuk prewhitening, baik kernel kuadrat atau Bartlett, dan tetap, Andrews, atau metode seleksi bandwidth Newey-West.
Ketika variabel dependen Anda mengambil satu set terbatas nilai atau disensor atau terpotong, EViews dapat mempertimbangkan informasi ini dalam prosedur estimasi. Biner, memerintahkan, disensor, dan model dipotong dapat diperkirakan untuk fungsi kemungkinan berdasarkan normal, logistik, dan kesalahan nilai ekstrim. Menghitung model dapat menggunakan Poisson, binomial negatif, dan kemungkinan (QML) spesifikasi kuasi-maksimum. EViews opsional melaporkan model linier umum atau kesalahan standar QML.
The EViews lingkungan berisi dua daerah dasar: Wilayah putih kosong pada gambar di atas adalah apa yang EViews mengacu sebagai Command Window. Anda dapat mengetik perintah langsung ke jendela ini dan mengeksekusi mereka dengan menekan tombol Enter. Daerah abu-abu besar di gambar di atas adalah apa yang EViews mengacu sebagai Wilayah Kerja. Di sinilah workfiles Anda, jendela data, grafik dan hasil estimasi akan ditampilkan.
Mendapatkan data yang Anda butuhkan untuk membuat keputusan yang paling diinformasikan dengan mengakses portofolio kami yang luas informasi, analisis, dan keahlian. Masuk ke pusat produk atau layanan pilihan Anda.
Cari solusi yang Anda butuhkan dengan mengakses portofolio kami yang luas informasi, analisis, dan keahlian. Tim IHS ahli materi pelajaran, analis, dan konsultan menawarkan kecerdasan ditindaklanjuti Anda butuhkan untuk membuat keputusan. Pemimpin bisnis global todayâ € ™ s butuhkan terpercaya, data yang akurat, memastikan keputusan yang paling diinformasikan mungkin. IHS menyediakan pasar global yang paling komprehensif, industri dan keahlian teknis yang tersedia. Dengan antarmuka yang intuitif dan salah satu set terbesar dari alat manajemen data yang tersedia, software ini pemodelan ekonometrik membantu Anda dengan cepat dan efisien membuat persamaan statistik dan peramalan. Manfaat dari yang terbaik di kelas fitur, termasuk 64-bit Windows dukungan memori yang besar, Object Linking and Embedding (OLE) dan cerdas mengedit jendela. Agar EViews hari ini sehingga Anda dapat :.
Mendapatkan data yang Anda butuhkan untuk membuat keputusan yang paling diinformasikan dengan mengakses portofolio kami yang luas informasi, analisis, dan keahlian. Masuk ke pusat produk atau layanan pilihan Anda. Cari solusi yang Anda butuhkan dengan mengakses portofolio kami yang luas informasi, analisis, dan keahlian. Tim IHS subjek ahli materi, analis, dan konsultan menawarkan kecerdasan ditindaklanjuti Anda perlu membuat informasi decisions.Research dan Pemikiran LeadershipIHS memberikan analisis kritis dan bimbingan mencakup bisnis tim global worldâ € ™ s paling penting issues.ExpertsA dari industri yang diakui ahli berkontribusi analysis.Customer RecognitionThe IHS Pelanggan Program tajam dan pemikiran Pengakuan menyoroti organisasi yang sukses dan individu yang menunjukkan kepemimpinan yang luar biasa melalui penggunaan informasi IHS.
TENTANG pemimpin bisnis global USTodayâ € ™ s butuhkan terpercaya, data yang akurat, memastikan keputusan yang paling mungkin informasi. IHS menyediakan pasar global yang paling komprehensif, industri dan keahlian teknis available.Executive ManagementThe ahli dan pemimpin yang menetapkan kursus untuk IHS dan 8,000+ karyawan worldwide.CustomersBased umpan balik Anda yang disurvei, kami berusaha untuk meningkatkan produk dan informasi kami terus. Survei Pelanggan Pertama kami membantu kami memberikan layanan yang diperlukan dan efektif Anda demand.Corporate SustainabilitySustainability mendorong seluruh perusahaan IHS. Ita € ™ s bagaimana kita melakukan bisnis dengan membimbing nilai-nilai dan budaya kita pada gagasan bahwa kita dapat membuat difference.CareersJoin pemimpin bisnis global yang didedikasikan untuk membantu bisnis membuat keputusan yang tepat. Menjadi bagian dari keluarga 8,000+ profesional global yang yang berkembang dalam lingkungan kerja yang menarik.
Pemimpin bisnis global todayâ € ™ s butuhkan terpercaya, data yang akurat, memastikan keputusan yang paling diinformasikan mungkin. IHS menyediakan pasar global yang paling komprehensif, industri dan keahlian teknis available.Executive ManagementThe ahli dan pemimpin yang menetapkan kursus untuk IHS dan 8,000+ karyawan worldwide.CustomersBased umpan balik Anda yang disurvei, kami berusaha untuk meningkatkan produk dan informasi kami terus. Survei Pelanggan Pertama kami membantu kami memberikan layanan yang diperlukan dan efektif Anda demand.Corporate SustainabilitySustainability mendorong seluruh perusahaan IHS. Ita € ™ s bagaimana kita melakukan bisnis dengan membimbing nilai-nilai dan budaya kita pada gagasan bahwa kita dapat membuat difference.CareersJoin pemimpin bisnis global yang didedikasikan untuk membantu bisnis membuat keputusan yang tepat. Menjadi bagian dari keluarga 8,000+ profesional global yang yang berkembang dalam lingkungan kerja yang menarik.
EViews memberikan analisis data yang canggih, regresi dan alat forecasting pada komputer menggunakan sistem operasi Windows. Dengan EViews Anda dapat dengan cepat mengembangkan hubungan statistik dari data Anda dan kemudian menggunakan hubungan untuk meramalkan nilai masa depan dari data. Area dimana EViews dapat berguna antara lain: analisis ilmiah data dan evaluasi, analisis keuangan, peramalan ekonomi makro, simulasi dan analisis biaya. EViews adalah versi baru dari satu set alat untuk memanipulasi data time series awalnya dikembangkan di software Processor Time Series. Pendahulu langsung dari EViews adalah MicroTSP, pertama kali dirilis pada tahun 1981. Meskipun sejarah ini, tidak ada yang di desain EViews 'yang membatasi untuk time series ekonomi. Bahkan proyek penampang cukup besar dapat ditangani di EViews. Bantuan tambahan termasuk link ke Pengguna Panduan (I dan II) dan Referensi Command semua dalam format pdf. Jika Anda memutuskan untuk mengikuti Pengguna Panduan saya Anda harus melirik sebagian Bagian I, EViews Fundamentals, dan melihat hati-hati pada bab 1 sampai 6, memberikan perhatian khusus pada pasal 2 yang merupakan demonstrasi diperpanjang perangkat lunak. Informasi ini dan demonstrasi juga merupakan bagian dari Topik EViews Bantuan.
Kombinasi kekuatan dan kemudahan penggunaan membuat EViews 8 paket yang ideal untuk siapa saja yang bekerja dengan time series, penampang, atau data longitudinal. Dengan EViews, Anda dengan cepat dan efisien dapat mengelola data Anda, melakukan analisis ekonometrik dan statistik, menghasilkan perkiraan atau simulasi model, dan menghasilkan grafik kualitas tinggi dan meja untuk publikasi atau dimasukkan dalam aplikasi lain.
* Catatan: tempat Student Version â € œsoftâ € ?? pembatasan kapasitas jumlah data (1.500 pengamatan per seri, 15.000 Total pengamatan, 60 benda) yang dapat disimpan atau diekspor. Siswa dapat, tanpa batasan, bekerja dengan sejumlah besar data, tetapi workfiles yang melebihi batas yang lembut tidak dapat disimpan maupun diekspor data.
* Catatan: Meskipun EViews 7 dan 8 akan berjalan pada sistem operasi 64bit, hanya EViews 8 datang dalam versi 64bit. Hal ini juga harus dicatat bahwa Excel add-in yang dilengkapi dengan EViews 7 memiliki versi 32bit saja, dan dengan demikian tidak akan berjalan di bawah versi 64bit dari Excel.
EViews 9 Kompatibilitas Catatan Pembahasan berikut menjelaskan EViews masalah kompatibilitas 8 bagi pengguna versi sebelumnya. Workfile Kompatibilitas Dengan beberapa pengecualian, EViews 9 workfiles yang kompatibel dengan EViews 8. Perhatikan bahwa benda berikut ini baru atau telah dimodifikasi Versi 9: Persamaan objek diperkirakan dengan metode yang menggunakan fitur baru (ambang batas regresif sion, ARDL, ML ARMA , ARFIMA.) Jika Anda sudah menyimpan workfiles mengandung salah satu objek di atas dan membukanya di EViews 7 atau sebelumnya, EViews akan menghapus objek yang tidak kompatibel dan memberitahu Anda bahwa satu atau lebih objek yang tidak membaca. Jika Anda kemudian simpan Workfile, Anda akan kehilangan obyek. Kami menyarankan Anda membuat salinan dari setiap workfiles yang berisi benda-benda ini jika Anda ingin menggunakan workfiles ini dalam versi sebelumnya dari EViews. Sebaliknya, ada beberapa metode estimasi yang baru dalam EViews 9, tetapi tidak dianggap cukup kompatibel. Dalam hal ini, Anda dapat membuka Workfile di sion ver- tua, tetapi beberapa masalah kompatibilitas tetap. Misalnya, jika Anda memperkirakan persamaan kuadrat terkecil nonlinier menggunakan mesin baru optimasi dan metode (misalnya, BFGS), persamaan asli akan dibaca dalam versi EViews, tapi pilihan baru akan diabaikan dalam versi sebelumnya dari EViews. Jika Anda kemudian reestimate persamaan di EViews 8 estimasi akan mempekerjakan metode yang lebih tua. Catatan di TERTENTU-partai bahwa ini menyiratkan bahwa Anda dapat melakukan tes Wald di EViews 8 menggunakan metode koefisien kovarians yang tidak tersedia di EViews 8. Sebaiknya hati-hati dalam pencampuran hasil antara versi.
Sejarah SPSS
Latar Belakang
Dua tema telah mendominasi evolusi SPSS Inc. sebagai perusahaan:
Teknologi SPSS telah membuat tugas analitis sulit lebih mudah melalui kemajuan dalam kegunaan dan akses data, memungkinkan lebih banyak orang untuk mendapatkan keuntungan dari penggunaan teknik kuantitatif dalam pengambilan keputusan; dan
keahlian domain perusahaan telah berpusat pada analisis data tentang orang pendapat mereka, sikap, dan perilaku.
Misi Perusahaan untuk "mendorong meluasnya penggunaan data dalam pengambilan keputusan" berasal langsung dari dua tema ini. kesuksesan perusahaan telah didasarkan pada kemampuannya untuk menunjukkan manfaat yang sangat nyata bahwa penggunaan teknologi SPSS menyediakan. Mendasari kemampuan ini adalah keyakinan kolektif yang menganalisis data, dan menggabungkan hasilnya ke dalam proses pengambilan keputusan, mengarah ke keputusan yang lebih baik.
Asal-usul SPSS
Pada tahun 1968, Norman H. Nie, C. bin Hadlai (Tex) Hull dan Dale H. Bent, tiga orang muda dari latar belakang profesional yang berbeda, mengembangkan sistem perangkat lunak berdasarkan ide menggunakan statistik untuk mengubah data mentah menjadi informasi penting untuk para pengambil pembuatan. Ketiga inovator adalah perintis di bidang mereka, visioner yang diakui awal bahwa data dan bagaimana Anda menganalisis itu adalah kekuatan pendorong di belakang suara pengambilan keputusan-DNA kecerdasan.
sistem perangkat lunak statistik yang revolusioner ini disebut SPSS, yang berdiri untuk Paket statistik untuk Ilmu Sosial. Nie, Hull dan Bent dikembangkan SPSS dari kebutuhan untuk cepat menganalisis volume data ilmu sosial yang dikumpulkan melalui berbagai metode penelitian. Pekerjaan awal pada SPSS dilakukan di Stanford University dengan maksud untuk membuatnya tersedia hanya untuk konsumsi lokal dan tidak distribusi internasional. Nie, seorang ilmuwan sosial dan kandidat doktor Stanford, mewakili target audiens dan mengatur persyaratan; Bent, seorang kandidat doktor Universitas Stanford di riset operasi, memiliki keahlian analisis dan merancang struktur sistem file SPSS; dan Hull, yang baru saja lulus dari Stanford dengan gelar master administrasi bisnis, diprogram.
Seperti khas dari kreasi lahir dari kebutuhan, SPSS cepat tertangkap di universitas di seluruh Amerika dan segera permintaan. Hal ini juga menjadi jelas bagi para pengembang SPSS bahwa mereka memiliki lebih banyak di tangan mereka dari satu, metode yang efisien efektif menganalisis data; mereka memiliki produk yang layak. Selain karya akademis mereka, mereka sekarang perlu mempertimbangkan harga, pengiriman dan isu-isu lain perdagangan. Mereka memastikan bahwa kaset dari kode sumber dikirim ke komunitas pengguna yang kecil, tapi antusias, dan terus dipertahankan dan ditingkatkan SPSS.
Setelah lulus sekolah tahun 1969, Nie bergabung dengan Universitas Nasional Opini Research Center Chicago. The University of Chicago dianggap SPSS properti intelektual penting dan mendorong pembangunan berkelanjutan Nie untuk sistem perangkat lunak. Nie berhasil merekrut Hull untuk bergabung dengannya di University of Chicago dengan mendorong dia untuk mengambil posisi sebagai kepala universitas Perhitungan Center. Bent, Kanada, memutuskan untuk tidak bergabung Nie dan Hull di Chicago, dan kembali ke Kanada di mana ia punya janji akademik di University of Alberta. Dengan Nie dan Hull menyulap kedua mereka tanggung jawab akademik dan SPSS, mereka terus bekerja dengan tekun menyebarkan kata dan daya tarik pasar SPSS.
Keberhasilan awal SPSS langsung terkait dengan kualitas dan ketersediaan dokumentasi yang menyertai perangkat lunak. McGraw-Hill diterbitkan manual SPSS pengguna pertama pada tahun 1970. Setelah pengguna yang tersedia di toko buku perguruan tinggi, permintaan untuk program melepas. Nie, Bent, dan Hull menerima royalti dari penjualan manual tapi tidak ada dari distribusi program. Dengan kata Nie ini, "Rasanya seperti Gillette menjual pisau cukur dengan biaya dan mendapatkan keuntungan yang dari pisau."
Dengan penjualan SPSS berkembang pesat, IRS ditentukan pada tahun 1971 bahwa SPSS adalah sebuah perusahaan software kecil, yang mengancam status non-profit dari University of Chicago di mana SPSS telah ditampung. Pada tahun 1975, SPSS didirikan dan dua pendiri, Nie dan Hull, tak satu pun pernah bermimpi menjalankan bisnis mereka sendiri, menjadi eksekutif perusahaan baru. Meskipun tidak memiliki modal usaha atau dukungan finansial, dua pengusaha ini dijamin untuk SPSS control universal dari pasar akademik karena fakta bahwa SPSS adalah, dan, kode portabel yang memungkinkan lembaga-lembaga akademis port ke sebagian besar mainframe besar sistem komputer, yang termasuk data Control 6000 series, Burroughs sistem yang besar, Univac 1108, GE (selanjutnya Honeywell) sistem yang besar, Digital Equipment Corporation (DEC) sistem yang besar. SPSS juga cepat menjadi berguna untuk pasar pemerintah dan komersial. NASA mulai menggunakan SPSS untuk waktu yang berarti antara kegagalan bagian dari pesawat luar angkasa di pertengahan 1970-an, dan Dinas Kehutanan Nasional yang digunakan perangkat lunak untuk insiden cedera dan pertemuan beruang di seluruh Nati
Sejarah IBM SPSS Statistics
Sejarah Singkat IBM SPSS Statistics
SPSS, yang merupakan singkatan dari Statistical Package for Social Sciences, dikembangkan pada tahun 1968 oleh Norman H. Nie, C. bin Hadlai (Tex) Hull dan Dale H. Bent dalam menanggapi kebutuhan untuk perangkat lunak yang bisa mengubah data mentah menjadi informasi penting untuk pengambilan keputusan.
Meskipun SPSS pertama kali digunakan di lembaga-lembaga akademis di seluruh Amerika, dengan cepat tertangkap di antara pasar pemerintah dan komersial. Beberapa awal pengguna SPSS penting termasuk: NASA, Forest Reserve Nasional, Procter & Gamble dan Anheuser-Busch.
Sejak awal, SSPS tetap menjadi pemimpin pasar dalam analisis prediktif dan lebih luas usaha sektor intelijen dengan memperhatikan dekat dengan pelanggan "kebutuhan dan tetap mengikuti kemajuan teknologi.
Dalam empat dekade terakhir, SPSS telah berkembang menjadi sebuah perusahaan internasional yang memberikan alat-alat analisis dan solusi untuk beberapa organisasi di seluruh dunia. Sementara perusahaan dan industri menggunakan SPSS bervariasi, mereka al berbagi keinginan bersama untuk mengumpulkan wawasan melalui analisis data.
Keberhasilan terbukti SPSS terus menunjukkan manfaat yang sangat nyata dari menggunakan analisis data untuk mendorong proses pengambilan keputusan dan meningkatkan hasil bisnis.
perusahaan Timeline
Ada lima tahap pertumbuhan dalam sejarah kelembagaan SPSS:
1968-1975
"SPSS menjadi sebuah produk," ketika teknologi ini pertama kali dikembangkan dan tumbuh sendiri sebagai perusahaan akademik. SPSS pendiri, Norman H. Nie, C. bin Hadlai (Tex) Hull dan Dale H. Bent, mendistribusikan kaset kode sumber untuk komunitas pengguna yang kecil, tapi antusias, sedangkan pemeliharaan dan peningkatan dilakukan oleh penulis asli.
1975-1984
"SPSS menjadi sebuah perusahaan." Perusahaan secara terpisah dimasukkan ketika pendapatan mengancam status non-profit lembaga hosting yang aslinya, Pusat Penelitian Opini Nasional di Universitas Chicago. Selama fase start-up ini, bisnis ini diselenggarakan dan sejumlah inisiatif pembangunan yang dilakukan.
1984-1992
"Usia PC," dengan Perusahaan tumbuh dari $ 18m ke $ 38m pada kekuatan yang memimpin pasar sistem analisis statistik untuk PC DOS. SPSS adalah yang pertama ke pasar dengan produk software statistik pada PC DOS.
1992-1996
"Usia Windows," dengan Perusahaan pengiriman versi Windows pertama dari paket software statistik pada tahun 1992. Versi ini melaju pendapatan menjadi $ 84m dengan tahun 1996. Bisnis ini difokuskan pada produk statistik, dan strategi akuisisi dilengkapi arah ini dengan membawa dalam produk statistik perusahaan lain, seperti SYSTAT (1994) dan Jandel (1996).
1997-2002
"Transisi ke perusahaan." Periode ini telah usia pertumbuhan dengan akuisisi dan munculnya aplikasi analitik sebagai pelengkap bisnis inti produk statistik. Perusahaan tumbuh dari $ 110m pada tahun 1997 untuk diproyeksikan $ 209m pada tahun 2002 melalui akuisisi dari Quantime (pasar perangkat lunak aplikasi penelitian), ISL (software data mining), Showcase (intelijen bisnis perangkat lunak untuk pasar menengah), NetGenesis (aplikasi analitis untuk Data web), LexiQuest (teks perangkat lunak pertambangan), dan netExs (antarmuka web untuk teknologi OLAP).
2003
analisis prediktif berhasil didirikan sebagai segmen pasar. SPSS memainkan peran pemikiran-kepemimpinan dalam munculnya selama 2003 dari analisis prediktif sebagai penting, segmen yang berbeda dalam sektor perangkat lunak bisnis intelijen yang lebih luas. analisis prediktif melengkapi dan meningkatkan teknologi informasi lainnya. Organisasi yang mempekerjakan analisis prediktif tidak hanya tahu apa yang telah terjadi, mereka juga tahu apa yang mungkin terjadi selanjutnya. Yang paling penting, mereka tahu apa yang harus dilakukan tentang hal itu dengan menggunakan pengetahuan ini untuk meningkatkan pendapatan, mengurangi biaya, dan meningkatkan hasil. SPSS melihat tumbuh kesadaran dari manfaat ini antara komersial, sektor publik, dan organisasi akademis servis nya. Untuk meningkatkan fokus pada analisis prediktif, SPSS diakuisisi DataDistilleries berbasis di Belanda, penyedia aplikasi analitik prediktif pada bulan November 2003.
2004
aplikasi analitik prediktif datang usia. Pada tahun 2004, SPSS mempercepat pengenalan aplikasi analisis prediktif, memanfaatkan keterampilan dan mengintegrasikan teknologi dari akuisisi baru-baru, termasuk DataDistilleries. Sebuah versi baru dari prediksi Pemasaran diperkenalkan, serta aplikasi baru, Predictive Call Center. pekerjaan pembangunan tambahan mengatur panggung untuk lebih aplikasi yang akan diperkenalkan pada tahun 2005.
Hari ini
SPSS diakui sebagai pemimpin dalam ruang pasar analisis prediktif. analisis prediktif, yang menggabungkan analisis canggih dan optimasi keputusan, akan terus menjadi fokus bagi organisasi karena berusaha untuk meningkatkan pemahaman pasar manfaat bisnis yang analisis prediktif menyediakan.
modul
IBM SPSS Statistics adalah modular, terintegrasi, lini produk dengan fitur lengkap untuk proses-perencanaan analitis, pengumpulan data, akses data,
keywords: olah data spss statistik
EViews dibangun di sekitar konsep objek. Seri, persamaan, dan sistem hanya beberapa contoh benda. Setiap objek memiliki jendela sendiri, menu sendiri, prosedur sendiri, dan pandangan sendiri datanya. Kebanyakan prosedur statistik hanya pandangan alternatif dari objek. Misalnya, pilihan menu sederhana dari jendela seri mengubah tampilan antara spreadsheet, garis dan grafik batang, tampilan histogram-dan-statistik, correlogram, dan uji unit root.
Statistik deskriptif dasar dengan mudah dihitung melalui seluruh sampel, dengan kategorisasi berdasarkan satu atau lebih variabel, atau dengan penampang atau periode di panel atau data dikumpulkan. Tes hipotesis mean, median dan varians dapat dilakukan, termasuk pengujian terhadap nilai-nilai tertentu, pengujian untuk kesetaraan antara seri, atau pengujian untuk kesetaraan dalam serangkaian tunggal ketika diklasifikasikan oleh variabel lain (yang memungkinkan Anda untuk melakukan ANOVA satu arah).
Anda dapat melihat grafis distribusi data Anda menggunakan histogram, atau distribusi kumulatif, selamat, dan plot kuantil. QQ-plot (plot kuantil-kuantil) dapat digunakan untuk membandingkan distribusi sepasang seri, atau distribusi dari serangkaian tunggal terhadap berbagai distribusi teoritis. Anda bahkan dapat melakukan Kolmogorov-Smirnov, Liliefors, Cramer von Mises, dan Anderson-Darling tes. untuk melihat apakah seri Anda didistribusikan secara normal, atau apakah itu berasal dari distribusi lain seperti, nilai ekstrem eksponensial, logistik, chi-square, Weibull , atau distribusi gamma. Anda dapat memberikan parameter untuk distribusi, atau membiarkan EViews memperkirakan parameter untuk Anda. EViews juga menghitung perkiraan kepadatan kernel, dan menghasilkan plot pencar dengan kurva fitting menggunakan biasa, transformasi, kernel, dan regresi tetangga terdekat.
EViews memberikan nomor acak generator (Knuth, L'Ecuyer atau Mersenne Twister-), fungsi kepadatan dan fungsi distribusi kumulatif selama delapan belas distribusi yang berbeda. Ini dapat digunakan dalam menghasilkan seri baru, atau dalam menghitung skalar dan matriks ekspresi.
EViews mencakup berbagai teknik estimasi persamaan tunggal dan ganda untuk kedua time series dan data cross section. Dasar estimator termasuk kotak biasa setidaknya (regresi berganda), dua-tahap kuadrat terkecil, dan nonlinier kuadrat. Estimasi tertimbang tersedia dengan semua teknik ini. Spesifikasi dapat mencakup struktur lag polinomial pada sejumlah variabel independen.
EViews mendukung estimasi GMM untuk kedua penampang dan data time series (tunggal dan persamaan multiple). Pilihan Pembobotan termasuk kovarians matriks Putih untuk data cross-section dan berbagai HAC kovarians matriks untuk data time series. Pilihan HAC termasuk prewhitening, baik kernel kuadrat atau Bartlett, dan tetap, Andrews, atau metode seleksi bandwidth Newey-West.
Ketika variabel dependen Anda mengambil satu set terbatas nilai atau disensor atau terpotong, EViews dapat mempertimbangkan informasi ini dalam prosedur estimasi. Biner, memerintahkan, disensor, dan model dipotong dapat diperkirakan untuk fungsi kemungkinan berdasarkan normal, logistik, dan kesalahan nilai ekstrim. Menghitung model dapat menggunakan Poisson, binomial negatif, dan kemungkinan (QML) spesifikasi kuasi-maksimum. EViews opsional melaporkan model linier umum atau kesalahan standar QML.
The EViews lingkungan berisi dua daerah dasar: Wilayah putih kosong pada gambar di atas adalah apa yang EViews mengacu sebagai Command Window. Anda dapat mengetik perintah langsung ke jendela ini dan mengeksekusi mereka dengan menekan tombol Enter. Daerah abu-abu besar di gambar di atas adalah apa yang EViews mengacu sebagai Wilayah Kerja. Di sinilah workfiles Anda, jendela data, grafik dan hasil estimasi akan ditampilkan.
Mendapatkan data yang Anda butuhkan untuk membuat keputusan yang paling diinformasikan dengan mengakses portofolio kami yang luas informasi, analisis, dan keahlian. Masuk ke pusat produk atau layanan pilihan Anda.
Cari solusi yang Anda butuhkan dengan mengakses portofolio kami yang luas informasi, analisis, dan keahlian. Tim IHS ahli materi pelajaran, analis, dan konsultan menawarkan kecerdasan ditindaklanjuti Anda butuhkan untuk membuat keputusan. Pemimpin bisnis global todayâ € ™ s butuhkan terpercaya, data yang akurat, memastikan keputusan yang paling diinformasikan mungkin. IHS menyediakan pasar global yang paling komprehensif, industri dan keahlian teknis yang tersedia. Dengan antarmuka yang intuitif dan salah satu set terbesar dari alat manajemen data yang tersedia, software ini pemodelan ekonometrik membantu Anda dengan cepat dan efisien membuat persamaan statistik dan peramalan. Manfaat dari yang terbaik di kelas fitur, termasuk 64-bit Windows dukungan memori yang besar, Object Linking and Embedding (OLE) dan cerdas mengedit jendela. Agar EViews hari ini sehingga Anda dapat :.
Mendapatkan data yang Anda butuhkan untuk membuat keputusan yang paling diinformasikan dengan mengakses portofolio kami yang luas informasi, analisis, dan keahlian. Masuk ke pusat produk atau layanan pilihan Anda. Cari solusi yang Anda butuhkan dengan mengakses portofolio kami yang luas informasi, analisis, dan keahlian. Tim IHS subjek ahli materi, analis, dan konsultan menawarkan kecerdasan ditindaklanjuti Anda perlu membuat informasi decisions.Research dan Pemikiran LeadershipIHS memberikan analisis kritis dan bimbingan mencakup bisnis tim global worldâ € ™ s paling penting issues.ExpertsA dari industri yang diakui ahli berkontribusi analysis.Customer RecognitionThe IHS Pelanggan Program tajam dan pemikiran Pengakuan menyoroti organisasi yang sukses dan individu yang menunjukkan kepemimpinan yang luar biasa melalui penggunaan informasi IHS.
TENTANG pemimpin bisnis global USTodayâ € ™ s butuhkan terpercaya, data yang akurat, memastikan keputusan yang paling mungkin informasi. IHS menyediakan pasar global yang paling komprehensif, industri dan keahlian teknis available.Executive ManagementThe ahli dan pemimpin yang menetapkan kursus untuk IHS dan 8,000+ karyawan worldwide.CustomersBased umpan balik Anda yang disurvei, kami berusaha untuk meningkatkan produk dan informasi kami terus. Survei Pelanggan Pertama kami membantu kami memberikan layanan yang diperlukan dan efektif Anda demand.Corporate SustainabilitySustainability mendorong seluruh perusahaan IHS. Ita € ™ s bagaimana kita melakukan bisnis dengan membimbing nilai-nilai dan budaya kita pada gagasan bahwa kita dapat membuat difference.CareersJoin pemimpin bisnis global yang didedikasikan untuk membantu bisnis membuat keputusan yang tepat. Menjadi bagian dari keluarga 8,000+ profesional global yang yang berkembang dalam lingkungan kerja yang menarik.
Pemimpin bisnis global todayâ € ™ s butuhkan terpercaya, data yang akurat, memastikan keputusan yang paling diinformasikan mungkin. IHS menyediakan pasar global yang paling komprehensif, industri dan keahlian teknis available.Executive ManagementThe ahli dan pemimpin yang menetapkan kursus untuk IHS dan 8,000+ karyawan worldwide.CustomersBased umpan balik Anda yang disurvei, kami berusaha untuk meningkatkan produk dan informasi kami terus. Survei Pelanggan Pertama kami membantu kami memberikan layanan yang diperlukan dan efektif Anda demand.Corporate SustainabilitySustainability mendorong seluruh perusahaan IHS. Ita € ™ s bagaimana kita melakukan bisnis dengan membimbing nilai-nilai dan budaya kita pada gagasan bahwa kita dapat membuat difference.CareersJoin pemimpin bisnis global yang didedikasikan untuk membantu bisnis membuat keputusan yang tepat. Menjadi bagian dari keluarga 8,000+ profesional global yang yang berkembang dalam lingkungan kerja yang menarik.
EViews memberikan analisis data yang canggih, regresi dan alat forecasting pada komputer menggunakan sistem operasi Windows. Dengan EViews Anda dapat dengan cepat mengembangkan hubungan statistik dari data Anda dan kemudian menggunakan hubungan untuk meramalkan nilai masa depan dari data. Area dimana EViews dapat berguna antara lain: analisis ilmiah data dan evaluasi, analisis keuangan, peramalan ekonomi makro, simulasi dan analisis biaya. EViews adalah versi baru dari satu set alat untuk memanipulasi data time series awalnya dikembangkan di software Processor Time Series. Pendahulu langsung dari EViews adalah MicroTSP, pertama kali dirilis pada tahun 1981. Meskipun sejarah ini, tidak ada yang di desain EViews 'yang membatasi untuk time series ekonomi. Bahkan proyek penampang cukup besar dapat ditangani di EViews. Bantuan tambahan termasuk link ke Pengguna Panduan (I dan II) dan Referensi Command semua dalam format pdf. Jika Anda memutuskan untuk mengikuti Pengguna Panduan saya Anda harus melirik sebagian Bagian I, EViews Fundamentals, dan melihat hati-hati pada bab 1 sampai 6, memberikan perhatian khusus pada pasal 2 yang merupakan demonstrasi diperpanjang perangkat lunak. Informasi ini dan demonstrasi juga merupakan bagian dari Topik EViews Bantuan.
Kombinasi kekuatan dan kemudahan penggunaan membuat EViews 8 paket yang ideal untuk siapa saja yang bekerja dengan time series, penampang, atau data longitudinal. Dengan EViews, Anda dengan cepat dan efisien dapat mengelola data Anda, melakukan analisis ekonometrik dan statistik, menghasilkan perkiraan atau simulasi model, dan menghasilkan grafik kualitas tinggi dan meja untuk publikasi atau dimasukkan dalam aplikasi lain.
* Catatan: tempat Student Version â € œsoftâ € ?? pembatasan kapasitas jumlah data (1.500 pengamatan per seri, 15.000 Total pengamatan, 60 benda) yang dapat disimpan atau diekspor. Siswa dapat, tanpa batasan, bekerja dengan sejumlah besar data, tetapi workfiles yang melebihi batas yang lembut tidak dapat disimpan maupun diekspor data.
* Catatan: Meskipun EViews 7 dan 8 akan berjalan pada sistem operasi 64bit, hanya EViews 8 datang dalam versi 64bit. Hal ini juga harus dicatat bahwa Excel add-in yang dilengkapi dengan EViews 7 memiliki versi 32bit saja, dan dengan demikian tidak akan berjalan di bawah versi 64bit dari Excel.
EViews 9 Kompatibilitas Catatan Pembahasan berikut menjelaskan EViews masalah kompatibilitas 8 bagi pengguna versi sebelumnya. Workfile Kompatibilitas Dengan beberapa pengecualian, EViews 9 workfiles yang kompatibel dengan EViews 8. Perhatikan bahwa benda berikut ini baru atau telah dimodifikasi Versi 9: Persamaan objek diperkirakan dengan metode yang menggunakan fitur baru (ambang batas regresif sion, ARDL, ML ARMA , ARFIMA.) Jika Anda sudah menyimpan workfiles mengandung salah satu objek di atas dan membukanya di EViews 7 atau sebelumnya, EViews akan menghapus objek yang tidak kompatibel dan memberitahu Anda bahwa satu atau lebih objek yang tidak membaca. Jika Anda kemudian simpan Workfile, Anda akan kehilangan obyek. Kami menyarankan Anda membuat salinan dari setiap workfiles yang berisi benda-benda ini jika Anda ingin menggunakan workfiles ini dalam versi sebelumnya dari EViews. Sebaliknya, ada beberapa metode estimasi yang baru dalam EViews 9, tetapi tidak dianggap cukup kompatibel. Dalam hal ini, Anda dapat membuka Workfile di sion ver- tua, tetapi beberapa masalah kompatibilitas tetap. Misalnya, jika Anda memperkirakan persamaan kuadrat terkecil nonlinier menggunakan mesin baru optimasi dan metode (misalnya, BFGS), persamaan asli akan dibaca dalam versi EViews, tapi pilihan baru akan diabaikan dalam versi sebelumnya dari EViews. Jika Anda kemudian reestimate persamaan di EViews 8 estimasi akan mempekerjakan metode yang lebih tua. Catatan di TERTENTU-partai bahwa ini menyiratkan bahwa Anda dapat melakukan tes Wald di EViews 8 menggunakan metode koefisien kovarians yang tidak tersedia di EViews 8. Sebaiknya hati-hati dalam pencampuran hasil antara versi.
Sejarah SPSS
Latar Belakang
Dua tema telah mendominasi evolusi SPSS Inc. sebagai perusahaan:
Teknologi SPSS telah membuat tugas analitis sulit lebih mudah melalui kemajuan dalam kegunaan dan akses data, memungkinkan lebih banyak orang untuk mendapatkan keuntungan dari penggunaan teknik kuantitatif dalam pengambilan keputusan; dan
keahlian domain perusahaan telah berpusat pada analisis data tentang orang pendapat mereka, sikap, dan perilaku.
Misi Perusahaan untuk "mendorong meluasnya penggunaan data dalam pengambilan keputusan" berasal langsung dari dua tema ini. kesuksesan perusahaan telah didasarkan pada kemampuannya untuk menunjukkan manfaat yang sangat nyata bahwa penggunaan teknologi SPSS menyediakan. Mendasari kemampuan ini adalah keyakinan kolektif yang menganalisis data, dan menggabungkan hasilnya ke dalam proses pengambilan keputusan, mengarah ke keputusan yang lebih baik.
Asal-usul SPSS
Pada tahun 1968, Norman H. Nie, C. bin Hadlai (Tex) Hull dan Dale H. Bent, tiga orang muda dari latar belakang profesional yang berbeda, mengembangkan sistem perangkat lunak berdasarkan ide menggunakan statistik untuk mengubah data mentah menjadi informasi penting untuk para pengambil pembuatan. Ketiga inovator adalah perintis di bidang mereka, visioner yang diakui awal bahwa data dan bagaimana Anda menganalisis itu adalah kekuatan pendorong di belakang suara pengambilan keputusan-DNA kecerdasan.
sistem perangkat lunak statistik yang revolusioner ini disebut SPSS, yang berdiri untuk Paket statistik untuk Ilmu Sosial. Nie, Hull dan Bent dikembangkan SPSS dari kebutuhan untuk cepat menganalisis volume data ilmu sosial yang dikumpulkan melalui berbagai metode penelitian. Pekerjaan awal pada SPSS dilakukan di Stanford University dengan maksud untuk membuatnya tersedia hanya untuk konsumsi lokal dan tidak distribusi internasional. Nie, seorang ilmuwan sosial dan kandidat doktor Stanford, mewakili target audiens dan mengatur persyaratan; Bent, seorang kandidat doktor Universitas Stanford di riset operasi, memiliki keahlian analisis dan merancang struktur sistem file SPSS; dan Hull, yang baru saja lulus dari Stanford dengan gelar master administrasi bisnis, diprogram.
Seperti khas dari kreasi lahir dari kebutuhan, SPSS cepat tertangkap di universitas di seluruh Amerika dan segera permintaan. Hal ini juga menjadi jelas bagi para pengembang SPSS bahwa mereka memiliki lebih banyak di tangan mereka dari satu, metode yang efisien efektif menganalisis data; mereka memiliki produk yang layak. Selain karya akademis mereka, mereka sekarang perlu mempertimbangkan harga, pengiriman dan isu-isu lain perdagangan. Mereka memastikan bahwa kaset dari kode sumber dikirim ke komunitas pengguna yang kecil, tapi antusias, dan terus dipertahankan dan ditingkatkan SPSS.
Setelah lulus sekolah tahun 1969, Nie bergabung dengan Universitas Nasional Opini Research Center Chicago. The University of Chicago dianggap SPSS properti intelektual penting dan mendorong pembangunan berkelanjutan Nie untuk sistem perangkat lunak. Nie berhasil merekrut Hull untuk bergabung dengannya di University of Chicago dengan mendorong dia untuk mengambil posisi sebagai kepala universitas Perhitungan Center. Bent, Kanada, memutuskan untuk tidak bergabung Nie dan Hull di Chicago, dan kembali ke Kanada di mana ia punya janji akademik di University of Alberta. Dengan Nie dan Hull menyulap kedua mereka tanggung jawab akademik dan SPSS, mereka terus bekerja dengan tekun menyebarkan kata dan daya tarik pasar SPSS.
Keberhasilan awal SPSS langsung terkait dengan kualitas dan ketersediaan dokumentasi yang menyertai perangkat lunak. McGraw-Hill diterbitkan manual SPSS pengguna pertama pada tahun 1970. Setelah pengguna yang tersedia di toko buku perguruan tinggi, permintaan untuk program melepas. Nie, Bent, dan Hull menerima royalti dari penjualan manual tapi tidak ada dari distribusi program. Dengan kata Nie ini, "Rasanya seperti Gillette menjual pisau cukur dengan biaya dan mendapatkan keuntungan yang dari pisau."
Dengan penjualan SPSS berkembang pesat, IRS ditentukan pada tahun 1971 bahwa SPSS adalah sebuah perusahaan software kecil, yang mengancam status non-profit dari University of Chicago di mana SPSS telah ditampung. Pada tahun 1975, SPSS didirikan dan dua pendiri, Nie dan Hull, tak satu pun pernah bermimpi menjalankan bisnis mereka sendiri, menjadi eksekutif perusahaan baru. Meskipun tidak memiliki modal usaha atau dukungan finansial, dua pengusaha ini dijamin untuk SPSS control universal dari pasar akademik karena fakta bahwa SPSS adalah, dan, kode portabel yang memungkinkan lembaga-lembaga akademis port ke sebagian besar mainframe besar sistem komputer, yang termasuk data Control 6000 series, Burroughs sistem yang besar, Univac 1108, GE (selanjutnya Honeywell) sistem yang besar, Digital Equipment Corporation (DEC) sistem yang besar. SPSS juga cepat menjadi berguna untuk pasar pemerintah dan komersial. NASA mulai menggunakan SPSS untuk waktu yang berarti antara kegagalan bagian dari pesawat luar angkasa di pertengahan 1970-an, dan Dinas Kehutanan Nasional yang digunakan perangkat lunak untuk insiden cedera dan pertemuan beruang di seluruh Nati
Sejarah IBM SPSS Statistics
Sejarah Singkat IBM SPSS Statistics
SPSS, yang merupakan singkatan dari Statistical Package for Social Sciences, dikembangkan pada tahun 1968 oleh Norman H. Nie, C. bin Hadlai (Tex) Hull dan Dale H. Bent dalam menanggapi kebutuhan untuk perangkat lunak yang bisa mengubah data mentah menjadi informasi penting untuk pengambilan keputusan.
Meskipun SPSS pertama kali digunakan di lembaga-lembaga akademis di seluruh Amerika, dengan cepat tertangkap di antara pasar pemerintah dan komersial. Beberapa awal pengguna SPSS penting termasuk: NASA, Forest Reserve Nasional, Procter & Gamble dan Anheuser-Busch.
Sejak awal, SSPS tetap menjadi pemimpin pasar dalam analisis prediktif dan lebih luas usaha sektor intelijen dengan memperhatikan dekat dengan pelanggan "kebutuhan dan tetap mengikuti kemajuan teknologi.
Dalam empat dekade terakhir, SPSS telah berkembang menjadi sebuah perusahaan internasional yang memberikan alat-alat analisis dan solusi untuk beberapa organisasi di seluruh dunia. Sementara perusahaan dan industri menggunakan SPSS bervariasi, mereka al berbagi keinginan bersama untuk mengumpulkan wawasan melalui analisis data.
Keberhasilan terbukti SPSS terus menunjukkan manfaat yang sangat nyata dari menggunakan analisis data untuk mendorong proses pengambilan keputusan dan meningkatkan hasil bisnis.
perusahaan Timeline
Ada lima tahap pertumbuhan dalam sejarah kelembagaan SPSS:
1968-1975
"SPSS menjadi sebuah produk," ketika teknologi ini pertama kali dikembangkan dan tumbuh sendiri sebagai perusahaan akademik. SPSS pendiri, Norman H. Nie, C. bin Hadlai (Tex) Hull dan Dale H. Bent, mendistribusikan kaset kode sumber untuk komunitas pengguna yang kecil, tapi antusias, sedangkan pemeliharaan dan peningkatan dilakukan oleh penulis asli.
1975-1984
"SPSS menjadi sebuah perusahaan." Perusahaan secara terpisah dimasukkan ketika pendapatan mengancam status non-profit lembaga hosting yang aslinya, Pusat Penelitian Opini Nasional di Universitas Chicago. Selama fase start-up ini, bisnis ini diselenggarakan dan sejumlah inisiatif pembangunan yang dilakukan.
1984-1992
"Usia PC," dengan Perusahaan tumbuh dari $ 18m ke $ 38m pada kekuatan yang memimpin pasar sistem analisis statistik untuk PC DOS. SPSS adalah yang pertama ke pasar dengan produk software statistik pada PC DOS.
1992-1996
"Usia Windows," dengan Perusahaan pengiriman versi Windows pertama dari paket software statistik pada tahun 1992. Versi ini melaju pendapatan menjadi $ 84m dengan tahun 1996. Bisnis ini difokuskan pada produk statistik, dan strategi akuisisi dilengkapi arah ini dengan membawa dalam produk statistik perusahaan lain, seperti SYSTAT (1994) dan Jandel (1996).
1997-2002
"Transisi ke perusahaan." Periode ini telah usia pertumbuhan dengan akuisisi dan munculnya aplikasi analitik sebagai pelengkap bisnis inti produk statistik. Perusahaan tumbuh dari $ 110m pada tahun 1997 untuk diproyeksikan $ 209m pada tahun 2002 melalui akuisisi dari Quantime (pasar perangkat lunak aplikasi penelitian), ISL (software data mining), Showcase (intelijen bisnis perangkat lunak untuk pasar menengah), NetGenesis (aplikasi analitis untuk Data web), LexiQuest (teks perangkat lunak pertambangan), dan netExs (antarmuka web untuk teknologi OLAP).
2003
analisis prediktif berhasil didirikan sebagai segmen pasar. SPSS memainkan peran pemikiran-kepemimpinan dalam munculnya selama 2003 dari analisis prediktif sebagai penting, segmen yang berbeda dalam sektor perangkat lunak bisnis intelijen yang lebih luas. analisis prediktif melengkapi dan meningkatkan teknologi informasi lainnya. Organisasi yang mempekerjakan analisis prediktif tidak hanya tahu apa yang telah terjadi, mereka juga tahu apa yang mungkin terjadi selanjutnya. Yang paling penting, mereka tahu apa yang harus dilakukan tentang hal itu dengan menggunakan pengetahuan ini untuk meningkatkan pendapatan, mengurangi biaya, dan meningkatkan hasil. SPSS melihat tumbuh kesadaran dari manfaat ini antara komersial, sektor publik, dan organisasi akademis servis nya. Untuk meningkatkan fokus pada analisis prediktif, SPSS diakuisisi DataDistilleries berbasis di Belanda, penyedia aplikasi analitik prediktif pada bulan November 2003.
2004
aplikasi analitik prediktif datang usia. Pada tahun 2004, SPSS mempercepat pengenalan aplikasi analisis prediktif, memanfaatkan keterampilan dan mengintegrasikan teknologi dari akuisisi baru-baru, termasuk DataDistilleries. Sebuah versi baru dari prediksi Pemasaran diperkenalkan, serta aplikasi baru, Predictive Call Center. pekerjaan pembangunan tambahan mengatur panggung untuk lebih aplikasi yang akan diperkenalkan pada tahun 2005.
Hari ini
SPSS diakui sebagai pemimpin dalam ruang pasar analisis prediktif. analisis prediktif, yang menggabungkan analisis canggih dan optimasi keputusan, akan terus menjadi fokus bagi organisasi karena berusaha untuk meningkatkan pemahaman pasar manfaat bisnis yang analisis prediktif menyediakan.
modul
IBM SPSS Statistics adalah modular, terintegrasi, lini produk dengan fitur lengkap untuk proses-perencanaan analitis, pengumpulan data, akses data,
keywords: olah data spss statistik